




PRÉVALENCE DE LA SOUS-ALIMENTATION
Définition
La sous-alimentation est définie comme étant la situation dans laquelle la consommation alimentaire habituelle d’un individu est insuffisante pour fournir, en moyenne, l’apport énergétique alimentaire nécessaire à une vie normale, active et saine.
Indicateur
L’indicateur, appelé «prévalence de la sous-alimentation» (PoU, prevalence of undernourishment), est une estimation du pourcentage de personnes dans la population qui sont en situation de sous-alimentation. Les estimations nationales sont présentées sous forme de moyennes mobiles sur trois ans pour tenir compte du manque de fiabilité des estimations de certains paramètres sous-jacents, en raison d’éléments pour lesquels il est très rare qu’on dispose d’informations complètes et fiables, tels que la variation des stocks de produits alimentaires d’une année sur l’autre, l’une des composantes des bilans alimentaires annuels de la FAO. Les agrégats régionaux et mondiaux, quant à eux, sont présentés sous forme d’estimations annuelles, car on considère qu’il n’y a pas de corrélation entre les éventuelles erreurs d’estimation et que ces erreurs sont donc ramenées à des niveaux acceptables lorsqu’on agrège les données de plusieurs pays.
La série entière des données sur la PoU est révisée pour chaque nouvelle édition de ce rapport, à la lumière des données et des informations reçues par la FAO depuis l’édition précédente. Comme ce processus entraîne généralement une révision à rebours de la série entière, il est conseillé aux lecteurs de ne pas comparer les chiffres d’une édition sur l’autre et de se reporter systématiquement à l’édition la plus récente, y compris pour les chiffres des années précédentes.
Méthode
Pour estimer la prévalence de la sous-alimentation dans une population, on modélise la loi de distribution de probabilité de l’apport énergétique alimentaire habituel, exprimé en kilocalories par personne et par jour pour un individu moyen, sous la forme d’une fonction de densité de probabilité paramétrique, f(x)1, 2. On obtient ensuite l’indicateur en calculant la probabilité cumulée que l’apport énergétique alimentaire habituel (x) soit inférieur aux besoins énergétiques alimentaires minimaux (MDER, minimum dietary energy requirement) (limite inférieure de la fourchette des besoins énergétiques appropriée pour un individu moyen représentatif), comme dans la formule ci-après:
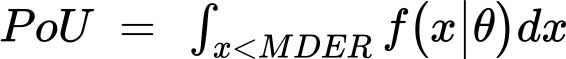
où θ est un vecteur de paramètres caractérisant la fonction de densité de probabilité. Dans les calculs réels, on part du principe que la distribution est log-normale, et donc totalement caractérisée par deux paramètres seulement: la consommation d’énergie alimentaire (DEC, Dietary energy consumption) moyenne et son coefficient de variation (CV).
Sources de données
Différentes sources de données sont utilisées pour estimer les paramètres du modèle.
Besoins énergétiques alimentaires minimaux
Pour déterminer les besoins énergétiques d’une personne appartenant à une classe d’âge/un sexe donné(e), on multiplie les besoins normalisés associés au taux métabolique de base (exprimés par kilogramme de poids corporel) par le poids idéal d’une personne en bonne santé de ce sexe/cette classe d’âge (compte tenu de sa taille); on multiplie ensuite la valeur obtenue par un coefficient correspondant au niveau d’activité physique (NAP) afin de prendre en compte cette dernièrebb. Étant donné que l’indice de masse corporelle (IMC) et le NAP normal varient chez les personnes actives et en bonne santé de même sexe et de même âge, on obtient une fourchette de besoins énergétiques pour chaque tranche d’âge de la population et chaque sexe. Les MDER d’un individu moyen dans la population – paramètre utilisé dans la formule de la PoU – correspondent à la moyenne pondérée des valeurs minimales des fourchettes de besoins énergétiques pour chaque tranche d’âge et sexe, la part de la population représentée par chaque groupe tenant lieu de coefficient de pondération. Comme pour les MDER, on estime les besoins énergétiques alimentaires moyens (ADER, average dietary energy requirement) (utilisés pour estimer la composante du CV décrite ci-dessous) à partir des valeurs moyennes de la catégorie de NAP «Mode de vie actif ou relativement actif»3.
Des informations sur la structure de la population par sexe et par âge nécessaires pour calculer les MDER sont disponibles pour la plupart des pays et pour chaque année dans le rapport du Département des affaires économiques et sociales de l’ONU intitulé World Population Prospects (Perspectives de la population mondiale), qui est révisé tous les deux ans. La présente édition de L’État de la sécurité alimentaire et de la nutrition dans le monde utilise la version 2024 du rapport World Population Prospects4.
Les informations relatives à la taille médiane des populations de chaque tranche d’âge et de chaque sexe par pays sont tirées d’une enquête démographique et sanitaire (EDS) récente ou d’autres enquêtes qui permettent de collecter des données anthropométriques sur les enfants et les adultes. Même si ces enquêtes ne se rapportent pas à la même année que celle pour laquelle on estime la PoU, les changements possibles d’une année à l’autre dans les statures médianes sont peu importants, et leur incidence sur les MDER et, de ce fait, sur les estimations de la PoU est donc considérée comme négligeable.
Consommation d’énergie alimentaire
L’idéal serait de pouvoir estimer la DEC à partir de données sur la consommation alimentaire issues d’enquêtes sur les ménages représentatives au niveau national (études sur la mesure des niveaux de vie [LSMS], ou enquêtes sur la consommation et les dépenses des ménages, par exemple). Cependant, très peu de pays réalisent ce type d’enquêtes chaque année. De ce fait, dans les estimations de la PoU calculées par la FAO aux fins du suivi mondial, les valeurs de DEC sont estimées à partir des disponibilités énergétiques alimentaires (DES) communiquées dans les bilans alimentaires établis par la FAO pour la plupart des pays5.
Depuis la dernière édition du présent rapport, le domaine de FAOSTAT consacré aux bilans alimentaires a été mis à jour afin d’inclure les nouvelles valeurs des séries jusqu’en 2022 pour l’ensemble des pays. De plus, au moment où s’achevait la rédaction du présent rapport, les séries de bilans alimentaires étaient actualisées jusqu’en 2023 pour les 72 pays suivants, sélectionnés en priorité en raison de la forte proportion qu’ils représentent au sein de la population sous-alimentée à l’échelle mondiale: Afghanistan, Afrique du Sud, Albanie, Angola, Arabie saoudite, Argentine, Bangladesh, Bénin, Bolivie (État plurinational de), Brésil, Burkina Faso, Cameroun, Colombie, Congo, Cuba, Côte d’Ivoire, Égypte, Équateur, Éthiopie, Ghana, Guatemala, Guinée, Guinée-Bissau, Haïti, Honduras, Inde, Indonésie, Iran (République islamique d’), Iraq, Japon, Jordanie, Kenya, Lesotho, Libéria, Libye, Madagascar, Malaisie, Malawi, Mali, Maroc, Mozambique, Myanmar, Népal, Nicaragua, Niger, Nigéria, Ouganda, Pakistan, Papouasie-Nouvelle-Guinée, Pérou, Philippines, République arabe syrienne, République centrafricaine, République démocratique du Congo, République populaire démocratique de Corée, République-Unie de Tanzanie, Rwanda, Sénégal, Sierra Leone, Somalie, Soudan, Soudan du Sud, Sri Lanka, Tchad, Thaïlande, Togo, Tunisie, Ukraine, Viet Nam, Yémen, Zambie et Zimbabwe.
Les DES moyennes par habitant pour 2023 (pour les pays autres que ceux énumérés ci-dessus) et pour 2024 (pour tous les pays) sont des prévisions immédiates réalisées à partir des perspectives à court terme des marchés établies par la FAO et publiées sur le Portail de la situation alimentaire mondiale6, et sont utilisées pour calculer les valeurs de DEC de chaque pays pour 2023 et 2024.
Facteurs de gaspillage
Pour la présente édition du rapport, nous avons notamment actualisé les facteurs de gaspillage qui sont utilisés pour calculer la DEC en soustrayant le pourcentage de gaspillage des DES pour tous les pays. Les pourcentages de gaspillage alimentaire au niveau de la distribution ont été estimés à l’aide des données des bilans alimentaires disponibles sur FAOSTAT.
À partir des pourcentages indiqués dans le document de la FAO intitulé Pertes et gaspillages alimentaires dans le monde7, on calcule et on additionne les pertes de calories dues au gaspillage pour chaque groupe d’aliments, sauf les céréales, pour lesquelles les facteurs de gaspillage utilisés sont de 2 pour cent pour toutes les régions. Enfin, on considère les pertes totales de calories en pourcentage des calories totales pour chaque année et chaque pays. Les données sont disponibles jusqu’à l’année 2022. Pour 2023 et 2024, les valeurs utilisées sont celles de l’année 2022.
Coefficient de variation
On obtient le coefficient de variation de la DEC habituelle dans la population en calculant la moyenne géométrique de deux composantes, appelées CV|y et CV|r:
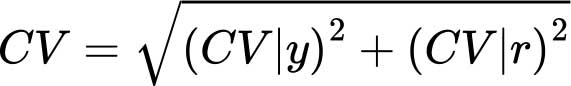
La première (CV|y) désigne la variabilité de la consommation par habitant chez les ménages appartenant à différentes couches sociodémographiques, elle est donc appelée «coefficient de variation imputable aux revenus», tandis que la seconde (CV|r) rend compte de la variabilité liée au sexe, à l’âge, à la masse corporelle et au NAP des membres d’un même ménage. Étant donné que ce sont les mêmes éléments qui déterminent les besoins énergétiques, la seconde composante est appelée «coefficient de variation imputable aux besoins».
CV|y
Lorsqu’on dispose de données fiables sur la consommation alimentaire issues d’enquêtes sur les ménages représentatives au niveau national, on peut estimer directement le coefficient de variation imputable aux revenus. Depuis la dernière édition de ce rapport, 25 nouvelles enquêtes réalisées dans les 14 pays suivants ont été traitées aux fins d’actualisation du CV|y: Bénin (2022), Burkina Faso (2022), Cambodge (2021 et 2023), Géorgie (2022 et 2023), Guinée-Bissau (2022), Inde (2022 et 2024), Jordanie (2022), Kazakhstan (2021 et 2023), Mongolie (2022 et 2023), Myanmar (2015), Pérou (2023), Somalie (2022), Thaïlande (2016, 2017, 2018, 2019, 2020, 2021 et 2023) et Togo (2022). Le CV|y repose donc désormais sur les données issues de 169 enquêtes menées dans 71 pays.
Lorsqu’on ne dispose pas de données d’enquête appropriées, on a recours aux données collectées par la FAO depuis 2014 au moyen de l’échelle de mesure de l’insécurité alimentaire vécue (FIES) pour établir une projection des variations du CV|y à partir de 2017 (ou à partir de l’année de la dernière enquête de consommation alimentaire réalisée, si elle est postérieure) et jusqu’à 2024, en se basant sur l’évolution observée de l’insécurité alimentaire grave. Les projections sont fondées sur l’hypothèse que cette évolution mesurée au moyen des données FIES pourrait indiquer des variations équivalentes de la prévalence de la sous-alimentation. Si tant est qu’elles ne puissent pas s’expliquer totalement par les effets de changements liés à l’offre dans les approvisionnements alimentaires moyens, on peut raisonnablement attribuer ces variations de la PoU à une évolution non observée du CV|y qui se serait produite dans le même temps. L’analyse des estimations passées de la PoU montre qu’en moyenne, après neutralisation des différences liées à la DEC, aux MDER et au CV|r, l’évolution du CV|y explique un tiers environ des écarts de PoU dans le temps et dans l’espace. À partir de tous ces éléments, pour chaque pays pour lequel on dispose de données FIES, l’évolution du CV|y qui a pu se produire depuis 2017, ou depuis la date de la dernière enquête disponible, est donc estimée comme étant l’évolution susceptible d’entraîner une variation d’un tiers de point de pourcentage de la PoU pour chaque point de pourcentage de variation observé dans la prévalence de l’insécurité alimentaire grave. Pour tous les autres pays, faute de données probantes, on conserve la dernière estimation disponible du CV|y. Comme dans les quatre éditions précédentes du rapport, la prévision immédiate du CV|y pour 2020, 2021, 2022, 2023 et 2024 a nécessité un traitement spécial pour tenir compte des effets de la pandémie de covid-19 (voir le supplément au chapitre 2).
