![]()
![]()
Part A: Statistical analysis of on-farm trials
Part B: Financial analysis of on-farm trials
References
This module provides a brief outline of the methods most commonly used to analyse data obtained from on-farm trials. It is broken into parts A and B.
Part A, entitled 'Statistical analysis of on-farm trials', discusses methods of analysis applicable to data obtained from statistical trials. Module 11 (Section 1) and Putt et al (1987) complement the material given here.
Part B, entitled 'Financial analysis of on-farm trials', discusses methods used to appraise the financial attractiveness of technologies introduced at the farm level. These methods are applicable to the analysis of data obtained from both statistical and monitoring trials.1
1 The terms 'statistical' and monitoring' trials are defined in Module 2 of this section.
The paired t-test
Analysis of variance (ANOVA)
One-way analysis of variance
Analysis of variance for a randomised block design
Detailed treatment comparisons
Quantitative treatments
Presentation of results
ANOVA and factorial experiments
Unbalanced data
When there are only two groups of animals being compared in an on-farm trial (e.g. a control and a treated group), differences in mean production performance can be tested by using the ordinary t-test which is described in Part B of Module 11 (Section 1).
The statistical sensitivity of the tests being carried out can be greatly improved if animals are paired so that, within each pair, they are as alike as possible at the outset. One animal in each pair is then assigned at random to one group, and the other animal is assigned to the other group. This is analogous to 'blocking' which was described in Module 2 of this section. The paired t-test can then be used to make comparisons between groups.
|
Example: In an on-farm feeding trial, two groups of 10 lambs were identified and paired on the basis of age, weight, sex and parity. Lambs from each pair were then allocated to a control and a treated group, respectively, and their weights at three months were compared. The results of the trial are summarised in Table 1 below: |
Table 1. Mean liveweights of lambs in treated and control groups.
|
Pair |
Mean liveweight (kg) |
Difference (d) |
|
|
Treated |
Control |
||
|
1 |
12.2 |
11.4 |
0.8 |
|
2 |
10.4 |
10.6 |
-0.2 |
|
3 |
10.8 |
9.6 |
1.2 |
|
4 |
11.8 |
10.4 |
1.4 |
|
5 |
12.6 |
12.8 |
-0.2 |
|
6 |
12.0 |
12.6 |
-0.6 |
|
7 |
11.4 |
10.2 |
1.2 |
|
8 |
10.2 |
9.6 |
0.6 |
|
9 |
12.4 |
10.2 |
2.2 |
|
10 |
11.8 |
10.0 |
1.8 |
|
Mean |
11.56 |
10.74 |
0.82 |
|
SD |
0.84 |
1.16 |
0.92 |
|
These data could be analysed (inefficiently) by the ordinary t-test,
as follows: (1)
The standard error of the difference (SED), which is defined in Part B of Module 11 (Section 1), is calculated from the standard deviations (SDs) for the treated and control groups. In this example, SED = 0.451 and the t-test is: t = (11.56 - 10.74)/0.451 = 1.82 This value is compared with the tabulated value for 18 (n - 2) degrees of freedom, which is 2.10 at the 95% confidence level (Table 10, Module 11, Section 1). The calculated value (1.82) is smaller than 2.10, i.e. there is a more than 1 in 20 chance that such a value of t could arise in cases where samples are taken from the same population, and so we cannot conclude that the treatment affects the weight of lambs. The difference is not statistically significant. A 95% confidence interval for the difference can be calculated as: (2) Difference ± t. SED i.e. (11.56 - 10.74) ± (2.10 x 0.451) i.e. 0.82 ± 0.95 or -0.13 to 1.77 so the effect of treatment could be anything between decreasing lamb weight by 0.13 kg to increasing it by 1.77 kg. (The fact that the confidence interval includes the value zero is equivalent to the statement that the difference is not statistically significant, i.e. zero is a likely value of the difference). However, since the animals were paired before the trial had begun, a more efficient analysis is possible by making comparisons for each pair. This eliminates variation from pair to pair. The way to do this is to calculate: · the difference for each pair as in the last column of Table 1 Note that the minus signs are important here, · the mean and standard deviation of these differences Note that the mean of the differences is the same as the difference between the two scans (both equal 0,82 in this example). The next step is to calculate the standard error of the difference
(SED) as: (3)
where: s = the standard deviation of the differences, and In our case, s = 0.92 and n = 10, giving: SED = 0.92/ The formula for the t-test is exactly as before
except now the standard error of the difference is calculated differently, i.e. t = 0.82/0.291 = 2.82. The tabulated value for n-1 degrees of freedom (= 9 df) at, say, the 5% level is 2.26. Our calculated value (2.82) is larger than 2.26, indicating that the difference is larger than would be expected if there was no treatment effect. Therefore, the difference is statistically significant. Again, we can calculate a 95% confidence interval for the difference, as follows: Difference ± t.SED which is (11.56 - 10.74) ± (2.26 x 0.291) i.e. 0.82 ± 0.66 The main difference between the paired and the unpaired case above is that the standard error of the difference is now much smaller (0.291 compared to 0.451). The smaller the standard error, the narrower the confidence interval and the more precisely a difference is estimated. So, by taking the pairing into account, we have dramatically improved the precision of our estimate. The tabulated t-value has also changed (from 2.1 to 2.26), but this is only important for very small samples. |
The above example helps to demonstrate the gains in efficiency which can be achieved when experiments are carefully planned and designed. By removing some potential sources of random variation at the outset, the benefits (or otherwise) of an introduced technology can often be more clearly ascertained.
However, pairing does have its difficulties, the two major ones being that, in traditional production systems, it is not always easy to obtain:
· animals with similar characteristicsDifficulties of this nature are likely to be more pronounced with cattle than with small ruminants (Module 2 of this section).· the sort of information required for efficient pairing
For instance, farmers are not always sure about parity' type of birth, stage of lactation etc. Age is more easily determined (module 5, Section 1).
The t-test can be used to compare the performance of two groups of trial animals, subjected to different treatments (e.g. two levels of feed supplementation). When several treatments are involved, real differences in performance between groups can be tested by using the analysis of variance (ANOVA) technique.
Many statistical textbooks (e.g. Cochran and Cox, 1957; Dagnelie, 1975; Snedecor and Cochran, 1980; Steel and Torrie, 1980; Mead and Curnow, 1983; Gomez and Gomez, 1984) cover this topic. In particular, Gomez and Gomez (1984) give step-by-step details of the necessary calculations, while Cochran and Cox (1957) discuss more complex cases in addition to the basic ones.
The basic principles involved in the use of the ANOVA technique can be best explained by use of examples. The example which follows is taken from ILCA (1989a, Module 3).
|
Example: Assume that 5 groups of six sheep were identified for a feed supplementation trial. The objective of the trial was to test whether protein supplementation increases wool production. Each group of animals received one of the following treatments: Treatment 1: natural grazing (control) After completion of the trial, wool yields for the different treatment groups were as given in Table 2. |
Table 2. Wool yields of sheep under different feed supplementation regimes.
|
|
Wool yields (kg) for treatment group: |
||||
|
1 |
2 |
3 |
4 |
5 |
|
|
|
2.4 |
2.8 |
3.0 |
3.2 |
3.3 |
|
4.1 |
2.9 |
5.1 |
4.5 |
4.5 |
|
|
2.9 |
2.4 |
3.5 |
3.6 |
4.1 |
|
|
2.3 |
3.8 |
3.9 |
3.7 |
4.2 |
|
|
2.6 |
2.4 |
2.9 |
2.1 |
2.6 |
|
|
3.2 |
3.7 |
4.4 |
3.9 |
4.7 |
|
|
Treatment total (Ti) |
17.5 |
18.0 |
22.8 |
21.0 |
23.4 |
|
Mean |
2.9 |
3.0 |
3.8 |
3.5 |
3.9 |
|
The results suggest that supplementation may have had a beneficial effect on wool production, but the ANOVA technique is needed to determine whether the differences are real or whether they could be due only to sampling variation. To determine this, factors causing variation between the different animals in the trial must be separated. In a one-way ANOVA, total variation is said to result from: · treatment effects i,e. the performance of animals nay differ because of different treatments having different effects. · residual effects i.e. the performance of animals nay differ because of unexplained (or unmeasured) influences (e.g. genetic differences). We can say, loosely, that: (4) Total variation - variation due to treatments t residual variation The ANOVA technique uses formulae to partition the total variation into these two components. If there is no difference between the treatments, the variation due to treatments will be purely random variation, and therefore similar to the residual variation. If there are differences between the treatments, then the treatment variation will be larger than the random variation. Variation is measured in terms of a 'mean square', which is another term for variance. The first step is to calculate 'sums of squares'. The total sum of squares and treatment sum of squares are calculated directly from the data, and the residual sum of squares is then calculated from these two figures. Each sum of squares has an associated degree of freedom, and the mean squares (ms) are then calculated as:
(5) If we denote an individual measurement by y and the total number of experimental units N (animals, in our case), the total sum of squares (ss) is: Total ss = (6) Using the data in Table 2, N = 30, and therefore (S y)2/N = 102.72/30 = 351.58, and S y2 = 2.42 + 2.82 +... + 3.92 + 4.72) = 370 61 therefore Total sum of squares = 370.61 - 351.58 = 19.03 Note: Sums of squares must always be positive numbers. The treatment sum of squares (ss) is calculated from the totals for each treatment. If Ti is the total for treatment i and ni is the number of units (animals) receiving that treatment, then:
(7) The second term on the right-hand side of equation 7, (S y)2/N, has already been calculated above as 351.58. Using the totals for each treatment (Ti) which are given in Table 2, and if ni has the value 6 for all treatments, then:
and Treatment ss = 356.44 - 351.58 = 4.86 When the total and treatment sums of squares are known, we can calculate the residual sum of squares as: Residual ss = total ss - treatment ss (8) = 19.03 - 4.86 = 14.17 If Total degrees of freedom = N - 1 = 29 (9) Treatment df = number of treatments - 1 (10) = 5 - 1 = 4 then Residual df = total df - treatment df (11) = 29 - 4 = 25 Mean squares (ms) are then calculated as: ms = (sum of squares)/df (12) and are given in Table 3 overleaf. |
Table 3. Conventional analysis of variance table for an on-farm sheep supplementation trial.
