![]()
![]()
![]()
2.1 Grid search
2.2 The SIR method
2.3 The Markov Chain Monte Carlo method
2.4 Diagnostics
2.5 Marginal distributions
2.6 Advanced topics
For most problems encountered in fisheries stock assessment, it is impossible to evaluate the posterior distribution (Equation 1.5) analytically. A variety of numerical methods are, however, available for Bayesian analysis (see, for example, Smith (1991) and references therein). We will concentrate on three methods that have been found to be useful even for quite sophisticated problems. Let q denote the parameter vector and p(q), the posterior probability of the parameter vector q. From Bayes rule, p(q) is proportional to the product of the likelihood and prior evaluated at q, g(q), i.e.:
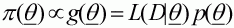 (2.1)
(2.1)
The purpose of the three methods is to sample a set of equally-likely vectors {qi: i=1,2,...} from the posterior distribution, p(q), or to determine the relative posterior probabilities for a set of pre-specified vectors of parameters. Each set of parameters can then be used as the basis for projections into the future for a range of alternative management actions to calculate the values for the performance statistics and hence develop a decision table (see Sections 1.2.5, 3.1 and 3.2).
The methods in this section are illustrated using a hypothetical example assessment. The objective of the assessment is to determine posterior distributions for the parameters of the model. For simplicity only a single structural model is considered for the dynamics of the resource:
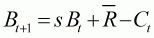 (2.2)
(2.2)
where
Bt is the biomass at the start of year t,For the purposes of illustration, the value of the parameter s is assumed known and equal to 0.7 and it is assumed that the population was at deterministic equilibrium prior to the start of harvesting in 1971, i.e.
s is the annual survival rate,is the average recruitment, and
Ct is the catch during year t.
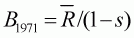 [4].
The direct data available for assessment purposes are a time series of catch
rates. Assuming that the errors between the model-predictions and the
observations are log-normally distributed and that catch rate is related
linearly to biomass, the likelihood function is:
[4].
The direct data available for assessment purposes are a time series of catch
rates. Assuming that the errors between the model-predictions and the
observations are log-normally distributed and that catch rate is related
linearly to biomass, the likelihood function is: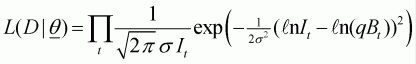 (2.3)
(2.3)
where
It is the catch rate for year t,Theq is the constant of proportionality that relates catch rate to population biomass (the catchability coefficient), and
s is the standard deviation of the random fluctuations in catchability (assumed to be known and equal to 0.4).
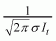 term in Equation
(2.3) can be omitted from the evaluation of the likelihood function in the
spreadsheets because it is a constant (i.e. it is the same for all combinations
of and q - and including this
term would simply increase the time required to conduct the calculations). The
above assumptions imply that the only unknown parameters are
and q. The priors for this
illustrative example are taken to be
term in Equation
(2.3) can be omitted from the evaluation of the likelihood function in the
spreadsheets because it is a constant (i.e. it is the same for all combinations
of and q - and including this
term would simply increase the time required to conduct the calculations). The
above assumptions imply that the only unknown parameters are
and q. The priors for this
illustrative example are taken to be 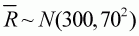 truncated to lie between 150 and 450, and q~U[0,0.002]. Although we would
never assume a uniform prior for q in actual applications (see, for
example, Punt and Hilborn, 1997), we have used this prior here to keep the
example simple.
truncated to lie between 150 and 450, and q~U[0,0.002]. Although we would
never assume a uniform prior for q in actual applications (see, for
example, Punt and Hilborn, 1997), we have used this prior here to keep the
example simple.The grid search method is conceptually easy to implement using a spreadsheet. It proceeds as follows:
a) The range of values for each of the parameters is divided into between 10 and 50 discrete levels. We recommend starting with 10 levels and increasing the number of levels until the results no longer change appreciably.The product of the likelihood and the prior,
(Equation 2.1), is then evaluated for each combination of parameters.