CV|r
Le coefficient de variation imputable aux besoins reflète la variabilité de la distribution des besoins énergétiques alimentaires d’un individu moyen hypothétique représentatif d’une population en bonne santé, et correspond également au CV|y de la distribution des apports énergétiques alimentaires d’un individu moyen dans une situation hypothétique où toute la population serait parfaitement bien nourrie. Aux fins d’estimation, la distribution des besoins énergétiques alimentaires d’un individu moyen hypothétique est supposée normale, et l’écart type correspondant peut être estimé à partir de deux centiles connus. Les MDER et les ADER mentionnés précédemment sont utilisés pour obtenir une approximation du 1er centile et du 50e centile8, 9. La valeur du CV|r est donc dérivée sous la forme d’une distribution normale type cumulative inverse de la différence entre les MDER et les ADER.
Problèmes et limites
La sous-alimentation est normalement un état individuel, mais, étant donné qu’on dispose généralement de données à grande échelle, il est impossible de déterminer de manière fiable les individus qui, au sein d’un groupe spécifique, sont effectivement sous-alimentés. Avec le modèle statistique décrit plus haut, l’indicateur ne peut être calculé qu’en référence à une population ou à un groupe d’individus pour laquelle/lequel on dispose d’un échantillon suffisamment représentatif. La PoU est donc une estimation du pourcentage d’individus du groupe considéré qui sont sous-alimentés, mais elle ne peut pas être décomposée plus finement.
Compte tenu de la nature probabiliste de l’inférence et des marges d’incertitude associées aux estimations de chacun des paramètres du modèle, la précision des estimations de la PoU est généralement faible. Il n’est pas possible de calculer formellement les marges d’erreur associées aux estimations de la PoU, mais il est probable qu’elles soient supérieures à 5 pour cent dans la plupart des cas. C’est pourquoi la FAO considère que les estimations de la PoU qui sont inférieures à 2,5 pour cent ne sont pas suffisamment fiables pour figurer dans les rapports.
Il est important de noter que les limites supérieure et inférieure des estimations ponctuelles de la PoU de 2020 à 2024 ne doivent pas être interprétées comme des intervalles de confiance statistiques; elles représentent plutôt des scénarios différents utilisés pour établir des prévisions immédiates des valeurs de CV|y, la marge d’incertitude associée aux facteurs de gaspillage de 2020 à 2024, et les marges d’incertitude associées aux prévisions immédiates des DES pour 2023 et 2024 (voir le supplément au chapitre 2).
Lectures recommandées
Cafiero, C. 2014. Advances in hunger measurement: traditional FAO methods and recent innovations. Document de travail de la Division de la statistique de la FAO no 14-04. Rome, FAO. https://openknowledge.fao.org/handle/20.500.14283/i4060e
FAO. 1996. Methodology for assessing food inadequacy in developing countries. Dans: The Sixth World Food Survey, p. 114-143. Rome. https://www.fao.org/4/w0931e/w0931e16.pdf
FAO. 2003. Sommaire des débats: Mesure et évaluation des pénuries alimentaires et de la dénutrition. Colloque scientifique international, 26-28 juin 2002. Rome. https://www.fao.org/4/y4250e/y4250e00.pdf
FAO. 2025. Mesurer la faim, la sécurité alimentaire et la consommation alimentaire. Dans: FAO. [Consulté le 25 juin 2025]. https://www.fao.org/measuring-hunger/fr
Naiken, L. 2002. Keynote paper: FAO methodology for estimating the prevalence of undernourishment. Rome, FAO. https://www.fao.org/4/y4249e/y4249e06.htm
Wanner, N., Cafiero, C., Troubat, N. et Conforti, P. 2014. Refinements to the FAO methodology for estimating the prevalence of undernourishment indicator. Document de travail de la Division de la statistique de la FAO no 14-05. Rome, FAO. https://openknowledge.fao.org/handle/20.500.14283/i4046e
PRÉVALENCE DE L’INSÉCURITÉ ALIMENTAIRE ÉVALUÉE À L’AIDE DE L’ÉCHELLE FIES
Définition
L’insécurité alimentaire, telle qu’elle est mesurée par cet indicateur, fait référence à un accès à la nourriture limité, au niveau des individus ou des ménages, en raison d’un manque de ressources financières ou d’autres ressources. La gravité de l’insécurité alimentaire est mesurée à l’aide des données collectées grâce au module d’enquête FIES, un ensemble de huit questions qui permettent aux individus ou aux ménages interrogés de déclarer des situations ou des expériences généralement associées à un accès limité à la nourriture. Aux fins du suivi annuel des ODD, les questions sont posées en référence aux 12 mois précédant l’enquête.
Des techniques statistiques sophistiquées fondées sur le modèle de Rasch permettent de valider les informations obtenues dans le cadre du module d’enquête FIES, aux fins de cohérence interne, et de les convertir en une mesure quantitative sur une échelle de gravité (de faible à élevée). Selon leurs réponses aux différentes questions de l’enquête, les individus ou les ménages interrogés dans le cadre d’une enquête représentative de la population au niveau national se voient associer une probabilité d’appartenir à l’une des trois classes suivantes, définies au moyen de deux seuils fixés à l’échelle internationale: i) en situation de sécurité alimentaire ou d’insécurité alimentaire marginale; ii) en situation d’insécurité alimentaire modérée; iii) en situation d’insécurité alimentaire grave. À partir des données FIES collectées sur trois ans (de 2014 à 2016), la FAO a défini l’échelle de référence FIES, qui est utilisée comme norme mondiale pour les mesures de l’insécurité alimentaire vécue ainsi que pour la fixation des deux seuils de gravité de référence.
L’indicateur 2.1.2 des ODD est obtenu en calculant la somme des probabilités de se trouver dans les classes correspondant à l’insécurité alimentaire modérée et à l’insécurité alimentaire grave. Un indicateur distinct (FIsev) est calculé en référence à la classe d’insécurité alimentaire grave uniquement.
Indicateur
Dans le présent rapport, la FAO fournit des informations relatives à deux niveaux d’insécurité alimentaire: l’insécurité alimentaire modérée ou grave (FImod+sev) et l’insécurité alimentaire grave (FIsev). Deux estimations sont données pour chacun de ces niveaux:
- le pourcentage des individus (prévalence) dans la population qui vivent dans un ménage où l’on a constaté qu’au moins un adulte était en situation d’insécurité alimentaire;
- le nombre des individus dans la population qui vivent dans un ménage où l’on a constaté qu’au moins un adulte était en situation d’insécurité alimentaire.
Sources de données
Depuis 2014, on utilise le module d’enquête FIES, qui comporte huit questions, pour recueillir des données sur des échantillons nationalement représentatifs de la population adulte (à savoir les individus âgés de 15 ans et plus) dans plus de 140 pays pris en compte dans le sondage mondial de Gallup©, qui couvre plus de 90 pour cent de la population mondiale. En 2024, les entretiens se sont déroulés par téléphone et en face à face. Les entretiens téléphoniques ont été maintenus dans certains pays pour lesquels cette méthode avait déjà été employée en 2020 compte tenu du risque élevé de contamination des communautés qu’aurait entraîné la collecte de données en présentiel pendant la pandémie de covid-19.
Gallup© a généralement recours à des enquêtes par téléphone en Amérique du Nord, en Europe de l’Ouest, dans certaines régions d’Asie et dans les pays membres du Conseil de coopération des États arabes du Golfe. En Europe centrale, en Europe de l’Est, dans une grande partie de l’Amérique latine, dans la quasi-totalité de l’Asie, au Proche-Orient et en Afrique, un plan d’échantillonnage aréolaire a été utilisé pour les entretiens en face à face.
Dans la plupart des pays, les échantillons comptent un millier d’individus environ, mais ils sont plus importants en Chine continentale (3 500 personnes), en Inde (3 000 personnes) et en Fédération de Russie (2 000 personnes). Aucune donnée n’a été collectée en Chine (continentale) en 2024.
On a utilisé les données issues d’enquêtes publiques nationales pour estimer la prévalence de l’insécurité alimentaire dans 82 pays qui comptent plus d’un tiers de la population mondiale, en appliquant les méthodes statistiques de la FAO aux fins de validation interne et de façon à ajuster les résultats nationaux sur la même norme de référence mondiale. Une fois validées, les données sont utilisées pour peupler ou actualiser les séries nationales (voir la description ci-après). Lorsque la population d’un pays représente une large proportion de celle de la région, cette opération peut entraîner la révision (y compris à rebours) de la série régionale ou sous-régionale. C’est pourquoi nous invitons le lecteur à ne pas comparer les chiffres entre les différentes éditions du rapport, et à considérer l’édition actuelle comme la référence.
Pour la présente édition du rapport, on a utilisé les données provenant d’enquêtes publiques nationales réalisées dans les 82 pays et territoires suivants: Afghanistan, Afrique du Sud, Angola, Antigua-et-Barbuda, Arménie, Bélarus, Belize, Bénin, Botswana, Brésil, Burkina Faso, Burundi, Cabo Verde, Cameroun, Canada, Chili, Chypre, Colombie, Costa Rica, Côte d’Ivoire, Émirats arabes unis, Équateur, Eswatini, États-Unis d’Amérique, Fédération de Russie, Fidji, Ghana, Grèce, Grenade, Guinée-Bissau, Guyana, Honduras, Indonésie, Israël, Italie, Kazakhstan, Kenya, Kirghizistan, Kiribati, Lesotho, Malawi, Mali, Mauritanie, Mexique, Mongolie, Mozambique, Namibie, Nauru, Niger, Nigéria, Ouganda, Pakistan, Palaos, Palestine, Papouasie-Nouvelle-Guinée, Paraguay, Philippines, République centrafricaine, République de Corée, République dominicaine, République-Unie de Tanzanie, Sainte-Lucie, Saint-Kitts-et-Nevis, Saint-Vincent-et-les Grenadines, Samoa, Sénégal, Seychelles, Sierra Leone, Soudan, Soudan du Sud, Sri Lanka, Tchad, Thaïlande, Timor-Leste, Togo, Tonga, Trinité-et-Tobago, Uruguay, Vanuatu, Viet Nam, Yémen et Zambie. Les données nationales de ces pays sont prises en compte pour l’année/les années pour laquelle/lesquelles elles sont disponibles. Pour les autres années, on a appliqué la stratégie suivante:
- Lorsque des données nationales sont disponibles pour plusieurs années, les valeurs des années manquantes sont calculées par interpolation linéaire.
- Lorsque des données nationales sont disponibles pour une seule année, les valeurs des années manquantes sont:
- –établies à l’aide de données de la FAO si ces données sont considérées comme étant compatibles avec les enquêtes nationales;
- –imputées en fonction de la tendance suggérée par les données de la FAO en cas d’incompatibilité avec les données nationales;
- –imputées en fonction de la tendance sous-régionale si aucune autre information fiable n’est disponible en temps voulu;
- –considérées comme suivant une tendance constante par rapport au niveau établi dans le cadre de l’enquête nationale si la tendance sous-régionale ne peut pas être calculée ou si la tendance qui ressort d’autres enquêtes ou la tendance sous-régionale n’est pas applicable à la situation particulière du pays en question compte tenu des éléments probants qui ont été réunis à l’appui de la tendance (évolution de la pauvreté, de la pauvreté extrême, de l’emploi et de l’inflation des prix des aliments, entre autres); cela s’applique aussi aux pays où la prévalence de l’insécurité alimentaire est très basse (moins de 3 pour cent pour l’insécurité alimentaire grave) ou très élevée (plus de 85 pour cent pour l’insécurité alimentaire modérée ou grave).
Compte tenu de l’hétérogénéité des sources utilisées lors des enquêtes et de la petite taille de l’échantillon de certaines enquêtes de la FAO, les nouvelles données peuvent parfois déboucher sur une forte augmentation ou diminution d’une année sur l’autre. Dans ce cas, la règle est de rechercher des informations concernant le pays qui sont issues de sources extérieures (données ou rapports, le cas échéant en concertation avec des experts du pays tels que les fonctionnaires nationaux et régionaux de la FAO) afin de déterminer si des bouleversements importants ou des interventions de grande ampleur ont eu lieu. Si la tendance peut être confirmée par des données probantes, mais semble excessive, elle est conservée mais lissée (en utilisant la moyenne sur trois ans, par exemple). Sinon, la même règle que celle utilisée pour les années manquantes est appliquée (en maintenant le niveau constant ou en appliquant la tendance sous-régionale). En 2024, aucune donnée FIES n’a été collectée en Chine (continentale), et la tendance a donc été maintenue constante.