|
Source of variation |
df |
Sun of squares (ss) |
Mean square (ms) |
F-value |
|
Treatments |
4 |
4.86 |
1.215 |
2.14 |
|
Residual |
25 |
14.17 |
0.567 |
|
|
Total |
29 |
19.03 |
|
|
|
The F-value is calculated as follows:
If there are no differences between the five treatments, the variation between treatments (as measured by the treatment mean square) will be due only to random variation. We would then expect the treatment mean square to be similar to the residual mean square which also measures random variation. Therefore, the F-value should be close to 1.0. On the other hand, if there are treatment differences, the treatment mean square will be larger than the residual mean square and so the F-value will be considerably larger than 1.0. To test for a significant treatment effect, the calculated F-value is compared with tabulated values. Tables 4 and 5 give these values for the 5% and 1% levels. The tabulated value depends on both the treatment and residual degrees of freedom (4 and 25, respectively, in this example). From Table 4, the F-value for our example is 2.76 at the 5% level. The calculated value (2.14) is smaller than the tabulated value (2.76) and, therefore, we cannot conclude that the treatments are different; the observed variation between treatments could be due simply to random variation. |
Table 4: Percentage points of the F distribution: Upper 5% points.
Note: It is important to look up the table in the correct direction; treatment df is the column across the top of the table, while residual df is the row at the side of the table.
Table 5: Percentage points of the F distribution: Upper 1 % points.
Note: Treatment df is the column across the top of the table, while residual df is the row at the side of the table.
By blocking on the basis of characteristics such as age, sex, weight or parity, estimates of treatment differences can be made more precise and significance tests more sensitive (Module 2, Section 2).
|
Example: Suppose that the researcher in the sheep supplementation trial had, in fact, decided to block animals on the basis of weight, because it is known that weight affects wool production. This means that the five heaviest animals had been randomly assigned to the five treatments. The five next heaviest animals were similarly assigned, and so on. It should then be possible to determine the effect of feed supplementation more precisely, since much of the variation due to differences in body weight are eliminated. The grouping of the animals on the basis of weight is shown in Table 6. Note that, unlike in the one-way analysis of variance, we now need to have the same number of animals in each treatment group. |
Table 6. Wool yields (kg) of sheep under different feed supplementation regimes when blocked on the basis of pre-trial body weight.
|
Weight group |
Treatment |
Block totals (Bj) |
||||
|
1 |
2 |
3 |
4 |
5 |
||
|
1 |
2.4 |
2.8 |
3.0 |
4.5 |
3.3 |
14.7 |
|
2 |
4.1 |
2.9 |
5.1 |
4.5 |
4.5 |
21.1 |
|
3 |
2.9 |
2.4 |
3.5 |
3.6 |
4.1 |
16.5 |
|
4 |
2.3 |
3.8 |
3.9 |
3.7 |
4.2 |
17.9 |
|
5 |
2.6 |
2.4 |
2.9 |
2.1 |
2.6 |
12.6 |
|
6 |
3.2 |
3.7 |
4.4 |
3.9 |
4.7 |
19.9 |
|
Treatment totals (Ti) |
17.5 |
18.0 |
22.8 |
21.0 |
23.4 |
|
|
Means |
2.92 |
3.00 |
3.80 |
3.50 |
3.90 |
|
|
For this analysis, the only additional steps are to calculate the block sum of squares and mean square, and then recalculate the residual sum of squares and mean square. If Bj is the total for block j, and t is the number of animals in each block (which must be the same as the number of treatments), then:
(14) The second term on the right-hand side of equation 14, (S y)2/N, has already been calculated as 351.58. Using the totals for each block (Bj) which are given in Table S. and if t = 5, then the first term on the same side of the equation is: S and Block sum of squares = 361.75 - 351.58 = 10.17 The new residual sum of squares (ss) is: (15) Residual ss = total ss - block ss - treatment ss and, therefore, the residual for degrees of freedom is: (16) Residual df = total df - block df - treatment df where block df = number of blocks - 1 These calculations are summarised in Table 7 overleaf. |
Table 1. Analysis of variance table for an on-farm sheep supplementation trial With animals blocked by weight.
|
Source variation |
df |
Sum of squares (ss) |
Mean square (ms) |
F-value |
|
Blocks |
5 |
10.17 |
2.034 |
- |
|
Treatments |
4 |
4.86 |
1.215 |
6.09 |
|
Residual |
20 |
4.00 |
0.200 |
- |
|
Total |
29 |
19.03 |
|
|
|
Note that the most important effect of blocking was to reduce the residual mean square from 0.567 in the one-way analysis to 0.200. Since the residual mean square is a measure of the random variation, and the precision of treatment comparisons depends on its value, blocking has increased the precision of the experiment. This is reflected in the F-value for treatments which is 6.09. The tabulated value (Table 4) for 4 and 20 df is 4.43 at the 1% level. The variation between treatments (ms = 1.215) is much larger than the random variation (ms = 0.200) and, therefore, the treatment differences are statistically significant. |
The residual mean square is, in fact, the variance of the data after removing all treatment and block effects. It is often called the residual variance (s2) J. and its square root, a, is referred to as the residual standard deviation.
The one-way analysis was carried out purely for the purposes of demonstration, to compare it with the randomised block analysis. In practice, only the randomised block analysis would have been done, since the animals had been 'blocked' by weight in the original experimental design. If this had not been done, the one-way analysis would have been the correct one. This emphasises the point that good experimental design can increase the precision of an experiment for little or no extra cost.
In the above analyses, the F-test examines whether or not there are significant differences between treatments. If significant differences are detected, the F-test gives no information about where the differences are occurring.
In order to obtain this information it is necessary to calculate first treatment means (if not already calculated). In our case, these are given in Table 6. Once treatment means are available, any two of them can be compared by using a t-test, though this may give rise to the problems of interpretation discussed below. Confidence intervals can also be obtained as in Part B of Module 11 (Section 1).
The standard error of the difference between two treatment means (SED) is defined as follows:
(17)
where:
s2 = the residual variance (mean square), and
n1, n2 = the numbers of observations in each mean.
If, as in our example, all means have the same number of observations, n, then equation (17) simplifies to:
(18)
For instance, if n 6 (i,e. there were 6 sheep in each treatment group), and s2=0.200 (the residual mean square from Table 7), then:
The standard formula for a confidence interval can now be used, i.e.
Difference ± t.SED
(19)
where t is the tabulated value.
The degrees of freedom for this l-value are the residual degrees of freedom from the analysis of variance. (This is because the variance estimate used to calculate the SED is the residual mean square with these degrees of freedom).
For instance, the tabulated l-value with 20 degrees of freedom at the 5% level is 2 09, therefore a 95X confidence interval for any treatment difference is:Difference ± (2.09 x 0.258) = difference ± 0 54
In our trial With sheep, treatment 2 is grazing t extra maize (mean wool yield 3.00 kg) and treatment 3 is the same with protein supplement S1 (mean wool yield 3 80 kg) The difference between these treatments (0.80 kg) represents the effect of protein supplement S1 A confidence interval for this difference is:
0 80 ± 0 54 or 0 26 kg to 1.34 kgSo we can state that, at the 95% confidence level, the protein supplement S1 increases wool yield by between 0 26 and 1 34 kg
A t-test gives a similar, but more limited, conclusion. A l-value can be calculated using the usual formula:
(20)
Since the calculated l-value is larger than the tabulated value (2.09), the difference is larger than would be expected by chance alone, and so is statistically significant.
To avoid calculating a number of t-values and comparing them with tables, the above formula can be inverted. A difference will be statistically significant if:
(from the tables)
(21)
This is equivalent to:
Difference > t.SED
(22)
Equation (22) gives the least significant difference (LSD).
In our example, SED = 0.258 and t is 2 09 (from tables for 20 df at the 5% level). Therefore, the LSD at 5% level is 2.09 x 0.258 = 0.54, i.e. any treatment difference larger than 0.54 is statistically significant at the 5% level.