b) The posterior probability for each combination of the two parameters is then calculated using Equation (1.6). The (marginal) posterior probability distribution for one of the parameters, say
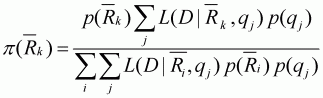 (2.4)
(2.4)
The grid search algorithm is implemented in the sheets
"Likelihood" and "Main" of the spreadsheet EX3A.XLS. The range for
is divided into 30 equally-spaced
levels (150-160, 160-170, etc.) and that for
 into 20 levels (0-0.0001,
0.0001-0.0002, etc.). The sheet "Likelihood" computes the likelihood for each
combination of and q(cells B45
to V75) using the EXCEL Table function. The Table function evaluates the value
of Equation (2.3) (cell B7 divided by 2s2) for each combination of
and q (listed respectively in
cells B46 to B75 and C45 to V45). The value of the likelihood function is
evaluated at the mid-point of the range for each cell (i.e. for the cell for
which = (150-160) and q =
(0-0.0001), the likelihood is evaluated at the point (155, 0.00005)). As noted
in Section 1.3.1, the evaluation of the likelihood function involves projecting
the population from the first to the last year (cells D15 to D40) and then
evaluating Equation (2.3) [cells F15 to F40]. In addition to the contribution by
the data, this column also contains a penalty (1000) to account for the
possibility of the model predicting that the population was rendered extinct
some time between 1971 and 1996.
into 20 levels (0-0.0001,
0.0001-0.0002, etc.). The sheet "Likelihood" computes the likelihood for each
combination of and q(cells B45
to V75) using the EXCEL Table function. The Table function evaluates the value
of Equation (2.3) (cell B7 divided by 2s2) for each combination of
and q (listed respectively in
cells B46 to B75 and C45 to V45). The value of the likelihood function is
evaluated at the mid-point of the range for each cell (i.e. for the cell for
which = (150-160) and q =
(0-0.0001), the likelihood is evaluated at the point (155, 0.00005)). As noted
in Section 1.3.1, the evaluation of the likelihood function involves projecting
the population from the first to the last year (cells D15 to D40) and then
evaluating Equation (2.3) [cells F15 to F40]. In addition to the contribution by
the data, this column also contains a penalty (1000) to account for the
possibility of the model predicting that the population was rendered extinct
some time between 1971 and 1996.
The sheet "Main" (cells B42 to V73) computes the product of
the likelihood and the prior (i.e. g(q)). The prior probabilities for each of the
s are listed in cells A44 to A73 while
those for the qs are listed in cells C42 to V42. The prior probabilities
do not add up to 1 - this does not, however, impact the final results as the
prior probabilities only have to provide the relative credibility of each
combination of and q. The
likelihoods that were computed in sheet "Likelihood" are stored in cells C8 to
V37. The posterior probability is computed by normalising the values for
g(q) so that they sum to 1 (cells
C78 to V107). The results of this calculation can be summarised by the marginal
posterior for (cells X78 to X107 -
computed using Equation (2.4)) and compared to the normalised distribution of
the prior for (cells Y78 to Y107).
Similarly, it is possible to compute the posterior probability for different
values for q (cells C108 to V109). The sheet "Summary" provides a
graphical representation of the marginal posterior distributions (bars), the
prior distributions (solid lines), and the joint posterior distribution for
and q.
It is possible to use the EXCEL Table function for problems such as the one above that involve one or two uncertain parameters. For problems involving more parameters, it is necessary to write a macro that projects the population dynamics model and then calculates the likelihood function. For the grid search method, computational requirements increase exponentially with the number of parameters. It is therefore, except for problems with four or fewer parameters, a very inefficient computational method.