Méthode
Les données ont été validées et utilisées pour établir une échelle de gravité de l’insécurité alimentaire selon le modèle de Rasch, qui postule que la probabilité d’obtenir une réponse affirmative de la personne interrogée i à la question j est une fonction logistique de la distance, sur une échelle de gravité sous-jacente, entre la position de la personne interrogée, ai, et celle de l’item, bj.
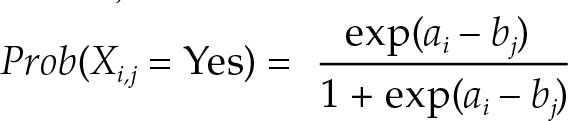
En appliquant le modèle de Rasch aux données FIES, on peut estimer pour chaque personne interrogée i la probabilité (comparable d’un pays à l’autre) qu’elle soit en situation d’insécurité alimentaire (pi,L), à chaque niveau L de gravité (modérée ou grave, ou grave uniquement) de cette situation, avec 0 < pi,L < 1.
La prévalence de l’insécurité alimentaire à chaque niveau de gravité (FIL) dans la population correspond à la somme pondérée de la probabilité d’être en situation d’insécurité alimentaire pour toutes les personnes interrogées (i) d’un échantillon:
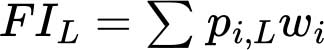
où wi correspond à la pondération poststratification appliquée à l’échantillon qui indique la proportion d’individus ou de ménages dans la population nationale représentée par chaque enregistrement de l’échantillon.
Étant donné que seules les personnes âgées de 15 ans ou plus sont échantillonnées dans le sondage mondial de Gallup©, les estimations de prévalence produites directement à partir des données de ce sondage portent sur la population située dans cette tranche d’âge. Pour obtenir la prévalence et le nombre d’individus (de tous les âges) dans la population, il faut estimer le nombre de personnes qui vivent dans un ménage où au moins un adulte est considéré comme étant en situation d’insécurité alimentaire. À cet effet, on utilise la procédure par étapes expliquée à l’annexe 1B du document intitulé Méthodes d’estimation de taux comparables de prévalence de l’insécurité alimentaire chez les adultes à l’échelle mondiale (voir le lien fourni à la section «Lectures recommandées» ci-après).
Les valeurs agrégées régionales et mondiales de l’insécurité alimentaire de niveau modéré ou grave et de niveau grave, FIL,r, sont calculées comme suit:
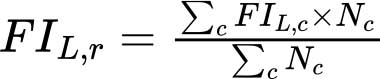
où r indique la région, FIL,c est la valeur de FI de niveau L estimée pour le pays c dans la région, et Nc, la taille de la population correspondante. En l’absence d’estimation de FIL pour un pays, on considère que cette valeur est égale à la moyenne, pondérée par la population, des valeurs estimatives pour les pays restants de la même sous-région. L’agrégat régional est calculé uniquement si les pays pour lesquels une estimation est disponible représentent au moins 50 pour cent de la population de la région.
Des seuils universels sont définis sur l’échelle FIES internationale de référence (une série de valeurs de paramètres d’items calculées à partir des résultats de tous les pays visés par le sondage mondial de Gallup© en 2014-2016) et convertis dans les valeurs correspondantes sur les échelles locales. Le processus d’étalonnage de l’échelle de chaque pays au regard de l’échelle FIES internationale de référence peut être présenté comme une mise en correspondance qui permet de produire des mesures comparables à l’échelle internationale de la gravité de l’insécurité alimentaire des personnes interrogées, ainsi que des taux de prévalence nationaux comparables.
Le problème vient du fait que, lorsqu’elle est définie comme un trait latent, la gravité de l’insécurité alimentaire ne peut pas être évaluée par rapport à une référence absolue. Le modèle de Rasch permet de déterminer la position relative occupée par les différents items sur une échelle libellée en unités logit, mais dont le «zéro» est défini arbitrairement (comme étant la gravité moyenne estimée, généralement). Cela signifie que le zéro de l’échelle change dans chaque cas. Pour produire des mesures comparables dans le temps et entre différentes populations, il faut définir une échelle commune qui sera utilisée comme référence, et trouver la formule nécessaire pour convertir les mesures entre les différentes échelles. Comme lorsqu’on convertit des mesures de température effectuées selon des échelles différentes (Celsius et Fahrenheit, par exemple), il faut déterminer des points d’«ancrage». Dans la méthode FIES, ces points d’ancrage sont les niveaux de gravité associés aux items dont la position relative sur l’échelle de gravité peut être considérée comme égale à celle des items correspondants sur l’échelle de référence internationale. Ensuite, pour «mettre en correspondance» les mesures établies selon les différentes échelles, on détermine la formule pour laquelle la moyenne et les écarts types des niveaux de gravité des items communs sont égaux.
Problèmes et limites
Lorsque les estimations de prévalence de l’insécurité alimentaire reposent sur les données FIES recueillies dans le cadre du sondage mondial de Gallup©, avec des échantillons nationaux d’un millier de personnes environ dans la plupart des pays, les intervalles de confiance dépassent rarement 20 pour cent de la prévalence mesurée (ce qui signifie que des taux de prévalence de 50 pour cent sont associés à des marges d’erreur pouvant aller jusqu’à plus ou moins 5 pour cent). Les intervalles de confiance sont toutefois beaucoup plus petits si les taux de prévalence nationaux sont estimés à partir d’échantillons plus importants ou s’il s’agit d’estimations portant sur des agrégats de plusieurs pays. Afin de réduire l’effet de la variabilité de l’échantillonnage d’une année sur l’autre, on présente les estimations nationales sous forme de moyennes sur trois ans, calculées en faisant la moyenne de toutes les années disponibles pour les périodes triennales considérées.
Les enquêtes publiques nationales constituent la source privilégiée pour l’établissement des estimations de l’insécurité alimentaire fondées sur les données FIES. Cependant, elles peuvent ne pas être disponibles tous les ans, ou les données peuvent être mises à la disposition de la FAO plusieurs années après. En l’absence d’enquêtes nationales annuelles, les séries chronologiques sont établies à l’aide de la méthode décrite plus haut (voir «Sources de données»). Nous pouvons ainsi être amenés à réaliser une révision à rebours des données de la série.
Lectures recommandées
Cafiero, C., Viviani, S. et Nord, M. 2018. Food security measurement in a global context: The food insecurity experience scale. Measurement, 116: 146-152. https://www.sciencedirect.com/science/article/pii/S0263224117307005
FAO. 2016. Méthodes d’estimation de taux comparables de prévalence de l’insécurité alimentaire chez les adultes à l’échelle mondiale. Rome. https://openknowledge.fao.org/handle/20.500.14283/i4830f
FAO. 2025. Mesurer la faim, la sécurité alimentaire et la consommation alimentaire. Dans: FAO. [Consulté le 25 juin 2025]. https://www.fao.org/measuring-hunger/fr
COÛT D’UNE ALIMENTATION SAINE
Définition
Le coût d’une alimentation saine correspond au coût d’achat des articles les moins chers disponibles dans chaque pays qui peuvent composer une alimentation satisfaisant aux recommandations nutritionnelles fondées sur le choix des aliments et aux besoins énergétiques d’une personne représentative, sur la base d’une consommation définie à 2 330 kilocalories par jour assurant l’équilibre énergétique.
Indicateur
L’indicateur (appelé «coût d’une alimentation saine» [CoHD]) est une estimation du montant minimal moyen qu’une personne doit dépenser dans un pays pour acheter les articles les moins chers, disponibles localement, qui lui sont nécessaires pour avoir une alimentation saine. Pour permettre les comparaisons entre pays, le coût d’une alimentation saine exprimé en unités monétaires locales est converti en dollars internationaux au moyen des taux de change exprimés en PPA relatifs à la consommation privée. L’indicateur CoHD est de ce fait présenté sous la forme d’un montant moyen en USD en PPA par personne et par jour.
Sources de données
Les prix des articles associés à chacun des groupes d’aliments entrant dans une alimentation saine proviennent du Programme de comparaison internationale, coordonné par la Banque mondiale, qui fournit des estimations de PPA établies à partir d’un ensemble d’articles normalisés au niveau international exprimés en unités monétaires locales10. Aux fins de comparaison entre pays, les prix en unités monétaires locales sont convertis en dollars internationaux au moyen des facteurs de conversion en PPA relatifs à la consommation privée calculés par le Groupe de gestion des données sur le développement de la Banque mondiale et publiés dans la base de données des indicateurs du développement dans le monde11. Pour actualiser le coût d’une alimentation saine pour les années séparant les cycles du Programme de comparaison internationale, on utilise les données des IPC (indices généraux des prix à la consommation et indices des prix à la consommation des produits alimentaires) publiées par la FAO12.
Méthode
Méthode utilisée pour définir un panier alimentaire sain
Étant donné que les aliments sélectionnés dans le cadre d’un assortiment sain varient selon les conditions locales, les pays ont élaboré des recommandations nutritionnelles fondées sur le choix des aliments pour préconiser des habitudes alimentaires saines correspondant au contexte culturel et aux aliments disponibles localement. Cependant, tous les pays n’ont pas défini ce type de recommandations nutritionnelles, et souvent, ceux qui l’ont fait ne donnent pas d’indications précises sur les quantités d’aliments et le nombre de kilocalories. Pour remédier à ce manque de données et créer une norme mondiale en matière de régime alimentaire sain qui reprend les points communs des recommandations nutritionnelles dans le monde entier, nous avons sélectionné 10 recommandations nutritionnelles fondées sur le choix des aliments, représentatives de différentes régions du monde et élaborées ces dernières années. Le panier alimentaire sain a été créé pour pouvoir définir cette norme mondiale. Il est fondé sur les proportions moyennes des différents groupes d’aliments indiquées dans les recommandations nutritionnelles nationales fondées sur le choix des aliments et utilise les quantités médianes préconisées pour chaque groupe dans les 10 recommandations qui ont été quantifiées. Le panier alimentaire sain est défini de manière à fournir un apport énergétique alimentaire de 2 330 kilocalories par jour et se compose de denrées disponibles localement, classées dans six groupes: féculents; légumes; fruits; aliments d’origine animale; légumineuses, fruits à coque et graines; huiles et graisses. Plus précisément, il est conçu pour apporter 1 160 kilocalories de féculents, 110 kilocalories de légumes, 160 kilocalories de fruits, 300 kilocalories d’aliments d’origine animale, 300 kilocalories de légumineuses, de fruits à coque et de graines, et 300 kilocalories d’huiles et de graisses. Le coût d’une alimentation saine a été estimé pour 173 pays sur la période 2017-2024.
Méthodes de calcul des coûts de référence lorsque des données du Programme de comparaison internationale sont disponibles
Pour calculer le coût de l’alimentation saine la moins onéreuse, à chaque moment et à chaque endroit, on classe les différentes denrées alimentaires du Programme de comparaison internationale dans leur groupe, et on détermine les produits les moins onéreux qui répondent aux exigences du panier alimentaire sain. Au total, pour chaque pays, 11 denrées alimentaires de moindre coût sont intégrées dans le panier alimentaire sain: deux féculents, trois légumes, deux fruits, deux aliments d’origine animale, un(e) légumineuse/fruit à coque/graine, et une huile ou graisse. Le coût par jour de chaque groupe d’aliments correspond au prix d’achat des denrées sélectionnées dans ce groupe multiplié par la quantité qui apporte l’énergie définie pour ce groupe dans le panier alimentaire sain. Pour terminer, on détermine le coût d’une alimentation saine dans chaque pays en additionnant le coût des six groupes d’aliments.