There is a potential problem with t-tests and the equivalent LSDs if a rigorous approach is not adopted to tests of statistical significance.
For instance, in our example with five treatments there are 10 possible differences which could be tested (treatment 1 vs treatment 2, treatment 1 vs treatment 3, treatment 1 vs treatment 4 treatment 2 vs treatment 5 etc). With seven treatments, there would be 21 possible differences, with 10 treatment 45 differences, and with 15 treatments 105 differencesThe nature of a significance test at the 5% level is that if there is no genuine difference, the test will erroneously indicate significant differences in 5% of cases (i.e. one time in 20) From this it can be seen that even with seven treatments, the problem of spurious statistical significance is serious A t-test comparing the best treatment with the worst is quite likely to be taken as significant, even when there is no genuine difference
If there are treatment comparisons which are specified before the experiment or are obvious from the nature of the treatments (pre-defined comparisons), then there is no real problem.
|
Example: In our trial with sheep (see page 6), obvious comparisons would be: Treatment 1 vs treatment 2, the difference representing the effect of extra maize. Treatment 3 vs treatment 2, the difference representing the effect of protein supplement S1 Treatment 4 vs treatment 2, the difference representing the effect of protein supplement S2, and Treatment 5 vs treatment 2, the difference representing the effect of protein supplement S3. |
Another comparison of interest may be the mean of treatments 1 and 2 compared with the mean of treatments 3, 4 and 5. This compares the treatments with protein supplementation versus those without supplements. The comparison is straightforward, involving the calculation of an appropriate SED, using the general formula:

|
Example: If we have 6 animals per treatment group, the mean of treatments 1 and 2 is calculated from 12 animals, and so n1 is 12. Similarly, n2 is 18 for the mean of three treatments. The residual mean square (s) in Table 7 is 0.200, and so: SED = [0.200 x (1/12 + 1/18)] = (0.200 x 0.139) = 0.167 This figure can then be used for confidence intervals or t-tests in the usual way. |
Such statistical comparisons should only be used to examine pre-planned comparisons; they should not be used indiscriminately to see if any significant differences can be found between any treatments. This is because they are meant to assist scientific thinking, not to replace it'
In some trials, the treatments may be different levels of the same factor, e.g. a feed supplement, as shown below:
Treatment 1: unsupplemented control
Treatment 2: supplement providing 25% of estimated crude protein (CP) requirement
Treatment 3: supplement providing 50% of estimated CP requirement
Treatment 4: supplement providing 75% of estimated CP requirement, and
Treatment 5: supplement providing 100% of estimated CP requirement.
Here, there are five levels (0, 25, 50, 75 and 100) of a single supplement, which differs from the previous example in which the five treatments were five different diets. Obviously in such a trial, the overall response to supplementation is of interest, and comparisons such as 'treatment 2 vs treatment 4' are irrelevant.
The analysis of variance can be used as before, but, in addition, other more powerful tests can be carried out to detect trends due to treatment level. Details of such tests can be found in most good statistics textbooks, often under the intimidating heading 'Orthogonal polynomials'.
Basically, the use of orthogonal polynomials is the same as using a regression analysis of response (e.g. weight gain) on a level of treatment. (See Module 11 in Section 1 for a description of regression analysis). The technique can detect linear trends and also test for non-linearity. And since it is looking for particular kinds of treatment effect, it is more powerful and sensitive than the general F-test.
When presenting results in a report or scientific paper, it is not usually necessary to include the analysis of variance table. All that is necessary is:
· treatment means· a measure of the precision (e.g. the standard error of the difference, SED) or the least significant difference (LSD)), and
· an indication of statistical significance.
Table 8 gives the result of the randomised block trial with 6 sheep per treatment, using the above three elements.
Table 8. Average wool yields for sheep on different feed supplementation regimes.
|
Treatment |
Wool yield (kg) |
|
Natural grazing |
2.92 |
|
Grazing + extra maize |
3.00 |
|
Grazing + maize + S1 |
3.80 |
|
Grazing + maize + S2 |
3.50 |
|
Grazing + maize + S3 |
3.90 |
|
SED (20 df) |
0.258 |
|
F-test significance |
P<0.01 |
The merits of using a factorial design in on-farm experimentation have been discussed in Module 2 of this section. As already stated, the main advantage of factorial experiments is that interactions between the different factors can be examined in an ANOVA, and this is demonstrated by the example below which was taken from ILCA (1989a, Module 3). The calculations of sums of squares, mean squares and standard errors follow the general principles described for the randomised block design above.
|
Example: A trial was set up to examine the effect of water and nutrition on calf growth. Three watering regimes and two energy sources (local forage and sugar-cane residue) were used. This gave six treatment groups to each of which five animals were allocated. The mean weight gains during the trial period are shown in Table 9, together with standard error of the differences and statistical significance. The analysis of variance is given in Table 10. |
Table 9. Mean weight gains of calves under different feeding and watering regimes.
|
Treatment |
Energy source |
Watering regime |
Mean weight gain (g LW/day) |
|
1 |
local forage |
1 |
119.6 |
|
2 |
local forage |
2 |
138.6 |
|
3 |
local forage |
3 |
143.2 |
|
4 |
sugar-cane residue |
1 |
36.6 |
|
5 |
sugar-cane residue |
2 |
71.4 |
|
6 |
sugar-cane residue |
3 |
57.0 |
|
SED (24 df) |
|
|
9.55 |
|
Significance of energy source |
P<0.001 | ||
|
Significance of watering regime |
P<0.01 | ||
|
Significance of energy x watering |
n.s. | ||
1 n.s. = not significant.
Table 10. Analysis of variance of can weight gain.
|
Source of variation |
df |
Sum of squares |
Mean square |
F statistic |
|
Main effect of energy source |
1 |
46571 |
46571 |
204 |
|
Main effect of watering regime |
2 |
4105 |
2053 |
9.0 |
|
Energy x watering |
2 |
517 |
259 |
1.1 |
|
Residual |
24 |
5482 |
228 |
|
|
Total |
29 |
56 |
675 |
|
|
In a factorial experiment, the total variation is partitioned into components due to treatment and the residual. (If the trial had been blocked at the design stage, there would also be a component for blocks). In our case, total variation (29 df) was partitioned into variation due to treatment (5 df) and the residual (24 df). The treatment component can now be further partitioned into the following components: · main effect of energy source (1 df), which represents a comparison between local forage and sugar-cane residue (averaged over the three watering regimes) · main effect of watering regime (2 df), which represents a comparison among the three watering regimes (averaged over the two energy sources) · interaction between energy source and watering regime (2 df), which tests whether the effects of energy source and watering are independent of each other. If there is no interaction, then the difference between the two energy sources is the same for each watering regime. (Conversely, the differences between the watering regimes would be the same for each energy source.) The statistical significance of these components can now be assessed by comparing the calculated F values with those tabulated for the relevant degrees of freedom. The F-test statistics for each component are given in Table 10. To give an example, the F-test statistic for the main effect of watering regime is calculated using the formula:
which, in effect, is the ratio of the variation between the scans of the three watering regimes and the random variation. If watering regime bad no effect on "eight gain, the only variation between the three means would be purely random variation. In such a case, the watering regime seen square would be similar to the residual mean square, and so the calculated P-value would be close to 1 If, on the other hand, watering regime affects weight gain, then the variation between the three watering regime scans will be considerably larger than random variation, i.e the calculated P-value "ill be larger than 1. The tabulated F-values for the main effect of energy source is: F (1 and 24 df) at the 0.1% level = 14.03 and the values for the effect of watering regime or the interaction are: F (2 and 24 df) at the 5% level = 3.40 The tabulated F-values tell us how large the calculated F-values have to be before we can be confident that the effects are genuine and not just due to random variation. In this example, the calculated F-value for the main effect of watering regime is 9.00 and the tabulated value at the 1% level is 5.61. We can, therefore, say that the main effect of watering regime is statistically significant (P<0.01). Having done an F-test, we may be interested in more detailed treatment comparisons. Standard errors and confidence intervals can be calculated in the usual manner (see pages 16-17), using the residual mean square which, in our example, was s2 = 228 with 24 degrees of freedom. The standard error of the difference between two individual treatment means (each based on five animals) is:
The least significant difference (using t with 24 df at 5% level = 2.06) is: LSD = t.SED = 2.06 x 9.55 = 19.7 Therefore, using the treatment means in Table 9 we can conclude that: · local forage gives higher weight gains than sugar-cane residue (for all watering regimes), and · watering regimes 2 and 3 give higher weight gains than regime 1 (for both energy sources). |
In the above experiment there was no significant interaction effect, though the effects of both energy source and water regime were statistically significant. However, interactions can often have significant effects in factorial experiments, and when this occurs, it can be misleading to put much emphasis on main effects. This is because the main effect is the effect of one factor averaged over the level of the other factor(s). In contrast, when the interaction is significant, the effect of the factor depends on which level of the other factor(s) is being considered. An average effect may, therefore, be of limited use.