The grid search method and the simple version of the SIR method described below share another computational problem when the data are highly informative; most of the posterior probability is in a very small part of the parameter space (often the case when age-structure data are included in assessments). In these situations, most of the likelihood evaluations have a negligible contribution to the total probability so the area of parameter space with highest posterior probability may not be sampled adequately. This can lead to poor estimation of probabilities and hence of the quantities needed to conduct a decision analysis. The solution to these problems is to reduce the width of each interval, but this leads to greatly increased computational demands. On the other hand, the Grid Search method can often perform well when a wide range of parameter values fit the data (i.e. "multi-modal" posterior distributions) [if the width of each interval is chosen well], which can be a major problem for the Markov Chain Monte Carlo method reviewed below.
The Sample-Importance-Resample (SIR) method (Van Dijk et al., 1987; Rubin, 1987; Rubin, 1988) is a method that approximates the posterior distribution for high dimensional problems. Many variants of this method exist. In this section, we describe the simplest variant and defer discussion of a more complicated variant to Section 2.6.2. The analyses of Bergh and Butterworth (1987), McAllister et al. (1994), Raftery et al. (1995) and Punt and Walker (1998) are all based on this simple variant. The method proceeds as follows:
a) A vector of parameter values, q is drawn from the prior distribution.The spreadsheet EX3B.XLS illustrates how the SIR algorithm is used to compute posterior distributions forb) The likelihood of this vector of parameter values, L(D|q), is evaluated.
c) The vector of parameters and the corresponding likelihood are stored in a file.
d) Steps a) to c) are repeated thousands (or even millions) of times to build up a joint posterior distribution for the parameters.
and q. The priors for the
parameters are specified in cells B10, B11, B16 and B17. The spreadsheet
implements the SIR algorithm using the macros "RunSIR" and "Clearoutput" which
can be run by clicking on the buttons provided in the spreadsheet. The
calculation involves clearing the temporary storage using the macro
"Clearoutput", specifying the number of SIR replicates (Cell B15 -
"Numreplicates"), and running the macro "RunSIR". The main features of the macro
"RunSIR" are the subroutine "func" which takes the two parameters
( and q) and computes the
likelihood, and the subroutine "sir" which performs the actual SIR steps.
Subroutine "sir" involves conducting a number ("nreps") of replicates. Each
replicate involves randomly generating values for
and q from their priors,
computing the likelihood and storing it for further use. If the value drawn for
lies outside of the pre-specified
bounds, a new random number is drawn until a value within these bounds is
selected. For each parameter vector drawn from the prior, the likelihood is
added into the appropriate entry in a table that will represent the joint
posterior distribution. The values of
and q are stored for later use in columns B and C starting in row 53. The
posteriors for each parameter are then computed as was the case for the grid
search method.EX3B.XLS includes features to monitor performance by
displaying the last fit to the data (dots - actual data; lines - model
predictions) and the (, q)
points examined so far. The analyst can specify whether these diagnostics are
displayed for each replicate by setting the value of cell B13 ("Screenon") to 1.
When this value is set to 0 the screen will only refresh every B14 replicates
("Screenrefresh"). The final posterior surface and the marginal posterior
distributions for and q are
shown in the sheet "Summary". This sheet also shows the marginal posterior for
the depletion of the resource in 1996 by, for each parameter vector, determining
the depletion and adding the likelihood for this parameter vector into an array,
which represents depletions from 0 to 1.5 in steps of 0.05 (Cells AC4 - AE33 in
"Main"). The normalization of this array provides the posterior
distribution.