Méthodes de calcul des coûts extrapolés lorsqu’on ne dispose pas de données du Programme de comparaison internationale
Le Programme de comparaison internationale est actuellement la seule source de données sur les prix au détail des articles normalisés au niveau international. Ces données ne sont mises à disposition que tous les trois à quatre ans, ce qui ne permet pas d’effectuer une actualisation annuelle du coût d’une alimentation saine. La dernière série de données a été publiée en 2024, et se rapporte aux prix de 2021. Pour actualiser l’indicateur de coût pour les années situées entre deux cycles de publication du Programme de comparaison internationale, on établit une estimation en appliquant les IPC des produits alimentaires publiés par la FAO au coût d’une alimentation saine en 2021. Cet ensemble de données suit la variation mensuelle des IPC (indices généraux des prix à la consommation et indices des prix à la consommation des produits alimentaires) au niveau national en prenant 2015 comme année de base. Les IPC annuels sont calculés sous la forme d’une moyenne géométrique des 12 indices mensuels. Le coût d’une alimentation saine, , est estimé pour les années manquantes en multipliant le coût réel dans chaque pays en 2021, exprimé en unités monétaires locales, par le ratio des IPC, puis en divisant le résultat par les PPA:

où t = 2017-2024 e(hormis l’année 2021), et FCPI ratio 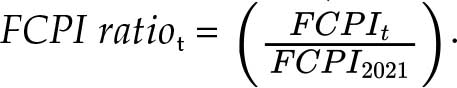
Cette année, pour la première fois, les indicateurs relatifs au coût et à l’abordabilité d’une alimentation saine sont communiqués jusqu’à l’année précédant celle du rapport. Cela a été rendu possible grâce à la mise à disposition en temps voulu des données de 2024 relatives aux IPC détaillés des produits alimentaires, des données sur les distributions des revenus utilisées par la Banque mondiale pour établir les prévisions immédiates de la pauvreté et des facteurs de conversion en PPA. Cependant, s’agissant des facteurs de conversion en PPA, bien que les éléments proviennent de la base de données des indicateurs du développement dans le monde, il manquait les informations relatives à 43 pays en 2024 et à 5 pays en 2023 (voir annexe 1A, tableau A1.5). De ce fait, les valeurs des PPA pour ces pays en 2023 et 2024 ont été estimées à l’aide de la méthode d’extrapolation employée par la Banque mondiale pour les indicateurs du développement dans le monde13, comme suit:
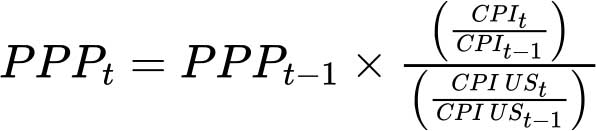
où CPI représente l’indice général des prix à la consommation, et CPI US est l’indice général des prix à la consommation pour le pays de référence (en l’occurrence, les États-Unis d’Amérique).
S’agissant des 15 pays qui n’ont pas de données relatives aux PPA pour trois années ou davantage, des imputations de PPA sont appliquées à l’aide d’un modèle autorégressif à moyenne mobile intégrée avec variable explicative externe (ARIMAX) (voir annexe 1A, tableau A1.5). Conformément à la méthode d’extrapolation des PPA employée par la Banque mondiale pour les indicateurs du développement dans le monde, le ratio entre l’IPC général d’un pays et l’IPC des États-Unis d’Amérique est introduit dans la spécification du modèle en tant que principal prédicteur des valeurs des PPA. Le PIB par habitant et les dépenses de consommation des ménages par habitant sont également ajoutés en tant que covariables externes, et la méthode de lissage de Holt-Winters est appliquée aux deux séries pour combler les éventuelles lacunes. L’approche ARIMAX permet d’estimer, pour chaque pays, plusieurs spécifications de modèle comprenant une composante autorégressive, une composante d’intégration, une moyenne mobile et une combinaison de ces trois éléments. La meilleure spécification est sélectionnée lorsque le coefficient estimé du ratio des IPC, au moins, est statistiquement significatif, la signification statistique des paramètres ARIMAX étant considérée en deuxième lieu. Dans le cas des pays et des territoires qui affichent des séries de PPA anormales sur la durée, le ratio des IPC se révèle être le seul coefficient statistiquement significatif qui influe sur la variabilité des valeurs des PPA. Pour les pays et territoires qui présentent des séries de PPA moins volatiles, en revanche, la tendance historique des PPA joue également un rôle dans la prédiction des valeurs des PPA, tout comme les coefficients estimés du PIB par habitant et/ou des dépenses par habitant. Le modèle ARIMAX permet de calculer les valeurs prédites pour la meilleure spécification sélectionnée pour chaque pays/territoire.
Problèmes et limites
Les données relatives aux prix des articles normalisés au niveau international n’étant pas disponibles chaque année, un suivi annuel n’est pas possible. L’une des limites de la méthode d’actualisation du coût d’une alimentation saine est que l’évolution du coût dépend des IPC (des produits alimentaires) et ne reflète pas les changements concernant des articles particuliers dans les prix des produits alimentaires, ni les variations des prix selon les groupes d’alimentsbc. La FAO, en collaboration avec la Banque mondiale, réfléchit à la manière d’étendre la communication des prix au niveau des articles, ou des prix au niveau des groupes d’aliments, afin de pouvoir réaliser un suivi plus régulier et plus rigoureux du coût d’une alimentation saine.
Les agrégats régionaux et mondiaux relatifs au coût d’une alimentation saine sont calculés à partir d’une moyenne arithmétique des pays de chaque groupe.
Lectures recommandées
Bai, Y., Conti, V., Herforth, A., Cafiero, C., Ebel, A., Rissanen, M. O., Masters, W. A. et Rosero Moncayo, J. 2024. Methods for monitoring the cost of a healthy diet based on price data from the International Comparison Program. Documents de travail de la FAO relatifs aux statistiques no 24-43. Rome, FAO. https://doi.org/10.4060/cd3037en
Herforth, A., Bai, Y., Venkat, A., Mahrt, K., Ebel, A. et Masters, W. A. 2020. Cost and affordability of healthy diets across and within countries – Document d’information établi pour servir de base au rapport sur L’État de la sécurité alimentaire et de la nutrition dans le monde 2020. Étude technique de la FAO sur l’économie du développement agricole no 9. Rome, FAO. https://doi.org/10.4060/cb2431en
Herforth, A., Venkat, A., Bai, Y., Costlow, L., Holleman, C. et Masters, W. A. 2022. Methods and options to monitor the cost and affordability of a healthy diet globally – Document d’information établi pour servir de base au rapport sur L’État de la sécurité alimentaire et de la nutrition dans le monde 2022. Document de travail de la FAO sur l’économie du développement agricole no 22-03. Rome, FAO. https://doi.org/10.4060/cc1169en
INACCESSIBILITÉ ÉCONOMIQUE D’UNE ALIMENTATION SAINE
Définition
L’inaccessibilité économique d’une alimentation saine est définie comme étant l’impossibilité, pour un ménage ou une personne, de payer le montant nécessaire pour acheter l’ensemble le moins onéreux d’aliments disponibles localement qui répondent aux critères d’une alimentation saine, une fois prise en compte la portion de leur revenu qu’ils réservent aux acquisitions destinées à satisfaire tous les besoins essentiels autres qu’alimentaires.
Indicateur
Le principal indicateur (appelé «prévalence de l’inaccessibilité économique» [PUA – prevalence of unaffordability]) est une estimation du pourcentage, dans une population, de personnes dont le revenu disponible, net du montant nécessaire pour acquérir l’ensemble des biens et services de base non alimentaires, est inférieur au coût minimum d’une alimentation saine. Les estimations nationales sont calculées en comparant la distribution des revenus des pays à un seuil (r) obtenu en additionnant le coût d’une alimentation saine à celui des besoins essentiels non alimentaires (n). Parallèlement à la prévalence de l’inaccessibilité économique, on calcule également le nombre de personnes qui ne peuvent se permettre une alimentation saine (NUA), en multipliant la PUA par la taille de la population de référence.
Les séries entières (2017-2024) d’estimations de la PUA et du NUA sont révisées pour chaque édition du présent rapport afin de tenir compte des nouvelles données sur les coûts et la population ainsi que des distributions actualisées des revenus. Comme cette procédure entraîne généralement une révision à rebours des séries entières, il est conseillé aux lecteurs de ne pas comparer les chiffres d’une édition sur l’autre et de se reporter systématiquement à l’édition la plus récente, y compris pour les chiffres des années précédentes.
Méthode
Pour estimer la prévalence de l’inaccessibilité économique dans une population, on calcule le seuil de coût quotidien par habitant pour chaque pays. En raison d’un manque d’informations sur le coût spécifique des biens et des services de base non alimentaires dans chaque pays, les différences dans les dépenses non alimentaires sont basées sur les données disponibles pour les quatre groupes de revenu des pays définis par la Banque mondiale. De ce fait, le seuil de coût quotidien par habitant associe le coût d’une alimentation saine dans un pays et le coût de base des besoins non alimentaires dans le groupe de revenu auquel appartient le pays . Le seuil de coût est déterminé comme suit:
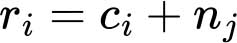
où ci est le coût d’une alimentation saine dans un pays, et nj est le coût des biens et services de base non alimentaires pour le groupe de revenu j. Le nj final est exprimé dans la monnaie correspondant à l’année de référence du seuil de pauvreté (actuellement en dollars de 2017 en PPA); nj est obtenu en multipliant les seuils de pauvreté internationaux de la Banque mondiale par une part des dépenses totales à réserver aux biens et services de base non alimentaires qui est fonction du groupe de revenu, comme suit:

Les parts de revenu à réserver aux biens et services de base non alimentaires sont déterminées en référence à celles déclarées par les ménages appartenant au deuxième quintile de la distribution des revenus pour les pays à faible revenu ou à revenu intermédiaire de la tranche inférieure et par ceux du premier quintile pour les pays à revenu intermédiaire de la tranche supérieure et les pays à revenu élevé. Ces parts ont été définies à partir de récentes enquêtes menées auprès des ménages et compilées par la Banque mondiale, notamment à partir des informations sur la consommation réelle par quintile de revenus pour 71 pays de différents groupes de revenu.
Le coût des biens et services de base non alimentaires (nj) est déjà exprimé en PPA de 2017, et le coût d’une alimentation saine est converti de ses valeurs actuelles (ct) en valeurs en PPA de 2017 (ct2017 PPP) à l’aide de la formule suivante:
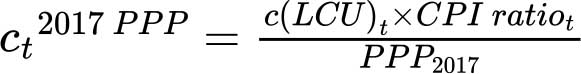
où t = 2017-2024 (hormis l’année 2021) et 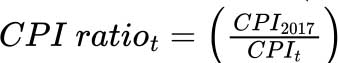 est calculé à l’aide de l’IPC général.
est calculé à l’aide de l’IPC général.
Enfin, le seuil de coût ri, exprimé en PPA de 2017, est comparé aux distributions des revenus par pays reflétant le revenu disponible des ménages pour estimer le pourcentage de la population dont le revenu est inférieur à ce seuil, comme dans la formule ci-après:

Sources de données
Les distributions de revenus proviennent de la plateforme Pauvreté et inégalités de la Banque mondiale et sont disponibles pour quelque 150 pays jusqu’à l’année 202414.
Les agrégats régionaux et mondiaux de la prévalence de l’inaccessibilité économique correspondent aux moyennes, pondérées par la population, de la prévalence de l’inaccessibilité économique estimée pour les pays pour lesquels les données sont disponibles, comme suit:
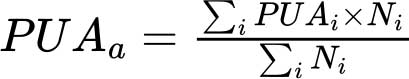
où a indique la région ou un autre agrégat, PUAi est la valeur de la prévalence de l’inaccessibilité économique estimée pour le pays i dans l’agrégat, et Ni est la taille de la population correspondante. L’agrégat régional est calculé uniquement si les pays pour lesquels une estimation est disponible représentent au moins 50 pour cent de la population de l’agrégat.
Le nombre de personnes qui ne peuvent se permettre une alimentation saine (NUAa) est ensuite obtenu en multipliant la PUAa moyenne – calculée à partir des pays pour lesquels des données sont disponibles – par la taille totale de la population Na de tous les pays figurant dans cet agrégat.
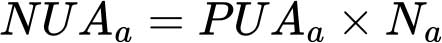
Pour obtenir une estimation du NUA dans le monde, on multiplie la PUA de chacune des cinq régions du monde par leur population totale. Il convient d’éviter, lors de l’établissement de l’estimation du NUA dans le monde, d’additionner les estimations des NUA réalisées pour d’autres groupements de pays, tels que ceux fondés sur les niveaux de revenu. Le présent rapport utilise les données démographiques provenant de la révision 2024 des World Population Prospects4.