|
Example (ILCA, 1989a, Module 3): A trial was set up to determine the crude protein (CP) concentration of dry matter at three levels of fertiliser application used in combination with four legume/grass seed mixtures. In this example, both of the main effects and the interaction are significant (Table 11). |
Table 11 Analysis of variance for crude protein concentration of dry matter.
|
Source of variation |
df |
Sum of squares |
Mean square |
F statistic |
Significance level |
|
Main effect of fertiliser level |
2 |
66.3 |
33.2 |
13.94 |
P<0.001 |
|
Main effect of seed mixture |
3 |
1721.5 |
573.8 |
241.10 |
P<0.001 |
|
Fertiliser x mixture |
6 |
69.1 |
11.6 |
4.88 |
P<0.01 |
|
Residual |
12 |
28.5 |
2.38 |
|
|
|
Total |
23 |
1886.0 |
|
|
|
|
Let us now examine the treatment means in more detail. First, it is useful to calculate standard errors of differences and least significant differences using the same procedure as described for the randomised block analysis. The calculations are all based on the residual mean square (s) which, in our example, is 2.38 with 12 degrees of freedom. The standard error for the difference is calculated as: SED= where n is now the number of individual observations (plots) making up the means. Thus, in our trial: n = 8 for fertiliser means In other words, each individual treatment mean is the mean of two plots and, for instance, each fertiliser mean is the mean of four individual treatment means, and, therefore, the mean of eight plots. Therefore, SED for comparing fertiliser means is: SED = The t-value for 12 df at the 6% level is 2.18 and so the least significant difference for fertiliser means is: LSD = t.SED = 2.18 x 0.77 = 1.67 Table 12 below gives mean CP concentrations under different treatments together with the relevant LSDs. |
Table 12. Mean crude protein concentration of dry matter.
|
Seed mixture |
Fertiliser level |
Mean |
||
|
F1 |
F2 |
F3 |
||
|
g/kg DM |
||||
|
M1 |
7.0 |
8.0 |
6.5 |
1.1 |
|
M2 |
8.0 |
8.0 |
9.5 |
8.5 |
|
M3 |
16.0 |
16.0 |
22.0 |
18.0 |
|
M4 |
26.5 |
24.5 |
33.5 |
28.2 |
|
Bean |
14.4 |
14.1 |
11.9 |
15.5 |
LSD at 5% significance level for:
fertiliser means - 1.67
seed mixture means = 1.94
individual means - 3.36
|
Comparing the means for the three levels of fertiliser application, we can see that F3 (with a mean of 17.9) is higher than the other two fertiliser means (14.4 and 14.1). Since the LSD is 1.67, the difference between two fertiliser means has to be larger than 1.67 to be statistically significant. (This is averaged over the four seed mixtures). Similarly, the mean for seed mixture 4 (M4) is higher than the M3 mean which, in turn, is higher than the M1 and M2 means. There is no significant difference between M1 and M2. (These comparisons are averaged over the three fertiliser levels). However, because the interaction is significant, the situation is slightly more complicated. Examining the individual treatment means, we can see that, with LSD = 3.4, there is no fertiliser effect for seed mixtures 1 and 2, and that F3 gives much higher protein content than F1 and F2. |
There is no routine method to determine which treatments give rise to a significant interaction. Often than not, it is a matter of examining the table of means and their LSDs, and of determining how the response to one factor depends on the level of the other factor. Sometimes, simple graphs can be helpful, as can be seen from Figure 1. Separate lines are given for each fertiliser level, and each line shows how protein content depends on the seed mixture for that fertiliser level. A small bar also shows the 5% LSD.
Figure 1. Graphical display of interaction.

The overall effect of seed mixture is obvious from the rise in all the lines from M2 to M4. The lines for F1 and F2 are very similar. The line F3, however, while being the same for M1 and M2, is different for M3 and M4. This suggests that while there was no fertiliser effect for seed mixtures M1 and M2 with F3, there was an effect with M3 and M4 which, in addition, was greater than with the other two fertiliser levels. If there were no interaction, the three lines would be parallel.
In all the analyses of variance described above, the experiments have been 'balanced', i.e. every treatment was applied to the same number of experimental units (animals or plots). In general, it is best to design experiments in this way, since balanced designs make the most efficient use of experimental resources and are more straightforward to interpret.
In practice, however, experiments are often unbalanced, particularly in the case of animal experiments on-farm. This can arise from a number of causes:
· There may not be the right number of animals (or farmers) available at the start of the trial for equal replication, but it may be desirable to use all rather than eliminate some from the trial.· In a survey, as opposed to a designed experiment, the researcher will not have control over the number of animals or households in each group.
· There may be good scientific reasons for having more animals on some treatments than on others.
· Animals may die during the trial, from reasons unrelated to the treatments.
· Farmers may stop participating in the trial, for reasons unrelated to the treatments.
In the last two cases, we would have problems interpreting the results if the reasons for dropping out were dependent on the treatments.
For instance, in a trial carried out to examine the effect of parasite control on weight gains it may happen that more animals die in the untreated group than in a group receiving a positive treatment. Analysing the data for surviving animals would, in this case, ignore the effect of the treatment on the mortality rate (which nay be one of the major benefits of treatment) and the treatment comparisons could be severely biased.
Even without this problem, analysing unbalanced experiments is problematic. Firstly, one would need a sophisticated statistical analysis programme to analyse results from such experiments. Secondly, even with suitable computing facilities, the interpretation is not straightforward, and presentation of results in a concise form is not always possible.
It is beyond the scope of this manual to go into the details of such analyses, and most of the textbooks which cover this subject have a strong mathematical orientation. Nevertheless, an artificial example from Snedecor and Cochran (1980) is given below to illustrate the main problem.
|
Example: Imagine a feeding trial with male and female animals under two diets. The number of animals in each of the four groups and the total weight gains per group are given in Table 13. (The data are artificial) |
Table 13. Total weight gains by diet and sex: Unbalanced experiment.
|
|
Weight gain (g LW/day) |
|||
|
Female |
Male |
Total |
Mean |
|
|
Diet 1 |
||||
|
Total weight gain |
160 |
60 |
220 |
22 |
|
(Number of animals |
8 |
2 |
10) |
|
|
Diet 2 |
||||
|
Total weight gain |
30 |
200 |
230 |
23 |
|
(Number of animals |
2 |
8 |
10) |
|
|
Total |
||||
|
Total weight gain |
190 |
260 |
450 |
|
|
(Number of animals |
10 |
10 |
20) |
|
|
Mean weight gain |
19 |
26 |
22.5 |
|
|
While there are 10 animals on each diet and 10 of each sex, the trial is still unbalanced. Diet 1 has eight females and two males, and this ratio is reversed for Diet 2. The simple mean weight gain for the 10 animals receiving Diet 1 is 22 (220/10), and for Diet 2 it is 23, suggesting that Diet 2 is (slightly) better than Diet 1. This suggestion is misleading and wrong. The mean weight gains per animal for all four groups are given in Table 14. |
Table 14. Treatment means for the data in Table 13.
|
|
Weight gain (g LW/day) |
||
|
Female |
Male |
Mean |
|
|
Diet 1 |
20 |
30 |
25 |
|
Diet 2 |
15 |
25 |
20 |
|
Mean |
17.5 |
27.5 |
22.5 |
|
For females, Diet 1 gives 5 units of weight gain more than Diet 2 (20 compared with 15). The effect for males is the same, animals on Diet 1 gain 5 units more than animals on Diet 2. The obvious and correct conclusion is that animals on Diet 1 gain 5 units more than those on Diet 2, irrespective of which sex they are. The simple means from Table 13 lead to the wrong conclusion that animals on Diet 1 gain 1 unit less than those on Diet 2. The confusion is due to the imbalance of sexes in the two diets. It is fairly obvious in this artificial example, but may not be so obvious in larger, more complex practical situations. The problem of analysing unbalanced factorial experiments cannot be resolved by analysing each factor separately. |
A valid method of analysing unbalanced experiments is to carry out a one-way analysis of variance, with each 'cell' of the factorial structure as a treatment.
For instance, our artificial diet x set example could be analysed as an experiment with four treatments.
This approach will give correct means and standard errors for individual treatments. However, its major drawback is that the effects of the various factors and their interactions cannot be separated. (That is why a factorial design is usually preferred). The other problem is that main-effect means and standard errors cannot be obtained. Finally, in many practical experiments, the number of treatments (or cells) is quite large. A significant overall F-test would indicate that not all treatments are the same, but would be of little use in determining where the differences are occurring.
Definitions
Gross margins
Gross margin table
Partial budgets
Whole-farm budgeting
Cash-flow budgeting
Financial analysis of long-term projects
The net present value criterion
Benefit: Cost analysis
Internal rate of return
Other considerations in cash-flow analysis
Improved technical performance (e.g. higher daily weight gain) does not necessarily coincide with financial attractiveness. Therefore, it is important to consider the financial implications of the adoption of new technology at the farm level.
For instance, a technology tested on-farm nay have the potential to increase production but, at the same time, be financially unattractive. If the returns obtained are not sufficient to cover the costs involved, or if there are more attractive opportunities available elsewhere for the resources (e.g. labour, land, capital) involved (e.g. off-farm employment or interest on bank deposit accounts), wide adoption could not be expected.