The Markov Chain Monte Carlo (MCMC) method (Hastings, 1970; Gelman et al., 1995) involves selecting a starting parameter vector q0 and generating a sequence of parameter vectors q1, q2, ... which converge to the posterior distribution. As was the case for the SIR method, there are several variants of the MCMC method. Here we describe a simple variant of the MCMC method (used by Punt and Kennedy (1997) for an assessment of the rock lobster resource off Tasmania, Australia). This variant of the MCMC method involves the following steps:
a) Select starting values for each of the parameters in order to specify the starting parameter vector q0 and set i equal to 0.The MCMC algorithm is implemented using the macros "Clearoutput" and "RunMCMC" in the spreadsheet EX3C.XLS. The initial values for the parameters (step a) are stored in cells B5 and B6 while cells B16, B17 and B18 store the total number of times steps b) to d) should be repeated, the length of the "burn-in" period, and the frequency at which parameter vectors are stored (see step f) above). The "best" values for the last three quantities will be specific to each problem and the analyst should examine the sensitivity of the results to changing the values for these quantities. Every few steps (defined at cell B18 - "nevery"), the vector of tolerances, D, is updated. This involves keeping a record of the proportion of times the new value for parameter j replaces the current value (see steps b)iii) and b)iv) above) and increasing the jth element of D by 1% if this proportion is greater than 0.5 and vice versa.b) For each parameter of the model (qi,j is the jth element of the vector qi):
i) Sample a new value for the parameter from a "jumping distribution". For this simple variant, this involves generating a random value, q’i,j, from the uniform distribution |qi,j-Dj, qi,j+Dj|.c) Store the parameter vector at the end of the loop for eventual output as part of the sample from the posterior distribution.ii) Evaluate g(q), the product of the prior and the likelihood, at the parameter vector constructed by replacing the current value of qi,j by q’i,j (the "new" parameter vector).
iii) If g(q) for the new parameter vector [g(q’i)] is greater than that corresponding to the current parameter vector, g(qi), replace the current parameter vector with the new parameter vector.
iv) If g(q) for the new parameter vector is less than g(qi), replace the current parameter vector with the new parameter vector with a probability equal to the ratio g(q’i)/ g(qi).
d) Set i=i+1 and set qi+1 to the parameter vector at the end of the loop i of the algorithm.
e) Repeat steps b) to d) thousands (or millions) of times.
f) The sample from p(q) is every n'th value in the sequence. If correctly applied, this should be a random sample from the posterior distribution. The choice of n when selecting from the sequence (referred to as "thinning") should be chosen so that there does not appear to be much auto-correlation between the samples. The results of the first 1,000 or so iterations should be ignored as this is a "burn-in" period for the algorithm to set itself up.
The calculations in spreadsheet EX3C.XLS involve first
clearing the temporary storage using the macro "Clearoutput", specifying the
values in cells B16, B17 and B18, and running the macro "RunMCMC". The main
features of the macro "RunMCMC" are the subroutine "func" which takes the two
parameters ( and q) and computes
the product of the likelihood and the prior, and the subroutine "mcmc" that
performs the actual MCMC steps. Subroutine "mcmc" involves conducting a number
of replicates ("nreps"). Each replicate involves looping through each of the
parameters applying steps i) to iv) above. The sample from the posterior is
stored in columns B and C starting at line 53. The results of the algorithm are
presented in the form of the joint posterior for
and q and the marginal
posterior distributions for these parameters in sheet "Summary".
We have found this algorithm to be very efficient computationally for problems with a large number of parameters and a complicated likelihood function. Unlike the simple variant of the SIR method, this method appears to perform adequately for stock assessments that use catch-at-age data.
It is essential to use an appropriate number of levels when applying the grid search method and an appropriate number of iterations when applying the SIR and MCMC methods to obtain an adequate representation of the posterior distribution. These numbers depend on the amount of data, the form of the likelihood function, and the number of parameters in the model. Unfortunately, selecting the number of levels and iterations is more of an art than a science. Considerable attention is being given by statisticians to the problem of determining whether methods such as SIR and MCMC have converged but most of the techniques developed so far are well beyond the scope of this manual. In this section we outline some relatively simple approaches for assessing convergence. The interested reader can consult more detailed texts such as Geweke (1992), Raftery and Lewis (1992), and Cowles and Carlin (1996). Useful websites include those for CODA[5] and BOA[6] and a MCMC diagnostic review site[7].