Problèmes et limites
Dans la présente édition du rapport, la méthode a été affinée pour tenir compte du fait que le coût des besoins non alimentaires varie selon les pays. Cependant, en l’absence d’informations au niveau des pays, les différences dans les dépenses non alimentaires ne sont intégrées qu’au niveau des groupes de revenu pour le moment. Par ailleurs, outre la nécessité de procéder à une correction pour tenir compte des différences entre les pays, il est également important d’intégrer le fait que le coût d’un niveau de vie digne minimal (r = c + n) varie aussi à l’intérieur d’un même pays. Pour les pays hétérogènes et de grande taille, en particulier, l’absence de prise en compte de ces différences ainsi que l’utilisation de la moyenne nationale en tant que seuil de coût peuvent déboucher sur des estimations biaisées de l’inaccessibilité économique. La direction et l’importance du biais dépendront de l’orientation et de l’ampleur de la corrélation possible entre les niveaux de revenu et un seuil correctement défini en fonction du lieu.
Lectures recommandées
Bai, Y., Herforth, A., Cafiero, C., Conti, V., Rissanen, M. O., Masters, W. A. et Rosero Moncayo, J. 2024. Methods for monitoring the affordability of a healthy diet. Document de travail de la FAO relatifs aux statistiques no 24-44. Rome, FAO. https://doi.org/10.4060/cd3703en
Herforth, A., Bai, Y., Venkat, A., Mahrt, K., Ebel, A. et Masters, W. A. 2020. Cost and affordability of healthy diets across and within countries – Document d’information établi pour servir de base au rapport sur L’État de la sécurité alimentaire et de la nutrition dans le monde 2020. Étude technique de la FAO sur l’économie du développement agricole no 9. Rome, FAO. https://doi.org/10.4060/cb2431en
ÉMACIATION CHEZ L’ENFANT DE MOINS DE 5 ANS
Définition
Poids (en kilogrammes) rapporté à la taille (en centimètres) inférieur d’au moins deux écarts types à la valeur médiane des normes de croissance de l’enfant définies par l’Organisation mondiale de la Santé (OMS).
Indicateur
L’indicateur est le pourcentage d’enfants âgés de 0 à 59 mois dont le poids pour la taille est inférieur d’au moins deux écarts types au poids médian pour leur taille selon les normes OMS de croissance de l’enfant. Les estimations présentées sont fondées sur les données du rapport Levels and trends in child malnutrition: UNICEF/WHO/World Bank Group Joint Child Malnutrition Estimates. Key findings of the 2025 edition43. La série complète d’estimations est révisée à l’occasion de chaque nouvelle édition de ce rapport. Nous invitons les lecteurs à ne pas comparer les séries régionales et mondiales d’une édition sur l’autre.
Méthode
Estimations au niveau des pays
L’ensemble de données des estimations conjointes de la malnutrition infantile (JME) comprend l’estimation ponctuelle, ainsi que l’erreur type, les bornes de l’intervalle de confiance à 95 pour cent et la taille de l’échantillon non pondéré, lorsqu’ils sont disponibles. Lorsque des microdonnées sont disponibles, l’ensemble de données des JME utilise des estimations qui ont été recalculées pour respecter la définition type mondiale. Lorsqu’aucune microdonnée n’est disponible, ce sont les estimations communiquées qui sont utilisées, sauf si des ajustements s’imposent à des fins de normalisation dans les cas suivants:
- utilisation d’une autre référence de croissance que les normes de croissance de l’OMS de 2006;
- tranches d’âge ne comprenant pas entièrement le groupe des enfants de 0 à 59 mois;
- sources de données nationalement représentatives des populations résidant en milieu rural seulement.
Agrégats régionaux et mondiaux
Les données de prévalence de l’émaciation provenant des sources de données nationales de l’ensemble de données par pays des JME de mai 2025 ont été utilisées pour générer des estimations régionales et mondiales de 1990 à 2024 à l’aide du modèle multiniveau sous-régional des JME, en appliquant des pondérations correspondant aux nombres d’enfants de moins de 5 ans donnés par l’édition 2024 du rapport World Population Prospects4.
Sources de données
Les enquêtes sur les ménages représentatives au niveau national, telles que les enquêtes démographiques et sanitaires, les enquêtes en grappes à indicateurs multiples, les enquêtes SMART (Suivi et évaluation normalisés des phases de secours et de transition) et les enquêtes LSMS, sont les sources de données nationalement représentatives les plus courantes; elles permettent de collecter des données sur la nutrition des enfants de moins de 5 ans, en particulier la taille, le poids et l’âge, que l’on peut utiliser pour produire des estimations de la prévalence de l’émaciation au niveau national. Certaines sources de données administratives (provenant de systèmes de surveillance, notamment) sont également prises en compte lorsque la couverture démographique est élevée.
Les enquêtes des pays pouvant être réalisées durant n’importe quelle saison, l’estimation de prévalence qui en découle peut aussi bien être élevée ou basse, elle peut également être entre les deux si la collecte de données s’est déroulée sur plusieurs saisons. En d’autres termes, la prévalence de l’émaciation rend compte de cette situation à un moment précis, et non sur une année entière. Les variations saisonnières d’une enquête à l’autre ne permettent guère d’en déduire des tendances.
Problèmes et limites
La périodicité recommandée en matière de communication d’informations sur l’émaciation est de trois à cinq ans, mais certains pays mettent ces données à disposition moins fréquemment. Bien que tout ait été fait pour optimiser la comparabilité des statistiques entre pays et dans le temps, les données des pays peuvent différer du point de vue des modalités de collecte, de la population couverte et des méthodes d’estimation utilisées. Les estimations issues des enquêtes sont assorties de niveaux d’incertitude imputables à la fois à des erreurs d’échantillonnage et à d’autres types d’erreurs (erreurs techniques de mesure, erreurs d’enregistrement, etc.). Aucune de ces deux sources d’erreurs n’a été pleinement prise en compte dans le calcul des estimations aux niveaux national, régional et mondial.
Lectures recommandées
de Onis, M., Blössner, M., Borghi, E., Morris, R. et Frongillo, E. A. 2004. Methodology for estimating regional and global trends of child malnutrition. International Journal of Epidemiology, 33(6): 1260-1270. https://doi.org/10.1093/ije/dyh202
Banque mondiale, OMS et UNICEF (Fonds des Nations Unies pour l’enfance). 2024. The UNICEF-WHO-World Bank Joint Child Malnutrition Estimates (JME) standard methodology. New York, États-Unis d’Amérique. https://iris.who.int/bitstream/handle/10665/379080/9789240100190-eng.pdf?sequence=1
Banque mondiale, OMS et UNICEF. 2025. Levels and trends in child malnutrition: UNICEF/WHO/World Bank Group Joint Child Malnutrition Estimates. Key findings of the 2025 edition. New York (États-Unis d’Amérique), Genève (Suisse) et Washington (États-Unis d’Amérique). https://data.unicef.org/resources/JME, https://www.who.int/teams/nutrition-and-food-safety/monitoring-nutritional-status-and-food-safety-and-events/joint-child-malnutrition-estimates/latest-estimates, https://datatopics.worldbank.org/child-malnutrition
OMS. 2014. Plan d’application exhaustif concernant la nutrition chez la mère, le nourrisson et le jeune enfant. Genève (Suisse). https://www.who.int/fr/publications/i/item/WHO-NMH-NHD-14.1
OMS. 2024. Nutrition Landscape Information System (NLIS) country profile indicators: interpretation guide. Second edition. Genève (Suisse). https://www.who.int/publications/i/item/9789241516952
RETARD DE CROISSANCE CHEZ L’ENFANT DE MOINS DE 5 ANS
Définition
Taille (en centimètres) rapportée à l’âge (en jours) inférieure d’au moins deux écarts types à la valeur médiane des normes OMS de croissance de l’enfant.
Indicateur
L’indicateur est le pourcentage d’enfants âgés de 0 à 59 mois dont la taille est inférieure d’au moins deux écarts types à la taille médiane pour leur âge selon les normes OMS de croissance de l’enfant. Les estimations présentées sont fondées sur les données du rapport Levels and trends in child malnutrition: UNICEF/WHO/World Bank Group Joint Child Malnutrition Estimates. Key findings of the 2025 edition43. La série complète d’estimations est révisée à l’occasion de chaque nouvelle édition de ce rapport. Nous invitons les lecteurs à ne pas comparer les séries régionales et mondiales d’une édition sur l’autre.
Méthode
Estimations au niveau des pays
L’ensemble de données des JME comprend l’estimation ponctuelle, ainsi que l’erreur type, les bornes de l’intervalle de confiance à 95 pour cent et la taille de l’échantillon non pondéré, lorsqu’ils sont disponibles. Lorsque des microdonnées sont disponibles, l’ensemble de données des JME comprend des estimations qui ont été recalculées pour respecter la définition type mondiale. Lorsqu’aucune microdonnée n’est disponible, ce sont les estimations communiquées qui sont présentées, sauf si des ajustements s’imposent à des fins de normalisation dans les cas suivants:
- utilisation d’une autre référence de croissance que les normes de croissance de l’OMS de 2006;
- tranches d’âge ne comprenant pas entièrement le groupe des enfants de 0 à 59 mois;
- sources de données nationalement représentatives des populations résidant en milieu rural seulement.
À partir de l’ensemble de données des JME de mai 2025, la prévalence du retard de croissance a été modélisée à une échelle logit (fonction logit) à l’aide d’un modèle mixte longitudinal pénalisé avec un terme d’erreur hétérogène. La qualité des modèles a été quantifiée au moyen de critères d’adéquation au modèle qui équilibrent la complexité de ce dernier et la finesse de l’ajustement aux données observées. La méthode proposée présente des caractéristiques importantes, notamment des tendances temporelles non linéaires, des tendances régionales, des tendances propres aux pays, des données de covariable et un terme d’erreur hétérogène. Tous les pays disposant de données contribuent aux estimations de la tendance temporelle globale et de l’effet des données de covariable sur la prévalence. Les données de covariable consistaient en des indices sociodémographiques linéaires et quadratiquesbd et unnombre moyen d’accès au système de santé au cours des cinq années précédentes.
En 2025, des estimations annuelles modélisées du retard de croissance couvrant la période 2000-2024 ont été diffusées dans les JME pour 162 pays et zones. Des estimations modélisées ont également été établies pour 43 pays supplémentaires, à seule fin de générer les agrégats régionaux et mondiaux.
Agrégats régionaux et mondiaux
Les agrégats mondiaux et régionaux établis pour chaque année de 1990 à 2024 ont été dérivés en tant que moyennes des chiffres des pays respectifs, pondérées par le nombre d’enfants de moins de 5 ans de ces pays, tel qu’il figure dans l’édition 2024 de la publication World Population Prospects4, au moyen des estimations modélisées pour 205 pays et zones. Ce nombre comprend 162 pays et zones pour lesquels des estimations sont publiées. Il comprend également 43 pays pour lesquels on a modélisé des estimations qui ont servi à élaborer les agrégats régionaux et mondiaux, mais qui n’ont pas été communiquées.
Sources de données
Les enquêtes sur les ménages représentatives au niveau national, telles que les enquêtes démographiques et sanitaires, les enquêtes en grappes à indicateurs multiples, les enquêtes SMART et les enquêtes LSMS, sont les sources de données nationalement représentatives les plus courantes; elles permettent de collecter des données sur la nutrition des enfants de moins de 5 ans, en particulier la taille et l’âge, que l’on peut utiliser pour produire des estimations de la prévalence du retard de croissance au niveau national. Certaines sources de données administratives (provenant de systèmes de surveillance, notamment) sont également prises en compte lorsque la couverture démographique est élevée.
Problèmes et limites
La périodicité recommandée en matière de communication d’informations sur le retard de croissance est de trois à cinq ans, mais certains pays mettent ces données à disposition moins fréquemment. Bien que tout ait été fait pour optimiser la comparabilité des statistiques entre pays et dans le temps, les données des pays peuvent différer du point de vue des modalités de collecte, de la population couverte et des méthodes d’estimation utilisées. Les estimations issues des enquêtes sont assorties de niveaux d’incertitude imputables à la fois à des erreurs d’échantillonnage et à d’autres types d’erreurs (erreurs techniques de mesure, erreurs d’enregistrement, etc.). Aucune de ces deux sources d’erreurs n’a été pleinement prise en compte dans le calcul des estimations aux niveaux national, régional et mondial.