The following discussion deals with some of the simpler techniques used to assess the financial attractiveness of innovations being tested in on-farm trials. The methods outlined are also applicable to technological assessment during the pre-screening stages of livestock systems research (Module 1, Section 1; Module 1, Section 2).
Techniques such as simplified programming, linear programming and simulation are not covered here, but they are useful when complex interactions between farm resources are envisaged. Whilst applicable in terms of the underlying principles involved, production economics theory (e.g. input/output relationships) is beyond the scope of this manual. For a discussion of the theory of production economics the reader can refer to any basic economics text.
To facilitate the discussion which follows, a few terms need to be defined at the outset. They are:
ENTERPRISE. In the present context, the term enterprise denotes the production of a particular commodity or group of commodities for the purposes of home consumption or sale (e.g. livestock enterprise, cropping enterprise), but it does not specify the method of production involved.
ACTIVITY. For every enterprise, there may be various ways of producing a commodity. Each possibility represents an activity (e.g. zero-grazing dairy activity, free-roaming goat activity).
INTERMEDIATE PRODUCT. Some farm products are neither sold nor used for home consumption but are used as inputs in the production of another commodity (e.g. forages grown for the purposes of fattening or milk production). These are known as intermediate products and costs incurred in their production can normally be allocated wholly or in part to a particular farm activity. Examples of how intermediate products are valued are given in Module 4 (Section 1) and Appendix 1 of Module 2 (Section 2).
OUTPUT. This is the amount of product produced by an activity (e.g. the amount of milk produced by dairying). It may be sold or retained for home consumption. The manner in which output is valued will depend on whether the household is normally a surplus or deficit producer of the commodity.
For a surplus producer, output should be valued at the price per unit at which it could be sold to a buyer at the producer's farm, or it could be valued at the local market price less the cost of taking it to the market (if this can be estimated).For a deficit producer (i.e. one who has to buy the product on a regular basis), the amount produced should be valued at the price at which it can be purchased if delivered to the farm (module 4, Section 1). Black market prices Ray need to be used if they are more appropriate to the circumstances (Barlow et al! 1986).
If output is exchanged for goods or services in kind (e.g. for labour), then it should be valued on the basis of the exchange item used.
For instance, if an animal is exchanged for labour, then its value is equivalent to cost incurred when hiring the sane amount of labour from other sources at that time of the year.
GROSS ENTERPRISE (ACTIVITY) INCOME. This is the amount of output produced multiplied by the price which is relevant to the particular commodity. In livestock enterprises it may, when applicable, include notional income arising (declining) from changes in the value of the herd kept for the purposes of enterprise/activity.
OPPORTUNITY COST. This is the return (extra income) that would be earned by using one unit of a factor of production in the best alternative use of it to the one being considered. Opportunity costs may be lower or higher than market prices.
VARIABLE COST. A variable cost is a cost which varies directly with the level of output produced.
For instance, costs incurred for vaccines, drugs and dipping, feed supplements, labour hire and marketing services fall into this category. Again, it say be appropriate to use black-market prices for the valuation of variable inputs in some circumstances. The principles involved in the valuation of variable inputs are discussed in Part 4 of Module 4 [Section 1].
FIXED COSTS. A fixed cost is one which remains constant irrespective of the level of output produced.
For instance, annual depreciation on assets such as ploughs and carts, rents and maintenance costs, are fixed costs.
CAPITAL COSTS. A capital cost can be defined as an investment cost incurred for the purposes of increasing future productive capacity.
For instance, investments in fencing! pasture establishment, breeding cows, land and machinery are all investment costs.
GROSS MARGIN. The total gross margin (TOM) for a particular enterprise or activity is defined as:
TGM = total gross income - total variable costs = (total output x price) - total variable costs
Total farm gross margin is the sum of gross margins for all individual enterprises or activities. Note that the gross margin for an activity excludes fixed (or overhead) costs. It therefore represents the specific contribution made by an activity to farm profit.
Gross margins can be used to indicate the relative profitability of a technology being tested during the on-farm trial phase. They are easy to calculate and, for this reason, are often used to assess the financial attractiveness of new alternatives being introduced at the farm level.
A gross margin is normally calculated for a full production year. For small ruminants, which breed three times every two years on average, output in terms of kids/lambs born in one year should be expressed as an annual average over the two-year period (e.g. 1.5 kids/doe/year).
In order to make meaningful comparisons between the various options available, gross margins need to be expressed in comparable terms (e.g. on a per hectare, per livestock unit, per hour of labour basis). Expressed in this way, they provide an indication of the returns that can be expected if alternative activities are expanded by the use of one unit of the resource concerned.
Comparisons are most useful when they are made in terms of returns to the resource which limits the household's income most. New production techniques are likely to provoke interest in the target area if the gross margin per unit of that resource (factor) is higher than it is for other options presently available.
For instance, if labour is the scarce resource limiting production, it is relevant to compare activities on the basis of gross margin per can-day, if land is limiting, comparisons should be made on the basis of gross margin per hectare.
However, there are considerations other than returns to the most limiting factor which influence the adoption of a new technology. They are risk, capital and time-lag.
Risk. An activity with a potentially high gross margin may also be relatively risky and, therefore, unattractive.
Capital. If the activity requires additional capital or credit it may be beyond the reach of the farmer, despite its apparent profitability.
Time-lag. The gross margin (which is usually an estimate of the relative profitability of a fully established activity) gives no indication of the time period involved before full potential is reached. If the technology requires a long 'gestation' period (as may be the case with some breeding schemes), the activity may be unattractive even if returns at full establishment appear relatively attractive.
To deal fully with issues such as these, more complex methods of economic analysis are required, but these are beyond the scope of this manual.
A general gross margin table is given overleaf. The gross margin derived will depend on the assumptions built into the calculation. The best practicable estimates of output levels, prices and costs should be sought and sensitivity tests should be carried out to examine the effect of altering the assumptions made.
|
Note that for livestock gross margins, closing and opening numbers {values} of animals in the herd/flock are included to allow for annual variations in the number and value of stock owned or held. When the herd or flock is in a steady state (i.e. there is no net change in the number owned/held), and when there is no reason to assume that values/head have increased or decreased, the two values cancel out in the gross margin calculation. In such cases, their inclusion in the gross margin table is a matter of choice. |
|
Output |
Value |
|
|
|
Sales |
|
|
Amount sold/exchanged (by item) x price/unit [including livestock and livestock products, e.g. milk, hides, skins) |
||
|
|
+ Home consumption |
|
|
Amount consumed x value/unit |
||
|
|
Total gross value of output |
|
|
+ Closing value of the herd/flock |
||
|
Number of animals in herd/flock by age/sex class x estimated average value |
||
|
|
- Opening value of herd/flock |
|
|
Number of animals in herd/flock by age/sex class x estimated average value |
||
|
|
= Gross income |
|
|
- Variable costs |
||
|
Variable inputs used (itemised) x price paid/unit |
||
|
|
Total variable costs |
|
|
Total gross margin |
||
|
Gross margin per LU |
||
|
(or ha or man-day) |
||
|
Example: Suppose that small-scale dairying has been introduced in a traditional farming area and that the average farmer involved does not supplement his animals with concentrates. Herds, on average, consist of two grade dairy cows stocked at the rate of one cow per 2 hectares of top-dressed natural pasture. Calves are sold soon after birth and artificial insemination is used as a common practice. A 50% weaning rate is commonly encountered. Milk is marketed through the local cooperative and a percentage marketing fee is levied. An average operation of this kind requires about 125 man-days of labour. The average gross margin per cow, per hectare and per man-day have been calculated as follows: |
|
Output |
Value ($) | |
|
Sales | ||
|
600 litres milk/cow x 2 cows x $0,50/litre |
600.00 | |
|
1 calf x $60 |
60.00 | |
|
|
+ Home consumption | |
|
200 litres milk x 2 cows x $0,50/litre |
200,00 | |
|
|
Total gross value of output |
860.00 |
|
+ Closing value: 2 cows x $300 (average value) |
600.00 | |
|
- Opening value: 2 cows x $300 (average value) |
600.00 | |
|
|
Gross income |
860.00 |
|
|
Less variable costs | |
|
Veterinary expenses (vaccines, drugs, care @ $10/cow/year x 2 cows |
20.00 | |
|
+ Artificial insemination @ $10/cow/year x 2 cows |
20.00 | |
|
+ Fertiliser 100 kg nitrogenous fertiliser @ $1.50/kg |
150.00 | |
|
+ Marketing costs (milk) @ 5% of marketed milk value |
30 | |
|
|
Total variable costs |
220,00 |
|
|
Total gross margin |
640.00 |
|
|
Gross margin/cow |
320,00 |
|
|
Gross margin/ha |
160,00 |
|
|
Gross margin/man-day |
5.12 |
|
Suppose now that a series of on-farm trials have been conducted to assess the effect of feed supplementation with a protein/energy concentrate on milk production for the kind of management practices encountered. The aim is to improve the income by measures considered accessible to the average farmer. Based on the trials, concentrate feeding at 100 kg/cow/year was recommended. This was assumed (again on the basis of the trials) to increase marketed milk offtake/cow by 50% but it would also result in extra time required for milking and marketing of the additional milk produced. Man-day requirements/farm for the average operation will thus increase by 20%, and labour is considered the limiting factor in the area. All other outputs and costs remain unchanged. Calculate the gross margin per man-day and decide whether the technology would be recommended. |
|
Output |
Value ($) | |
|
Sales | ||
|
300 litres silk/cow x 2 cows x $0,50/litre |
900,00 | |
|
1 calf x 360 |
60.00 | |
|
|
Home consumption | |
|
200 litres silk/cow x 2 cows x 30.50/litre |
200.00 | |
|
|
Total gross value of output |
1160.00 |
|
+ Closing value: 2 cows x $300 (average value) |
600.00 | |
|
- Opening value: 2 cows x $300 (average value) |
600.00 | |
|
|
Gross income |
1160.00 |
|
|
Less variable costs | |
|
Veterinary expenses e @ 10/cow/year x 2 cows |
20.00 | |
|
+ Artificial insemination e @ 10/cow/year x 2 cows |
20.00 | |
|
+ 100 kg nitrogenous fertiliser @ 31.50/kg |
150.00 | |
|
+ 100 kg concentrate/cow @ 31.00/kg x 2 cows |
200.00 | |
|
+ Milk marketing costs @ 5% of mark, silk value |
45.00 | |
|
|
Total variable costs |
435.00 |
|
|
Total gross margin |
125.00 |
|
|
Gross margin/cow |
362.50 |
|
|
Gross margin/ha |
181.25 |
|
|
Gross margin/man-day |
4.83 |
|
Note that while total gross margin and the gross margins per cow and hectare have increased as a result of the use of concentrate, the gross margin per man-day has fallen. With labour being the limiting factor it is, therefore, unlikely that the new technology will be attractive to the average operator. Even if there were to be a significant increase in returns per man-day, three additional factors would need to be considered before making the recommendation on a wider basis, namely: · returns per man-day in other farm and non-farm activities (e.g. crops, off-farm employment). If other, more attractive options were available, it is unlikely that farmers would be interested in recommendations to use concentrate. · the sensitivity of results to variations in prices, costs and output levels. Highly sensitive results should be treated with caution. · the availability of concentrates on a continuing basis. |
Partial budgeting is an extension of gross margin analysis. It is used to assess the financial worth of a planned incremental (or partial) change in farm organisation which normally involves the need to make additional capital expenditure at the outset. The analysis conducted is concerned only with those annual costs and returns directly affected by the change. A return to the extra capital invested is calculated to permit comparisons between various alternative investment possibilities.