The first thing that we recommend is that before implementing any of the methods for developing posteriors, the analyst should first construct a spreadsheet that implements the model and calculates the likelihood. This is because all of the methods make use of the likelihood function and it is the place where analysts (including the authors of this manual) make the greatest number of errors!
Unfortunately, the only way to properly assess whether the
number of levels when applying the grid search method is sufficient is to
increase them and see if this impacts the posterior distributions markedly. A
method for assessing whether the number of iterations of the SIR algorithm is
adequate to obtain a reasonable approximation to the posterior distribution
involves calculating the fraction of the total likelihood made up by the most
likely parameter vector (cell B22 of spreadsheet EX3B.XLS). As a rule of thumb,
this must not exceed 5% and should preferably not exceed 0.5%. The rate of
convergence can be monitored by examining how the value of cell B22 changes as
the number iterations is increased (recorded in cell B23). An extension to
spreadsheet EX3B.XLS would be to graph this relationship. The sheet "N changes"
of spreadsheet EX3B.XLS shows how the posterior distribution for
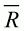 changes as the number of SIR
iterations is increased from 100 to 10,000.
changes as the number of SIR
iterations is increased from 100 to 10,000.
There is considerable debate about how many iterations to conduct when applying MCMC. Although it is useful to assess this visually by plotting the values of the quantities of interest against iteration number and examining the plots for strong autocorrelation (e.g. Raftery and Lewis, 1992). Gelman and Rubin (1992) recommend that analyses be conducted for a range of initial parameter vectors instead. The initial parameter vector when applying MCMC can be changed by modifying the values in cells B5 and B6 in spreadsheet EX3C.XLS. If the results from such multiple runs do not agree, it can be concluded that the runs are too short. However, even if there is no disagreement, it cannot be concluded definitively that the runs are sufficiently long. Other, more ad hoc, methods are to examine the smoothness of the posterior distributions and the difference between the values for the likelihood for each selected parameter vector and that corresponding to the maximum likelihood possible.
Spreadsheet EX3D.XLS contrasts posterior distributions for
based on the SIR, MCMC and grid search
methods. The number of iterations for SIR and MCMC was set to 10,000. All three
methods provide similar results in this case. However, it is often useful to
apply different methods of developing posterior distributions because this
provides a reasonably robust (albeit computationally intensive) way of assessing
whether the number of iterations is adequate. If the results from the different
methods differ, the first thing to do is to check for programming errors and
then to re-run the calculations with a larger number of iterations.
Finally, we advise that if Monte Carlo methods (e.g. SIR and MCMC) are used, the calculations should ideally be repeated for several different random number seeds to check that the results are not sensitive to the choice of the random number seed. Having advised this, the computational demands of applying Bayesian methods can mean that re-running the calculations several times may be infeasible.
It is often necessary to compare the prior distribution for a
quantity of interest, such as the current biomass, with a numerical
representation of its marginal posterior distribution to gauge the information
content of the data. The marginal posterior distribution is calculated by
dividing the range for the quantity of interest,
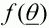 , into a number of discrete "bins" of
equal width. Cells AC4 to AG33 in sheet "Main" of spreadsheet EX3B.XLS provide
the storage needed to construct numerical representations of the marginal prior
and posterior distributions for the ratio of the biomass in the final year
(1996) to the biomass in the first year (the current depletion). The code that
bins the values for current depletion is stored in the macro "sir". The marginal
prior and posterior distributions for the current depletion are shown in the
sheet "Summary". The calculation proceeds as follows. Each time that a function
call is made, the value for current depletion is calculated and stored in the
variable "Depl". The bin corresponding to this value is then determined (stored
in "ibin3") and the vectors of probabilities for different values of current
depletion updated. The "probability" used when determining the prior is 1
whereas this probability is equal to the likelihood to determine the posterior
distribution.