Lectures recommandées
Brauer, M., Roth, G. A., Aravkin, A. Y., Zheng, P., Abata, K. H., Abate, Y. H., Abbafati, C. et al. 2021. Global burden and strength of evidence for 88 risk factors in 204 countries and 811 subnational locations, 1990-2021: a systematic analysis for the Global Burden of Disease Study 2021. The Lancet, 403(10440): 2162-2203. https://doi.org/10.1016/S0140-6736(24)00933-4. Erratum, The Lancet, 404(10449): 244. https://doi.org/10.1016/S0140-6736(24)01458-2
McLain, A. C., Frongillo, E. A., Feng, J. et Borghi, E. 2019. Prediction intervals for penalized longitudinal models with multisource summary measures: An application to childhood malnutrition. Statistics in Medicine, 38(6): 1002-1012. https://doi.org/10.1002/sim.8024
Banque mondiale, OMS et UNICEF. 2024. The UNICEF-WHO-World Bank Joint Child Malnutrition Estimates (JME) standard methodology. New York (États-Unis d’Amérique). https://iris.who.int/bitstream/handle/10665/379080/9789240100190-eng.pdf?sequence=1
Banque mondiale, OMS et UNICEF. 2025. Levels and trends in child malnutrition: UNICEF/WHO/World Bank Group Joint Child Malnutrition Estimates. Key findings of the 2025 edition. New York (États-Unis d’Amérique), Genève (Suisse) et Washington (États-Unis d’Amérique). https://data.unicef.org/resources/JME, https://www.who.int/teams/nutrition-and-food-safety/monitoring-nutritional-status-and-food-safety-and-events/joint-child-malnutrition-estimates/latest-estimates, https://datatopics.worldbank.org/child-malnutrition
OMS. 2014. Plan d’application exhaustif concernant la nutrition chez la mère, le nourrisson et le jeune enfant. Genève (Suisse). https://www.who.int/fr/publications/i/item/WHO-NMH-NHD-14.1
OMS. 2024. Nutrition Landscape Information System (NLIS) country profile indicators: interpretation guide. Second edition. Genève (Suisse). https://www.who.int/publications/i/item/9789241516952
OMS et UNICEF. 2019. Recommandations pour la collecte des données, leur analyse et la préparation des rapports sur les indicateurs anthropométriques chez les enfants âgés de moins de 5 ans. Genève (Suisse) et New York (États-Unis d’Amérique). https://www.who.int/publications/i/item/9789241515559
EXCÈS PONDÉRAL CHEZ L’ENFANT DE MOINS DE 5 ANS
Définition
Poids (en kilogrammes) rapporté à la taille (en centimètres) supérieur d’au moins deux écarts types à la valeur médiane des normes OMS de croissance de l’enfant.
Indicateur
L’indicateur est le pourcentage d’enfants âgés de 0 à 59 mois dont le poids est supérieur d’au moins deux écarts types au poids médian pour leur taille selon les normes OMS de croissance de l’enfant. Les estimations présentées sont fondées sur les données du rapport Levels and trends in child malnutrition: UNICEF/WHO/World Bank Group Joint Child Malnutrition Estimates. Key findings of the 2025 edition43. La série complète d’estimations est révisée à l’occasion de chaque nouvelle édition de ce rapport. Nous invitons les lecteurs à ne pas comparer les séries régionales et mondiales d’une édition sur l’autre.
Méthode
Estimations au niveau des pays
L’ensemble de données des JME comprend l’estimation ponctuelle, ainsi que l’erreur type, les bornes de l’intervalle de confiance à 95 pour cent et la taille de l’échantillon non pondéré, lorsqu’ils sont disponibles. Lorsque des microdonnées sont disponibles, l’ensemble de données des JME comprend des estimations qui ont été recalculées pour respecter la définition type mondiale. Lorsqu’aucune microdonnée n’est disponible, ce sont les estimations communiquées qui sont présentées, sauf si des ajustements s’imposent à des fins de normalisation dans les cas suivants:
- utilisation d’une autre référence de croissance que les normes de croissance de l’OMS de 2006;
- tranches d’âge ne comprenant pas entièrement le groupe des enfants de 0 à 59 mois;
- sources de données nationalement représentatives des populations résidant en milieu rural seulement.
À partir de l’ensemble de données des JME de mai 2025, la prévalence de l’excès pondéral a été modélisée à une échelle logit (fonction logit) à l’aide d’un modèle mixte longitudinal pénalisé avec un terme d’erreur hétérogène. La qualité des modèles a été quantifiée au moyen de critères d’adéquation au modèle qui équilibrent la complexité de ce dernier et la finesse de l’ajustement aux données observées. La méthode proposée présente des caractéristiques importantes, notamment des tendances temporelles non linéaires, des tendances régionales, des tendances propres aux pays, des données de covariable et un terme d’erreur hétérogène. Tous les pays disposant de données contribuent aux estimations de la tendance temporelle globale et de l’effet des données de covariable sur la prévalence. Les données de covariable consistaient en des indices sociodémographiques linéaires et quadratiques.
En 2025, des estimations annuelles modélisées de l’excès pondéral couvrant la période 2000-2024 ont été diffusées dans les JME pour 163 pays et zones. Des estimations modélisées ont également été établies pour 42 pays supplémentaires, à seule fin de générer les agrégats régionaux et mondiaux.
Agrégats régionaux et mondiaux
Les agrégats mondiaux et régionaux établis pour chaque année de 1990 à 2024 ont été dérivés en tant que moyennes des chiffres des pays respectifs, pondérées par le nombre d’enfants de moins de 5 ans de ces pays, tel qu’il figure dans l’édition 2024 de la publication World Population Prospects4, au moyen des estimations modélisées pour 205 pays. Ce nombre comprend 163 pays et zones pour lesquels des estimations sont publiées. Il comprend également 42 pays pour lesquels on a modélisé des estimations qui ont servi à élaborer les agrégats régionaux et mondiaux, mais qui n’ont pas été communiquées.
Sources de données
Les enquêtes sur les ménages représentatives au niveau national, telles que les enquêtes démographiques et sanitaires, les enquêtes en grappes à indicateurs multiples, les enquêtes SMART et les enquêtes LSMS, sont les sources de données nationalement représentatives les plus courantes; elles permettent de collecter des données sur la nutrition des enfants de moins de 5 ans, en particulier la taille, le poids et l’âge, que l’on peut utiliser pour générer des estimations de la prévalence de l’excès pondéral au niveau national. Certaines sources de données administratives (provenant de systèmes de surveillance, notamment) sont également prises en compte lorsque la couverture démographique est élevée.
Problèmes et limites
La périodicité recommandée en matière de communication d’informations sur l’excès pondéral est de trois à cinq ans, mais certains pays mettent ces données à disposition moins fréquemment. Bien que tout ait été fait pour optimiser la comparabilité des statistiques entre pays et dans le temps, les données des pays peuvent différer du point de vue des modalités de collecte, de la population couverte et des méthodes d’estimation utilisées. Les estimations issues des enquêtes sont assorties de niveaux d’incertitude imputables à la fois à des erreurs d’échantillonnage et à d’autres types d’erreurs (erreurs techniques de mesure, erreurs d’enregistrement, etc.). Aucune de ces deux sources d’erreurs n’a été pleinement prise en compte dans le calcul des estimations aux niveaux national, régional et mondial.
Lectures recommandées
Brauer, M., Roth, G. A., Aravkin, A. Y., Zheng, P., Abata, K. H., Abate, Y. H., Abbafati, C. et al. 2024. Global burden and strength of evidence for 88 risk factors in 204 countries and 811 subnational locations, 1990-2021: a systematic analysis for the Global Burden of Disease Study 2021. The Lancet, 403(10440): 2162-2203. https://doi.org/10.1016/S0140-6736(24)00933-4. Erratum, The Lancet, 404(10449): 244. https://doi.org/10.1016/S0140-6736(24)01458-2.
McLain, A. C., Frongillo, E. A., Feng, J. et Borghi, E. 2019. Prediction intervals for penalized longitudinal models with multisource summary measures: An application to childhood malnutrition. Statistics in Medicine, 38(6): 1002–1012. https://doi.org/10.1002/sim.8024
Banque mondiale, OMS et UNICEF. 2024. The UNICEF-WHO-World Bank Joint Child Malnutrition Estimates (JME) standard methodology. New York (États-Unis d’Amérique). https://iris.who.int/bitstream/handle/10665/379080/9789240100190-eng.pdf?sequence=1
UNICEF, OMS et Banque mondiale. 2025. Levels and trends in child malnutrition: UNICEF/WHO/World Bank Group Joint Child Malnutrition Estimates. Key findings of the 2025 edition. New York (États-Unis d’Amérique), Genève (Suisse) et Washington (États-Unis d’Amérique). https://data.unicef.org/resources/JME, https://www.who.int/teams/nutrition-and-food-safety/monitoring-nutritional-status-and-food-safety-and-events/joint-child-malnutrition-estimates/latest-estimates, https://datatopics.worldbank.org/child-malnutrition
OMS. 2014. Plan d’application exhaustif concernant la nutrition chez la mère, le nourrisson et le jeune enfant. Genève (Suisse). https://www.who.int/fr/publications/i/item/WHO-NMH-NHD-14.1
OMS. 2024. Nutrition Landscape Information System (NLIS) country profile indicators: interpretation guide. Second edition. Genève (Suisse). https://www.who.int/publications/i/item/9789241516952
OMS et UNICEF. 2019. Recommandations pour la collecte des données, leur analyse et la préparation des rapports sur les indicateurs anthropométriques chez les enfants âgés de moins de 5 ans. Genève (Suisse) et New York (États-Unis d’Amérique). https://www.who.int/publications/i/item/9789241515559
ALLAITEMENT MATERNEL EXCLUSIF
Définition
L’allaitement maternel exclusif du nourrisson de moins de 6 mois correspond à une alimentation composée uniquement de lait maternel, sans aliment ni boisson supplémentaire, pas même de l’eau.
Indicateur
L’indicateur est le pourcentage de nourrissons de 0 à 5 mois alimentés exclusivement par du lait maternel, sans aliment ni boisson supplémentaire, pas même de l’eau, au cours des 24 heures précédant l’enquête.
Les estimations présentées sont tirées de la base de données mondiale de l’UNICEF sur l’alimentation du nourrisson et du jeune enfant15.
Méthode
Estimations au niveau des pays
Cet indicateur correspond à l’allaitement maternel, sans aliment ni boisson supplémentaire, pas même de l’eau. Les estimations reposent sur une rétrospection de l’alimentation du jour précédent pour un échantillon transversal de nourrissons de 0 à 5 mois.

L’allaitement par une nourrice et l’emploi de lait maternel tiré ou de lait de donneuses sont considérés comme un allaitement maternel. Les médicaments prescrits, les sels de réhydratation orale, les vitamines et les minéraux ne sont pas considérés comme des liquides ou des aliments. Cependant, les breuvages à base de plantes et les remèdes traditionnels similaires sont considérés comme des liquides, et les nourrissons qui en consomment ne sont pas considérés comme étant nourris exclusivement au sein.
Agrégats régionaux et mondiaux
En 2012, les estimations régionales et mondiales de l’allaitement maternel exclusif ont été établies à l’aide de l’estimation la plus récente disponible pour chaque pays sur la période comprise entre 2005 et 2012. De la même façon, les estimations de 2023 ont été élaborées à l’aide de l’estimation la plus récente disponible pour chaque pays sur la période comprise entre 2017 et 2023 (à l’exception de cinq pays pour lesquels les données sont celles de 2024). Les moyennes mondiales et régionales ont été calculées en tant que moyennes pondérées de la prévalence de l’allaitement maternel exclusif dans chaque pays, en utilisant le nombre total de nourrissons de 0 à 5 mois (défini comme correspondant à la moitié de la population de moins de 1 an) figurant dans l’édition 2024 de la publication World Population Prospects (2012 pour la base de référence et 2023 pour les chiffres actuels) comme coefficient de pondération4. Sauf indication contraire, les estimations ne sont présentées que lorsque les données disponibles sont représentatives d’au moins 50 pour cent du nombre total de nourrissons de 0 à 5 mois dans les régions correspondantes.
Sources de données
Les données sont recueillies dans le cadre d’enquêtes sur les ménages représentatives au niveau national, telles que les enquêtes démographiques et sanitaires et les enquêtes en grappes à indicateurs multiples. Les estimations sont établies à partir des questions sur les liquides et les aliments donnés aux enfants de 0 à 23 mois au cours des 24 heures précédant l’enquête.
Problèmes et limites
De nombreux pays recueillent des données sur l’allaitement maternel exclusif, mais on manque de données pour les pays à revenu élevé, notamment. La périodicité recommandée pour la communication d’informations sur l’allaitement maternel exclusif est de trois à cinq ans. Cependant, les données de certains pays sont communiquées moins fréquemment, ce qui signifie que la modification des modes d’alimentation n’est souvent pas détectée avant plusieurs années.