Where the capital investment requires a 'gestation' period before full establishment is reached (as is common with livestock), partial budgeting provides an indication of the annual financial viability of the proposal at full establishment. It therefore ignores the period of capital development required before this phase is reached. This time period may be very important in the assessment of the viability of a technology.
If the partial budget indicates that the proposal is not viable, then further analysis will be unwarranted. If the result is viable, the use of cash-flow budgeting techniques (described below) will probably be needed to assess further the worth of the project. In such cases, partial budgeting should be seen as a preliminary indicative step in the identification of potentially viable changes on the farm.
The technique is simple and is commonly used in the screening and appraisal of cropping technologies during the diagnostic, design and testing phases of livestock systems research (Byerlee and Collinson, 1980; Barlow et al, 1986). With livestock, however, other complementary techniques of analysis may be required to assess the long-term worth of a proposal.
Four basic questions in partial budgeting
When assessing a partial change in farm organisation which may or may not involve additional capital expenditure, four basic questions will be asked. They are:
· What extra annual costs (variable and fixed) result from the change?
· What extra annual gross income will be obtained as a result of the change?
· What extra annual gross income will be foregone as a result of the change?
· What extra annual costs (variable and fixed) will be foregone or saved as a result of the change?
|
Example of a layout of a partial budget for a change in farm organisation resulting from the introduction of a new technology. |
|
Benefits |
Costs |
|
1. Extra annual gross income |
3. Extra annual costs |
|
|
|
|
|
|
|
2. Annual costs saved |
4. Gross income foregone |
|
|
|
|
|
|
Note that:
· All questions relate to the annual effect of the change at full establishment.· Hidden benefits and costs incurred as a result of the change must be taken into account when doing the analysis. These include the costs which will be saved by making the change as well as any income which will be given up or foregone.
Hidden benefits and costs may be important if, for instance, the introduction of one activity means that another needs to be altered in some way. Thus, the introduction of new technologies at the farm level will often have implications for other farm and non-farm activities, and the hidden costs and benefits associated with it can sway the decision for or against a proposal. (See also 'Whole-farm budgeting').
· When doing partial budget analysis, all annual extra costs associated with the change should be fully accounted for. These include both overhead and variable costs.
As regards the additional capital costs involved, it is not correct to charge the whole cost to the annual partial budget statement. Capital costs must be 'spread over the life' of an asset, and an annual allowance for depreciation and replacement must be calculated. This is commonly known as a 'depreciation allowance' and is defined in this manual2 as follows:
2 Other more complex formulae and methods of calculation can be used but the formula given here is sufficient for the purposes of this manual.
|
Example: Assume that on-farm trials have been conducted to examine the benefits of supplementing oxen at the end of the cropping season. Farmers participating in the trial were asked to allocate a hectare of arable land to a fodder crop (e.g. Napier grass) for this purpose. The underlying objective of the trial was to improve the condition of draught animals during the dry season, thereby increasing the chances of early ploughing at the start of the rainy season. This, it was assumed, would improve the yield of maize (the staple food) significantly. In order to make the change, farmers were required to: · invest in fencing equipment at a cost of approximately US$ 300 It was estimated that fences would have an expected life of 20 years after which they would be worth nothing. · use an area previously allocated to maize production to grow Napier grass The costs of establishing the fodder crop were estimated at US$ 135/ha/year, The gross margin from maize in the target area averages US$ 100/ha, with variable costs per hectare being in the order of US$ 40 (i.e. the opportunity cost of land is US$ 100/ha). The average household in the area crops 4 ha under maize every year. · plough at the onset of the first rains The poor condition of animals at the end of the dry season results in late planting which is said to be the major constraint to improved maize production. Trial results indicated that if these requirements were met, maize gross margin on the remaining 3 hectares of land would increase by approximately 100%. Based on these results, should the change be recommended for an average farm in the target area? A partial budget for the improvement of maize production by supplementary feeding of oxen is shown in Table 15. |
Table 15. Testing the financial advantages of early ploughing.
|
BENEFITS |
COSTS |
|
Extra annual gross income |
Extra annual costs |
|
Maize: 3 ha @ 1100/ha - $300 |
Fencing: annual depreciation (3300 - $0)/20 - $15 |
|
Fodder crop: Establishment costs = $135 |
|
|
Annual costs saved |
Gross income foregone |
|
Maize 1 ha (variable costs) @ 340/ha $40 |
Maize: 1 ha (gross returns) @ 3140/ha $140 |
|
Total benefits - $310 |
Total costs - $290 |
|
Net annual benefit resorting from the change: + US, 50 |
|
|
Net returns to the extra capital invested in the proposal can be estimated as follows: Returns to capital (%) = (Net benefits/Total capital invested) x 100 = 50/300 x 100 = 16.6% Although the proposal would result in a net improvement in annual income (by 12.5%), it is highly unlikely that it would be recommended for the following reasons: · the net gains in absolute terms (US$ 50) resulting from the change are small · minor changes in the assumptions made about maize production would lower the net gains substantially For instance, an assured increase in the gross margin of maize by 80% (not 100%) would effectively wipe out any increase in income. The result is thus highly sensitive to the assumptions made, making the innovation a risky proposition. · relative returns (i.e. 17%) to the extra capital invested are comparatively low and would probably be higher by investing in other alternatives (e.g. cattle). |
The example serves to demonstrate the importance of considering the financial as well as the technical implications of proposed technologies tested on-farm. While apparently attractive in terms of its technical potential, the innovation fails on financial grounds and could not therefore be recommended. Of course, there would be little point in conducting on-farm trials if the indications beforehand were that the proposal would never pass on this or any other basis. For this reason, all new technologies should be carefully screened during the design phase, using partial budgeting.
This manual has stressed the importance of recognising the various linkages which exist within a system. Interventions such as those outlined above will almost invariably affect other farm and non-farm activities carried out by the household, and it may be the effect on these activities which ultimately influences the farmer's decision to accept or reject a proposal.
For instance, if labour is a limiting factor on the farm' and if the technology being proposed implies a shift in labour use away from other activities considered important, then the innovation may be unattractive if labour cannot be hired or obtained from other sources to compensate for its lack
A whole-farm approach is thus often necessary to assess the full impact of a new technology. Linkages which may otherwise be ignored can be more clearly recognised by the use of whole-farm budgets which involve the calculation of gross margins for all activities before and after the change is made.
A whole-farm budget is derived as:
(d All farm activity total gross margins) - (d farm overheads)
When this expression is calculated, the net farm income accruing to the whole farm is derived.