, into a number of discrete "bins" of
equal width. Cells AC4 to AG33 in sheet "Main" of spreadsheet EX3B.XLS provide
the storage needed to construct numerical representations of the marginal prior
and posterior distributions for the ratio of the biomass in the final year
(1996) to the biomass in the first year (the current depletion). The code that
bins the values for current depletion is stored in the macro "sir". The marginal
prior and posterior distributions for the current depletion are shown in the
sheet "Summary". The calculation proceeds as follows. Each time that a function
call is made, the value for current depletion is calculated and stored in the
variable "Depl". The bin corresponding to this value is then determined (stored
in "ibin3") and the vectors of probabilities for different values of current
depletion updated. The "probability" used when determining the prior is 1
whereas this probability is equal to the likelihood to determine the posterior
distribution.
2.6.1 Selecting a subset of the parameter vectors
2.6.2 A more efficient SIR
2.6.3 An advanced version of MCMC
2.6.4 Two additional techniques for reducing computation time
The following sections outline four techniques for making the grid search, SIR and MCMC algorithms more efficient. However, these techniques are quite complicated and are usually only needed when dealing with very large problems so only the first of them has been implemented in EXCEL in this package. Interested readers who wish to use the techniques described in Sections 2.6.2 - 2.6.4 should consider implementing them using a standard programming language (such as Basic) rather than in EXCEL.
The grid search and SIR methods examine very many parameter combinations. Unfortunately, for many problems, the posterior probability for most of these is very close to zero (see the joint posterior distributions in spreadsheets EX3A.XLS and EX3B.XLS). As these parameter vectors are highly unlikely, it would seem sensible to restrict the projections performed for the decision analysis to only the "most likely" parameter combinations. One algorithm for selecting which parameter vectors to consider in projections is to sample (with replacement) from the total number of parameter vectors assigning the probability of selecting a given vector proportional to its likelihood (SIR) and posterior probability (grid search).
If the parameter vectors are listed in columns (as is currently the case for the implementation of SIR - see columns B-D of worksheet Main in spreadsheet EX3B.XLS starting at row 53), it is possible to implement this random selection efficiently. The method for doing this (see the macro "QuickSel" in spreadsheet EX3B.XLS) is:
a) Choose a threshold likelihood (cell E18 in the sheet "Main").The threshold needs to be chosen to ensure that sufficient parameter vectors are selected to allow the decision analysis to be conducted. The algorithm is such that some parameter vectors may be selected more than once. One way to assess convergence is therefore to count how often vectors are selected multiple times when developing the set of parameter vectors to consider in projections. An extension to the spreadsheet EX3B.XLS would be to modify the macro "sir" so that it is not necessary to store non-selected parameter vectors at all (see Section 3.2 for how this can be done).b) Move to the first of the parameter vectors generated during the SIR algorithm and set the cumulative total likelihood (the variable "total" in the macro "QuickSel") to zero.
c) Add the likelihood for the current parameter vector to the cumulative total.
d) Select the current vector if the cumulative total exceeds the threshold (the macro copies the selected parameter vector to the sheet "SelPar"), reduce the cumulative total by the threshold, and repeat this step.
e) Move to the next parameter vector and go to step c) (unless there are no additional vectors).
The efficiency of the SIR method can be improved markedly if
an approximation to the posterior distribution is available. This approximation,
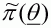 , referred to as the importance
function, must have non-zero probability wherever
, referred to as the importance
function, must have non-zero probability wherever
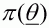 has non-zero probability and it must
be easy to generate parameter vectors from
(Oh and Berger, 1992). The SIR method
then proceeds as follows.
has non-zero probability and it must
be easy to generate parameter vectors from
(Oh and Berger, 1992). The SIR method
then proceeds as follows.
a) Draw a vector,This modified algorithm is identical to the simple method of Section 2.2 when, from the distribution
b) Calculate
and the "importance sampling weight"
where
is the probability of generating the vector
c) Repeat steps a) and b) many times.
d) Select a sample from these vectors with replacement, assigning a probability of selecting a particular vector proportional to its importance sampling weight.
is taken to be the
prior distribution, 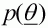 , because for the
choice
, because for the
choice 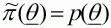 , the importance sampling weight
is simply the likelihood of the data given the vector
, i.e.