Les moyennes régionales et mondiales ont pu en être affectées, selon les pays qui disposaient ou non de données relatives aux périodes visées dans le présent rapport.
Le fait de se baser sur l’alimentation du jour précédent est susceptible d’entraîner une surestimation de la proportion d’enfants exclusivement nourris au sein, car il se peut que des enfants qui reçoivent d’autres liquides ou aliments irrégulièrement n’en aient pas eu la veille de l’enquête.
Lectures recommandées
UNICEF. 2024. Infant and young child feeding. Dans: UNICEF. [Consulté le 30 avril 2025]. https://data.unicef.org/topic/nutrition/infant-and-young-child-feeding
OMS. 2014. Plan d’application exhaustif concernant la nutrition chez la mère, le nourrisson et le jeune enfant. Genève (Suisse). https://www.who.int/fr/publications/i/item/WHO-NMH-NHD-14.1
OMS. 2024. Nutrition Landscape Information System (NLIS) country profile indicators: interpretation guide. Second edition. Genève (Suisse). https://www.who.int/publications/i/item/9789241516952
OMS et UNICEF. 2021. Indicateurs pour l’évaluation des modes d’alimentation du nourrisson et du jeune enfant: définitions et méthodes de mesure. Genève (Suisse) et New York (États-Unis d’Amérique). https://www.who.int/fr/publications/i/item/9789240018389
INSUFFISANCE PONDÉRALE À LA NAISSANCE
Définition
L’insuffisance pondérale à la naissance correspond à un poids à la naissance inférieur à 2 500 grammes.
Indicateur
L’indicateur est le pourcentage de nouveau-nés dont le poids à la naissance est inférieur à 2 500 grammes. Les estimations présentées sont tirées de l’édition 2023 de la publication OMS/UNICEF Joint low birthweight estimates16. La série entière d’estimations étant révisée à chaque nouvelle édition, nous invitons les lecteurs à ne pas comparer les séries d’une édition sur l’autre.
Méthode
Estimations au niveau des pays
Les données représentatives au niveau national relatives à l’insuffisance pondérale à la naissance, notamment les enquêtes et les sources de données administratives, ont été regroupées à partir de 158 pays pour la période 2000-2020. Des critères de qualité des données et des méthodes d’ajustement ont été utilisés pour définir l’ensemble final de données nationales à inclure dans la modélisation. Avant d’ajouter les données des pays dans l’ensemble de données, on vérifie leur couverture et leur qualité et on les ajuste pour tenir compte des biais dus aux poids manquants et à la tendance à arrondir les données. Pour être pris en compte, les poids à la naissance issus des données administratives doivent représenter au moins 80 pour cent des naissances vivantes estimées indiquées dans l’édition 2022 du rapport World Population Prospects17 pour l’année considérée. Pour être intégrées dans l’ensemble de données, les enquêtes nationales menées auprès des ménages:
- doivent mentionner un poids à la naissance pour 30 pour cent minimum de l’échantillon;
- doivent comprendre au minimum 200 poids à la naissance;
- ne doivent comporter aucune indication de données très arrondies ou de distribution peu vraisemblable – ce qui signifie que: i) jusqu’à 55 pour cent de tous les poids à la naissance peuvent correspondre aux trois catégories les plus fréquentes (si les trois poids à la naissance les plus fréquents sont 3 000 grammes, 3 500 grammes et 2 500 grammes, il faut que leur cumul représente au plus 55 pour cent de tous les poids à la naissance de l’ensemble de données); ii) jusqu’à 10 pour cent de l’ensemble des poids à la naissance peuvent être supérieurs ou égaux à 4 500 grammes; iii) jusqu’à 5 pour cent des poids à la naissance peuvent correspondre aux extrêmes (500 grammes et 5 000 grammes);
- doivent avoir été ajustées pour tenir compte des poids à la naissance manquants et de la tendance à arrondir les données.
Les estimations de la prévalence de l’insuffisance pondérale à la naissance au niveau national ont été établies à partir d’un modèle bayésien de régression multiniveau. Le modèle est rattaché à l’échelle logit (fonction logit) pour que les proportions soient comprises entre zéro et un, puis retransformé et multiplié par 100 pour obtenir des estimations de la prévalence.
Les intercepts aléatoires hiérarchiques propres à chaque pays (pays/régions/monde) représentaient la corrélation à l’intérieur des régions et entre les régions. Des splines pénalisées ont été utilisées comme lissage temporel dans la série chronologique, ce qui signifie que des tendances temporelles non linéaires au niveau des pays ont été prises en compte sans que des variations aléatoires influent sur la tendance. Les covariables finales incluses dans le modèle étaient les suivantes: le revenu national brut par personne en PPAbe, la prévalence de l’insuffisance pondérale chez les femmes, le taux d’alphabétisation des femmes, le taux de prévalence des méthodes de contraception modernes et le pourcentage de la population urbaine.
Des catégories de qualité des données ont été utilisées pour appliquer des biais et des termes de variance supplémentaires. Ces biais ont été appliqués aux données administratives relevant de catégories de qualité inférieure, ce qui a permis de déterminer approximativement les biais escomptés liés à la tendance à l’arrondissement, lesquels avaient déjà été pris en compte lors de l’ajustement des données d’enquête. La variance supplémentaire reposait sur la catégorie de qualité des données administratives, et sur la pondération entre les données administratives et les données d’enquête si le pays disposait des deux.
Des contrôles de diagnostic standard ont été réalisés pour évaluer le niveau de convergence et l’efficacité de l’échantillonnage. Il a été procédé à une validation croisée consistant à faire la moyenne de plus de 200 sous-ensembles aléatoires composés de 20 pour cent de données de test et de 80 pour cent de données d’apprentissage. Des analyses de sensibilité ont été entreprises, y compris des contrôles portant sur les covariables, la méthode d’application des biais, le lissage temporel et les probabilités a priori non informatives. Tous les modèles ont été intégrés dans le logiciel statistique R et dans les paquets R «rjags» et «R2jags»18, 19.
Le modèle comprenait les 2 040 années-pays de données répondant aux critères d’inclusion, et a permis de produire des estimations annuelles allant de 2000 à 2020 avec des intervalles de crédibilité à 95 pour cent pour les 195 pays et zones pour lesquels des données d’entrée ou des données de covariable sur l’insuffisance pondérale à la naissance étaient disponibles. Seules les estimations des pays et des zones associés à des données sont communiquées. Concernant les 37 pays (sur 195) ne disposant d’aucune donnée ou dont les données ne remplissaient pas les critères d’inclusion, le modèle final a été utilisé pour réaliser les estimations de la prévalence de l’insuffisance pondérale à la naissance à partir des intercepts des pays et des tendances temporelles estimées sur la base des covariables par région et par pays pour toutes les années-pays.
Agrégats régionaux et mondiaux
Des agrégats régionaux et mondiaux sont produits à partir des estimations provenant de l’ensemble des 195 pays et zones pondérées par le nombre estimé de naissances vivantes pendant l’année considérée, tiré de l’édition 2022 du rapport World Population Prospects17.
Sources de données
On peut établir des estimations de l’insuffisance pondérale à la naissance qui soient représentatives au niveau national à partir d’un ensemble de sources, définies globalement comme étant les données administratives nationales ou les enquêtes sur les ménages représentatives à ce niveau. Les données administratives nationales proviennent des systèmes nationaux, notamment le registre et les statistiques de l’état civil, les systèmes nationaux d’information de gestion en matière de santé et les registres des naissances. Lorsque les enquêtes nationales menées auprès des ménages, telles que les enquêtes démographiques et sanitaires et les enquêtes en grappes à indicateurs multiples, fournissent des informations sur le poids à la naissance ainsi que des indicateurs connexes clés, comme la perception maternelle de la taille à la naissance, elles sont également une source importante de données sur l’insuffisance pondérale à la naissance, notamment dans les contextes où le poids des enfants à la naissance n’est pas enregistré et/ou la tendance à arrondir les données pose problème.
Problèmes et limites
L’une des principales limites du suivi de l’insuffisance pondérale à la naissance à l’échelle mondiale est le manque de données relatives au poids à la naissance de nombreux enfants. À cet égard, il existe un biais notable lié au fait que les enfants nés de mères ou de familles pauvres, ayant un faible niveau d’instruction et vivant en milieu rural auront moins de chances d’avoir été pesés à la naissance que ceux nés de mères plus aisées, ayant fait davantage d’études et vivant en milieu urbain. Près d’une enquête sur trois comprenant des données relatives à l’insuffisance pondérale à la naissance n’a pas été prise en compte, principalement en raison de données manquantes ou de qualité médiocre; ces enquêtes provenaient la plupart du temps de pays à faible revenu situés dans des régions où le risque d’insuffisance pondérale à la naissance est élevé.
Étant donné que les nouveau-nés dont le poids à la naissance n’est pas connu présentent des facteurs de risque d’insuffisance pondérale à la naissance, les estimations qui ne prennent pas en compte ces enfants pourront être inférieures à la valeur réelle. En outre, la qualité médiocre des données disponibles pour les pays à faible revenu ou à revenu intermédiaire, liée à des arrondis excessifs aux multiples de 500 grammes ou de 100 grammes, peut également déboucher sur une sous-estimation de l’insuffisance pondérale à la naissance. Les méthodes appliquées dans la base de données actuelle pour tenir compte des poids manquants et de la tendance à arrondir les données dans les estimations des enquêtes sont censées remédier à ce problème. L’une des limites des méthodes actuelles est l’absence de données au niveau individuel dans les données administratives, et le fait que ces données ne peuvent pas être ajustées directement pour supprimer les biais liés aux arrondis excessifs et aux informations manquantes.
Les regroupements géographiques utilisés dans la modélisation peuvent ne pas être adaptés aux valeurs épidémiologiques ou économiques aberrantes. Au total, ce problème pourrait avoir influé sur les estimations de 37 pays (sur 195) sans données d’entrée. En outre, les seuils de confiance des estimations mondiales et régionales peuvent être artificiellement bas étant donné que près de la moitié des pays modélisés avaient un effet spécifique généré aléatoirement pour chaque prévision bootstrap, positif ou négatif selon le cas, ce qui tend à rendre l’incertitude relative aux niveaux mondial et national moindre qu’au niveau des pays.
Lectures recommandées
Blanc, A. et Wardlaw, T. 2005. Monitoring low birth weight: An evaluation of international estimates and an updated estimation procedure. Bulletin World Health Organization, 83(3): 178-185. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2624216
Chang, K. T., Carter, E. D., Mullany, L. C., Khatry, S. K., Cousens, S., An, X., Krasevec, J. et al. 2022. Validation of MINORMIX approach for estimation of low birthweight prevalence using a rural Nepal dataset. The Journal of Nutrition, 152(3): 872-879. https://doi.org/10.1093/jn/nxab417
Okwaraji, Y. B., Krasevec, J., Bradley, E., Conkle, J., Stevens, G. A., Gatica-Domínguez, G., Ohuma, E. O. et al. 2024. National, regional, and global estimates of low birthweight in 2020, with trends from 2000: a systematic analysis. The Lancet, 403(10431): 1071-1080. https://doi.org/10.1016/S0140-6736(23)01198-4
OMS et UNICEF. 2023. Low birthweight. Dans: UNICEF. [Consulté le 28 avril 2025]. https://data.unicef.org/topic/nutrition/low-birthweight
OMS et UNICEF. 2023. Joint low birthweight estimates. Dans: OMS. [Consulté le 28 avril 2025]. https://www.who.int/teams/nutrition-and-food-safety/monitoring-nutritional-status-and-food-safety-and-events/joint-low-birthweight-estimates
OBÉSITÉ DE L’ADULTE
Définition
Indice de masse corporelle (IMC) ≥ 30,0 kg/m2. L’IMC est le rapport du poids à la taille habituellement utilisé pour classifier l’état nutritionnel des adultes. Il est calculé en divisant le poids corporel en kilogrammes par la taille en mètres élevée au carré (kg/m2). Les individus dont l’IMC est égal ou supérieur à 30 kilogrammes par mètre carré sont considérés comme obèses.
Indicateur
Pourcentage de la population d’individus de plus de 18 ans dont l’IMC est supérieur ou égal à 30,0 kilogrammes par mètre carré, pondéré par sexe et normalisé par âge. Les estimations présentées sont tirées d’OMS (2024)44. La série entière d’estimations est révisée lors de chaque actualisation. Nous invitons les lecteurs à ne pas comparer les séries d’une actualisation sur l’autre.