The derivation of a whole farm budget for the situation before and after adoption may also point to implied shifts in the composition of gross income and the manner in which it is received (e.g. its seasonal distribution), all of which can also affect farmers' attitudes towards change.
One further advantage of the whole-farm approach is that, by deriving gross margins for all other farm activities (crop and livestock), management weaknesses in other areas of production can often be isolated. By identifying these, further scope for improvement can sometimes be identified. Gross margins thus have a diagnostic as well as a prescriptive function.
Minor activity changes with little or no investment of capital involved will often increase farm income in a relatively short time period. When this is the case, simple methods of analysis such as those outlined above will adequately assess the financial viability of a proposed intervention.
In other cases, improvements take longer and substantial injections of capital are required. Cash-flow budgeting methods should then be used to assess the financial viability of the proposal being considered. Those appropriate to the analysis of on-farm trials are briefly outlined below3.
3 For details, the reader is referred to Gittinger (1982), Putt et al (1987) and Chisolm and Dillon (1988).
Net cash flow
The first step in cash-flow budgeting is to derive a net cash-flow (NCF) budget, by considering all the cash costs and benefits which accrue directly to the proposal. This requires the calculation of all expected expenditures and receipts resulting from the implementation of the proposal at the farm level. The layout of the NCF calculation is shown overleaf.
Note that all benefits and costs should be itemised over time and be entered in the budget as they occur over time. The components of the NCF calculation and other relevant aspects are discussed below in some detail.
|
Example of a conventional layout for the derivation of the net cash flow for a farm project: | |||||||||||
|
| |||||||||||
|
|
Year | ||||||||||
|
Item |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 | |
|
A. Gross benefits/income | |||||||||||
|
| |||||||||||
|
| |||||||||||
|
| |||||||||||
|
|
Total benefits | ||||||||||
|
Less | |||||||||||
|
B. Costs | |||||||||||
|
|
- variable costs | ||||||||||
|
|
- overhead costs | ||||||||||
|
|
- capital costs | ||||||||||
|
|
Total costs | ||||||||||
|
C. Net cash flow (A - B) | |||||||||||
The net cash flow for a particular year is the difference between gross benefits and costs in that year. It can be either positive or negative. Negative figures for any one year are usually indicated by brackets ( ). When a period of development is needed, as is often the case with new technologies requiring substantial investment or changes in management (which we shall hereafter refer to as 'projects'), negative figures are commonly encountered during the initial few years after which the net cash flow becomes positive.
Benefits. The benefits which can easily be identified are those where output is sold through formal and informal market channels. These financial benefits are equivalent to the volume of sales of all extra outputs resulting from the investment, multiplied by the price received for those outputs. Where output is not sold but used for other purposes (e.g. home consumption), an 'imputed' cash benefit is included in the benefit stream.
Some innovations do not lead to marketable output in the conventional sense; they save costs instead (e.g. labour costs). When these cost savings can be quantified, they should be included as part of the benefits stream, If it is difficult or impossible to quantify some benefits, they should at least be stated in the final assessment of the proposed innovation.
Costs. Most costs are straightforward and can be entered into the budget as they are expected to occur. Depreciation of capital equipment is not entered as an annual cost since this is an allowance, not a monetary cost. It is, however, reflected in the budget by entering both the original cost of the equipment (i.e. in full at the time of expenditure) and its replacement cost (minus anything received upon sale or disposal).
When funds are borrowed by the farmer to finance the capital required to introduce a new technology, there are two ways of treating the cash flows involved. Normally, the correct way is to include the interest payments and repayments of capital in the cash flow at the time when these occur, but not to include in the cash flow the cost of that part of the capital investment (e.g. in the form of equipment or works) which is financed by borrowed funds.
For instance, if all of the cost of fencing which is carried out in year 1 of the project at a cost of $300) is financed by a loan whose payments of interest and capital take place in nine equal instalments of $57 per year in years 2 - 10 inclusive, usually the correct thing to do is to ignore the payment of $300 to the fencing contractor in year I but to include the annual $57 loan-service payments to the bank in years 2 - 10.Occasionally, it may be correct to include the payment of 3300 in year 1 and to ignore the annual payments It is never correct to include them both However, this is not the place to explain "hen it is core appropriate to include the original capital cost rather than the loan-servicing payments.
Salvage values. For assets which are retained till the end of the project period and which at that time have some value, it is important to enter their depreciated value (normally the value at which they could be sold) in the benefits stream in the last year of the cash flow. Part B of Module 4 (Section 1) shows how the depreciated value of an asset can be calculated.
Length of project period. The length of the project period (i.e. the number of years included in the cash flow budget) is a matter of choice. There is only one guiding principle - the period should extend over a number of years after the project has reached full establishment. Normally, a period of 7-10 years beyond this point will be sufficient. Reasons for this will become clearer later on.
One further point should be borne in mind -price, cost and output predictions become more imprecise as time proceeds. Attempts to draw up cash-flow budgets which are unnecessarily long therefore tend to be rather meaningless.
The net cash flow for a project proposal can be depicted as a graph to provide an indication of the manner in which net returns are generated through time (Figure 2). Sometimes, an examination of the net cash-flow pattern would be sufficient to permit the ranking or selection of different alternative proposals on financial grounds. However, more often than not it is impossible to rank investment opportunities by mere inspection of the cash-flow pattern, and, in such cases, additional analytical tools will be required. (See Figure 2 and following commentary).
Figure 2. Net cash-flow patterns for three potential farm investment options.

In Figure 2, investment option 'A' is obviously superior to 'B' in terms of its long-term financial contribution to the household. Despite the fact that the net cash flow is identical for the two projects during the first 5 years, 'A' continues for a longer period and would, therefore, be preferred.
The choice between options 'A' and 'C' is, however, less straightforward. While 'C' costs more initially (has a greater negative cash flow), and takes longer to reach full establishment, it generates greater net cash flow than 'A' once that point is reached. For such projects, a common basis for comparison (other than by visual inspection) must be established. Some of the methods of financial analysis applicable to such situations are discussed below.
Three methods are applicable, and they will only be discussed very briefly here. They are:
· net present value (NPV)
· benefit: cost analysis, and
· internal rate of return (IRR).
Which method is the most applicable depends on the particular circumstances of the case. The issue is discussed by Gittinger (1982) to whom the reader is referred for further advice.
All the three methods rely on the use of discounting procedures. Discounting is used to express costs and benefits paid or received in the future in present-value terms.
The issue is very complex and cannot be dealt with satisfactorily here. In brief, it is generally recognised that, even in the absence of general inflation, a sum of $100 now is more valuable to most people than $100 in the future, say in 10 years' time. To put this another way, $100 in 10 years' time is less valuable than $100 now, i.e. it is 'discounted' in comparison to its value now. It is less valuable then than now for two main reasons:
· If I have $100 now, I can invest it (e.g. in an interest-paying bank account), so that $100 placed in such an account will, at 10% interest rate, grow to be $259 in 10 years' time, or, to put it another way, $39 put into this account now will, at 10% interest rate, grow to be $100 in 10 years' time.This reason can be summarised in the expression 'the opportunity cost of capital', indicating that tying up capital in one activity prevents its being used in another activity where it can earn a return, e.g. interest.
Therefore, if activity A will give me a benefit of $100 in 10 years' time, this sum must be 'discounted' at a rate equivalent to the interest I could have earned by investing it at the beginning of the project in the next best alternative use, say activity B.
For most farmers in Africa, investment in their own on-farm or off-farm enterprises is more profitable than putting money in the bank, yet they cannot borrow from the bank as much as they would like to. The opportunity cost of capital to them is, therefore, the return they can obtain from investing the money in the best of their own enterprises.
· Offered a choice between consuming (or otherwise enjoying) something now or later, many people will prefer to do so now. It follows that they will have to be offered a little more later than they will get now if they are to be persuaded to defer voluntarily their enjoyment.
The ratio between what is offered now and what has to be offered later in order to voluntarily defer consumption is known as the 'subjective time preference' and is usually expressed as an annual rate of discount, in which case it may referred to as the 'personal discount rate'.
For instance, if an individual is indifferent to US$ 100 received today and US$ 110 received in a year's time, he/she is effectively discounting US$ 110 by 10%. In other words, the individual would be discounting the US$ 110 by a factor of 0,9091, i.e. 110 x 0.9091 US$ 100.
Although acknowledging that the discount rates that reflect the opportunity cost of capital to a farmer and his personal discount rate may, in theory, differ from each other, economists normally use a single rate to represent them both in practice. However, some farmers may be able to borrow capital from others to finance some kinds of farm activities at rates which are lower than their personal discount rates. This is one reason why earlier we said that when money is borrowed to finance the capital cost of a new technology, it is normally right to include the loan-servicing payments in the cash flow rather than the capital cost of the investment for which the money was borrowed.
Discount tables are available for the analysis of projects which extend over time. They can be found in Gittinger (1982) and Chisolm and Dillon (1988) and will not be reproduced here.
Projects with different net cash-flow patterns ('A' and 'C' in Figure 2, for instance) can be compared in terms of their net present value, by using discounting procedures.
|
Example: Assume that the following net cash-flow table has been derived for a project being considered for wider recommendation in the target area: |
|
Year |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
NCF ($) |
- |
- |
- |
100 |
200 |
300 |
700 |
700 |
700 |
700 |
If the discount rate to be used is 5%, the following tabulated discount factors (DF) would apply:
|
Year |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
DF |
- |
- |
- |
0.8221 |
0.7835 |
0.7462 |
0.7107 |
0.6768 |
|
0.6139 |
|
Applying these discount factors to the NCF figures above, we obtain a net present value for the project of: (0 + 0 + 0 + 82.3 + 156.1 + 223.9 + 497,5 + 473.8 + 451.2 + 429.7) = US$ 2315.1 Thus, expressed in present-value terms and given a discount rate of 5X, the value of the project would be about US$ 2315. |
The net present value itself doesn't mean much but it can be used as a basis for comparison between mutually exclusive technologies. Comparisons on the basis of the net present value can have several problems:
· the discount rate is usually chosen by the analyst on the basis of weak evidence
· projects viable at one rate, may not be viable at a higher rate
· project ranking can alter with the use of different discount ratesOne way to test a project's sensitivity to the interest rate is to run several NPV calculations at varying interest levels. You can be fairly confident in the result if a project remains viable and rankings remain unaffected each time.
· smaller, highly attractive projects may have lower net present values than larger, marginally acceptable projects. This is because the net present value gives an absolute measure of profitability, not a relative one.
Because net present values are expressed in absolute terms, and because of the weaknesses associated with this, benefit: cost ratios are often used instead when long-term projects are being assessed. The ratio is expressed as:
Projects are ranked on the basis of the size of the benefit: cost ratio. At a given discount rate, a benefit: cost ratio of 1 or greater is considered viable.
As with the net present value criterion, the benefit: cost ratio suffers from the problem of discount rate selection. It also tends to discriminate against projects with relatively high gross returns and operating costs, even though these may be shown to have greater wealth-generating capacities than other projects with better benefit: cost ratios. Because of these disadvantages, the internal rate of return is often preferred for project appraisals of this kind.
This method involves finding that interest rate which makes the net present value equal to zero. The rate of interest, so found, indicates the actual rate of return on the investment, calculated independently of the cost of borrowing capital.
For instance, an internal rate of return (IRR) of, say, 10% means that a project will recover all operating and capital costs and pay the investor 10% for the use of his/her money in the meantime.
The interest rate derived can also be used as a basis of comparison. A project is said to be viable if the IRR obtained is greater than the opportunity cost of capital (i.e. greater than the interest rate which could be obtained from by investing the capital used in the next best available alternative, e.g. cattle or fodder banks).
The calculation of the internal rate of return is tedious if done by trial and error. A simple formula has therefore been derived (Gittinger, 1982): difference NPV for the lower rate

The procedure is to select first an interest rate which gives a value 'close' to zero on the positive side. Next, find an interest rate (a higher one) which gives an NPV 'close' to zero on the negative side, then solve the equation.
Computer packages are available to reduce the time spent in computation, but the above formula is useful when only hand calculators are available.
These include:
Forecasting costs and prices. Obviously forecasting costs and prices for 10-20 years in advance is fraught with problems. The analyst should, therefore, avoid being rigid in the interpretation of results, and projects should be tested for their sensitivity to variations in cost and price assumptions.
Inflation. In net cash flow analysis, normally no adjustment should be made for expected future price rises caused by general inflation, i.e. where all the prices involved are expected to rise at the same rate. In such cases, the prices current at the time the calculations are made should be forecast to hold in the future also.
However, where (due to market forces such as shortages or large changes in production capacity) the prices of some inputs or outputs are expected to rise or fall relative to others, then adjustments for these relative future price changes should be included in the net cash flow forecast.
If a country suffers from high inflation rates, caution is appropriate with respect to the following:
· Where the discount rate being used in the calculations is based on the rates of return which farmers have historically been able to achieve from investing in their own enterprises, such a discount rate tends to over-estimate the real rate of return that was achieved because the initial investment occurred at a lower general price level than the subsequent revenues generated by it. Such historically based discount rates may need to be adjusted downwards.· Where a new investment is expected to be financed by a loan at a rate of interest which will be constant during the project's life (while all other prices are rising), this is equivalent to believing that the 'price' of loan-servicing payments in the cash flow is falling relative to the prices of other inputs and outputs. An adjustment should, therefore, be made to reflect this.
Incremental benefits and costs. Note that with all the above methods of analysis, we were interested in benefits and costs which accrue solely to the project, i.e. the incremental effects of the project. This is a simple matter to determine, particularly if there are no displacement effects involved.
However, if implementing the project implies that some other farm activities need to be foregone (or displaced or altered) to make way for the project activity itself, then we need to calculate an incremental net cash flow budget. This budget is derived by deducting the 'without-project net cash flow' from the 'with-project net cash flow'. The resulting incremental net cash flow is then analysed using one or more of the methods described above.
Herd projection models. When designing livestock projects of long duration, it is necessary to know how to project herd/flock changes over time, as these will often form the basis for estimating the benefits and costs involved. The method used for such projections is described in detail in ILCA (1989b). ILCA research staff have also devised a computer programme which is useful for the projection of herd/flock dynamics over time. The interested user may contact the Head of Livestock Economics Department of ILCA, Addis Ababa, Ethiopia, for further information about the package.
Barlow C, Jayasuria S K, Price E, Maranan C and Roxas N. 1986. Improving the economic impact of farming systems research. Agricultural Systems 22(2):109-126.
Byerlee D and Collinson M (eds), 1980. Planning technologies appropriate to farmers: Concepts and procedures. Economics Program, CIMMYT (Centro Internacional de Mejoramiento de Maiz y Trigo), Mexico, Mexico. 71 pp.
Chisolm A and Dillon J. 1988. Discounting and other interest rate procedures in farm management. Professional Farm Management Guidebook 2, University of New England, Armidale, New South Wales, Australia.
Cochran W G and Cox G M. 1957. Experimental designs. Second edition. John Wiley and Sons, New York, USA. 611 pp.
Dagnelie P. 1975. Théorie et méthodes statistiques: applications agronomiques. Vol. 2. Les méthodes de l'inférence statistique. Les Presses agronomiques de Gembloux, Gembloux, Belgium. 463 pp.
Gittinger J P. 1982. Economic analysis of agricultural projects. World Bank, Washington, DC, USA. 505 + xii pp. [ILCA library microfiche number 31017]
Gomez K A and Gomez A A. 1984. Statistical procedures for agricultural research. Second edition. John Wiley and Sons, New York, USA. 680 pp.
ILCA (International Livestock Centre for Africa). 1989a. Introductory manual of applied statistics for African animal scientists. ILCA, Addis Ababa, Ethiopia. [draft]
ILCA (International Livestock Centre for Africa). 1989b. Livestock policy analysis. ILCA manual, ILCA, Addis Ababa, Ethiopia. [draft]
Mead R and Curnow R N. 1983. Statistical methods in agriculture and experimental biology. Chapman and Hall, London, UK. 335 pp.
Putt S N H. Shaw A P M, Woods A J. Tyler L and James A D. 1987. Veterinary epidemiology and economics in Africa: A manual for use in the design and appraisal of livestock health policy. ILCA Manual 3, ILCA (International Livestock Centre for Africa), Addis Ababa, Ethiopia. 130 pp. [Translated into French]
Snedecor G W and Cochran W G. 1980. Statistical methods. Seventh edition. Iowa State University Press, Ames, Iowa, USA. 507 pp.
Steel R G D and Torrie J H. 1980. Principles and procedures of statistics: A biometrical approach. McGraw-Hill Book Company, New York, USA. 633 pp.
The Livestock systems research manual is divided into two volumes.
Volume 1 contains:
Introduction (to the manual)
Module 1: Baseline data and explanatory surveys in livestock systems research
Module 2: Diagnostic surveys in livestock systems research
Module 3: Labour inputs
Module 4: Household budgets and assets
Module 5: Animal production
Module 6: Range resource evaluation
Module 7: Animal nutrition
Module 8: Animal health
Module 9: Livestock marketing
Module 10: Management pratices
Module 11: Organisation, presentation and analysis of resutls
Volume 2 contains:
Introduction (to Section 2)
Module 1: Definitions, problems and initial consideration in planning livestock on-farm trials
Module 2: design, implementation, monitoring and evaluation of livestock on-farm trials
Module 3: Analysing data from on-farm trials
International Livestock Centre for Africa
PO Box 5689, Addis Ababa, Ethiopia
Tel: (251-1) 61-32-15 · Telex: 21207 ILCA ET · Telefax: (251-1) 61-18-92 · Cable: ILCA/ADDIS ABABA
ISBN: 92-9053-173-2
![]()
![]()


 = 0.291
= 0.291















 = 0.77
= 0.77
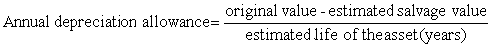

{kind=link}
{kind=link}