Méthode
Estimations au niveau des pays
Un modèle de régression hiérarchique bayésien, ajusté à l’aide d’un échantillon de Monte-Carlo par chaînes de Markov (MCMC), avec une inférence effectuée à partir des échantillons MCMC postérieurs, a été appliqué pour estimer les tendances de la prévalence de différentes catégories d’IMC par sexe, âge, pays et année sur la période 1990-2022. Les pays ont été organisés en 20 régions et 8 super-régions, essentiellement en fonction de leur situation géographique et de leur revenu national. Dans la structure hiérarchique du modèle, les estimations des différents pays-années reposaient sur leurs propres données, lorsqu’elles étaient disponibles, et sur les données des autres années pour le pays et d’autres pays, notamment ceux de la même région et super-région disposant de données pour des périodes similaires. Le modèle intégrait les tendances temporelles non linéaires au moyen d’une combinaison de termes de marche aléatoire linéaires et du deuxième ordre, tous modélisés de façon hiérarchique. La relation entre l’âge et l’IMC a été modélisée à l’aide d’une spline cubique pour tenir compte de la structure par âge non linéaire, laquelle peut varier selon les pays. Les coefficients des splines ont été modélisés de manière hiérarchique; ils ont varié au fil du temps pour traduire l’évolution des relations en fonction de l’âge. La normalisation par âge a été réalisée à partir des moyennes pondérées des estimations par âge et par sexe, à l’aide des pondérations en fonction de l’âge de la population type définie par l’OMS20.
Agrégats régionaux et mondiaux
Les estimations mondiales et régionales de la prévalence sont calculées en tant que moyennes pondérées par la population des pays concernés.
Sources de données
Les études en population comprenant des mesures de taille et de poids telles que les enquêtes sur les ménages représentatives au niveau national constituent la majeure partie des sources de données utilisées pour surveiller l’obésité chez l’adulte.
Problèmes et limites
L’IMC donne une mesure imparfaite de l’importance et de la répartition de la graisse corporelle, mais il est largement présent dans les études en population, et il est utilisé dans la pratique clinique; il est également corrélé à l’absorptiométrie biénergétique à rayons X, plus complexe et plus coûteuse.
Certains pays avaient peu de sources de données, et trois n’en avaient aucune. Pour ces pays, les estimations ont été établies dans une large mesure à partir des données d’autres pays au moyen de la hiérarchie des unités géographiques.
On a également constaté des volumes de données différents selon les groupes d’âge: les données plus rares concernant les personnes âgées (≥ 65 ans) ont débouché sur une incertitude plus importante pour ce groupe d’âge.
Lectures recommandées:
Ahmad, O. B., Boschi-Pinto, C., Lopez, A. D., Murray, C. J., Lozano, R. et Inoue, M. 2001. Age standardization of rates: A new WHO standard. GPE Discussion Paper Series 31. Genève (Suisse), OMS. https://cdn.who.int/media/docs/default-source/gho-documents/global-health-estimates/gpe_discussion_paper_series_paper31_2001_age_standardization_rates.pdf
NCD-RisC (NCD Risk Factor Collaboration). 2024. Worldwide trends in underweight and obesity from 1990 to 2022: a pooled analysis of 3663 population-representative studies with 222 million children, adolescents, and adults. The Lancet, 403(10431): 1027-1050. https://doi.org/10.1016/S0140-6736(23)02750-2
Assemblée mondiale de la Santé. 2013. Soixante-sixième Assemblée mondiale de la Santé – Suivi de la Déclaration politique de la Réunion de haut niveau de l’Assemblée générale sur la prévention et la maîtrise des maladies non transmissibles. https://apps.who.int/gb/ebwha/pdf_files/WHA66/A66_R10-fr.pdf
OMS. 2022. Updated Appendix 3 of the WHO Global NCD Action Plan 2013-2030 – Technical Annex (version du 26 décembre 2022). Genève (Suisse). https://cdn.who.int/media/docs/default-source/ncds/mnd/2022-app3-technical-annex-v26jan2023.pdf?sfvrsn=62581aa3_5
OMS. 2024. Portail des données sur les maladies non transmissibles. Dans: OMS. [Consulté le 8 avril 2024]. https://ncdportal.org
OMS. 2024. Nutrition Landscape Information System (NLIS) country profile indicators: interpretation guide. Second edition. Genève (Suisse). https://www.who.int/publications/i/item/9789241516952
OMS. 2024. Données de l’Observatoire de la santé mondiale: Prevalence of obesity among adults, BMI ≥ 30, age-standardized – Estimates by country. [Consulté le 24 juillet 2024]. https://www.who.int/data/gho/data/indicators/indicator-details/GHO/prevalence-of-obesity-among-adults-bmi-=-30-(age-standardized-estimate)-(-). Licence: CC-BY-4.0.
ANÉMIE CHEZ LES FEMMES ÂGÉES DE 15 À 49 ANS
Définition
Pourcentage des femmes âgées de 15 à 49 ans dont le taux d’hémoglobine est inférieur à 120 grammes par litre (pour les femmes qui ne sont pas enceintes ou qui allaitent) ou à 110 grammes par litre (pour les femmes enceintes), après ajustement en fonction de l’altitude et du tabagisme des femmes considérées.
Indicateur
Pourcentage de femmes âgées de 15 à 49 ans dont le taux d’hémoglobine dans le sang est inférieur à 110 grammes par litre pour les femmes enceintes et à 120 grammes par litre pour les femmes qui ne sont pas enceintes. Les estimations présentées sont tirées d’OMS (2025)45. La série entière d’estimations est révisée à la lumière de chaque nouvelle édition de ce rapport. Nous invitons les lecteurs à ne pas comparer les séries d’une édition sur l’autre.
Méthode
Estimations au niveau des pays
Les estimations de 2025 relatives à l’anémie chez les femmes âgées de 15 à 49 ans, enceintes et non enceintes, comprenait des sources de données issues de la base de données sur les micronutriments, qui fait partie du Système d’informations nutritionnelles sur les vitamines et les minéraux de l’OMS, et de données individuelles anonymisées concernant la période 1995-2023. Un ajustement des données sur les taux d’hémoglobine dans le sang a été effectué en fonction de l’altitude (pour les pays ayant des populations vivant à haute altitude) et du tabagisme, chaque fois que possible. Les valeurs non plausibles sur le plan biologique (taux d’hémoglobine < 25 g/l ou > 200 g/l) ont été exclues.
On a utilisé un modèle de mélange hiérarchique bayésien pour estimer les tendances pour chaque pays-année, à partir des données de la paire pays-année considérée, de celles des autres années pour ce pays et de celles d’autres pays de la même région. Dans ce modèle, un poids plus important a été donné aux zones pour lesquelles les données étaient peu nombreuses qu’à celles pour lesquelles on disposait de beaucoup de données. On a modélisé les évolutions comme une tendance linéaire plus une tendance non linéaire lisse, aux niveaux national, régional et mondial. Les estimations reposent aussi sur des covariables telles que l’indice sociodémographique, les disponibilités en viande et la prévalence de l’excès pondéral. On trouvera de plus amples informations sur ce sujet dans le document de référence intitulé WHO standard methodology to estimate SDG 2.2.3 indicator on anaemia prevalence in women 15-49 years, by pregnancy status21.
Pour la présente édition, le traitement des données issues de prélèvements capillaires et de l’analyseur HemoCue® 301 a été renforcé en raison d’erreurs de mesure et de biais potentiels. Les taux moyens d’hémoglobine ont été utilisés pour réduire autant que possible les erreurs liées au sang capillaire, tandis que toutes les données disponibles ont été utilisées pour les analyses de sang veineux. Un indicateur a été ajouté au modèle pour l’analyseur HemoCue® 301 afin de tenir compte des biais soupçonnés dans les mesures de l’appareil et d’améliorer les prévisions relatives à la prévalence de l’anémie.
Cette méthode a permis d’obtenir des estimations cohérentes des taux d’hémoglobine et de la prévalence de l’anémie, à partir des seuils établis par l’OMS en 1989 (< 110 g/l pour les femmes enceintes, < 120 g/l pour les femmes non enceintes)22. Les derniers critères datant de 2024 n’ont pas été utilisés faute de données individuelles suffisantes pour effectuer une nouvelle analyse23, mais des actualisations sont en cours pour le prochain cycle, et tiendront compte des seuils à jour.
Agrégats régionaux et mondiaux
Les estimations mondiales et régionales de la prévalence sont calculées en tant que moyennes pondérées par la population des pays concernés.
Sources de données
Les études en population constituent la source de données privilégiée. Les données issues des systèmes de surveillance peuvent être utilisées dans certains cas, mais on constate en général une sous-estimation des diagnostics enregistrés. La base de données sur les micronutriments24 du Système d’informations nutritionnelles sur les vitamines et les minéraux de l’OMS regroupe et synthétise les données sur les apports en micronutriments des populations à partir de diverses autres sources, y compris des données collectées dans les travaux scientifiques publiés et par le truchement de collaborateurs tels que les bureaux régionaux et les bureaux de pays de l’OMS, les organisations des Nations Unies, les ministères de la santé, les établissements universitaires et les établissements de recherche, ou les organisations non gouvernementales. En outre, des données individuelles anonymisées sont récupérées dans des enquêtes multinationales, notamment des enquêtes démographiques et sanitaires, des enquêtes sur les indicateurs de paludisme et des enquêtes sur la santé de la reproduction.
Problèmes et limites
Malgré la proportion importante de pays disposant de données sur l’anémie issues d’enquêtes nationalement représentatives, la communication des informations relatives à cet indicateur est encore lacunaire, notamment dans les pays à revenu élevé. Par ailleurs, seules les sources dont la méthode de mesure était connue ont été prises en compte pour cette série d’estimations. En conséquence, les estimations peuvent ne pas rendre pleinement compte de la variation entre pays et entre régions, et tendent simplement à se resserrer autour des moyennes mondiales quand les données sont rares.
Lectures recommandées
Stevens, G. A., Paciorek, C. J., Flores-Urrutia, M. C., Borghi, E., Namaste, S., Wirth, J. P., Suchdev, P. S., Ezzati, M., Rohner, F., Flaxman, S. R. et Rogers, L. M. 2022. National, regional, and global estimates of anaemia by severity in women and children for 2000-19: a pooled analysis of population-representative data. The Lancet Global Health, 10(5): e627–e639. https://doi.org/10.1016/S2214-109X(22)00084-5
OMS. 2011. Concentrations en hémoglobine permettant de diagnostiquer l’anémie et d’en évaluer la sévérité – Système d’informations nutritionnelles sur les vitamines et les minéraux. Genève (Suisse). https://iris.who.int/bitstream/handle/10665/85841/WHO_NMH_NHD_MNM_11.1_fre.pdf?sequence=7&isAllowed=y
OMS. 2014. Plan d’application exhaustif concernant la nutrition chez la mère, le nourrisson et le jeune enfant. Genève (Suisse). https://www.who.int/fr/publications/i/item/WHO-NMH-NHD-14.1
OMS. 2025. Global nutrition Targets 2030 to improve maternal, infant and young child nutrition. Dashboard. Dans: OMS. [Consulté le 6 juin 2025]. https://data.who.int/dashboards/nutrition?m49=004
OMS. 2025. Nutrition Data Portal. Dans: OMS. [Consulté le 8 mai 2025]. https://platform.who.int/nutrition/nutrition-portals
OMS. 2025. Vitamin and Mineral Nutrition Information System (VMNIS). Dans: OMS. [Consulté le 8 mai 2025]. https://www.who.int/teams/nutrition-and-food-safety/databases/vitamin-and-mineral-nutrition-information-system
OMS. 2025. WHO global anaemia estimates, 2025 edition. Dans: OMS. [Consulté le 8 mai 2025]. https://www.who.int/data/gho/data/themes/topics/anaemia_in_women_and_children
OMS. 2025. WHO standard methodology to estimate SDG 2.2.3 indicator on anaemia prevalence in women 15-49 years, by pregnancy status. 2000-2023. Genève (Suisse). [Consulté le 6 juin 2025]. https://www.who.int/teams/nutrition-and-food-safety/monitoring-nutritional-status-and-food-safety-and-events/global-anaemia-estimates/methodology-for-the-global-anaemia-estimates