, the importance sampling weight
is simply the likelihood of the data given the vector
, i.e.
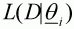 . McAllister and Ianelli (1997) and
Smith and Punt (1998) apply this modified algorithm taking the importance
function to be a multivariate t-distribution with mean given by the
values for the parameters which maximise the product of the likelihood function
and the prior, and variance-covariance matrix obtained by inverting the Hessian
matrix[8]. The values for the mean can be found
using the EXCEL SOLVER function. The Hessian matrix is output by some modeling
fitting packages (such as the Ad Model Builder
package[9]) but can be approximated numerically
(e.g. Press et al., 1988). The numerical approximation to the Hessian
matrix could be implemented using a macro.
. McAllister and Ianelli (1997) and
Smith and Punt (1998) apply this modified algorithm taking the importance
function to be a multivariate t-distribution with mean given by the
values for the parameters which maximise the product of the likelihood function
and the prior, and variance-covariance matrix obtained by inverting the Hessian
matrix[8]. The values for the mean can be found
using the EXCEL SOLVER function. The Hessian matrix is output by some modeling
fitting packages (such as the Ad Model Builder
package[9]) but can be approximated numerically
(e.g. Press et al., 1988). The numerical approximation to the Hessian
matrix could be implemented using a macro.The use of the uniform distribution as the "jumping distribution" (see step b)i) of Section 2.3) is only one of several alternatives (e.g. Hastings, 1970; Gelman et al., 1995). An alternative that we have found to improve the efficiency of the algorithm considerably is as follows:
a) Select starting values for each of the parameters to specify the starting parameter vector q0.As was the case for the advanced version of SIR, the initial vector of parameters,b) Specify a variance-covariance matrix, V0.
c) Set i equal to 0.
d) Construct a vector,
, by adding to
a random variate generated from a normal distribution with mean
and variance covariance matrix
.
e) Calculate the posterior density,
, at the parameter vector
.
f) Replace the current parameter vector by
.
g) Replace the current parameter vector by
, if
h) Store the parameter vector at the end of step g) for eventual output as part of the sample from the posterior distribution.
i) Set i equal to i=i+1 and
to the parameter vector at the end of the loop i of the algorithm.
j) Repeat steps d) - i) many times.
k) The sample from
is every n'th value in the sequence. The results of the first 1,000 or so iterations should be ignored, as this is a "burn-in" period for the algorithm to set itself up.
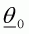 , can be set
equal to the combination that maximizes the product of the likelihood and the
prior, and the initial variance-covariance matrix,
, can be set
equal to the combination that maximizes the product of the likelihood and the
prior, and the initial variance-covariance matrix,
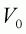 , can then be set equal to the inverse
of the Hessian matrix corresponding to the initial vector of parameters (see
Section 2.6.2 for additional details about the Hessian matrix). An extension to
this algorithm is to update the variance-covariance matrix every few iterations
(e.g. Punt and Kennedy (1997)).
, can then be set equal to the inverse
of the Hessian matrix corresponding to the initial vector of parameters (see
Section 2.6.2 for additional details about the Hessian matrix). An extension to
this algorithm is to update the variance-covariance matrix every few iterations
(e.g. Punt and Kennedy (1997)).In some cases, it is possible to integrate out some of the "nuisance" parameters analytically. "Nuisance" parameters are parameters that are part of the population dynamics model but are not needed for the projections that form part of a decision analysis. We recommend the use of the methods outlined by Walters and Ludwig (1994) for eliminating the catchability coefficient, q, because they reduce the computational demands of evaluating the posterior markedly.
A computationally more efficient implementation of the grid
search method is to select the values of the parameters so that they are equally
spaced in terms of their prior probability. The algorithm described in Section
2.1 is then modified so that, instead of evaluating
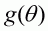 for each parameter vector
for each parameter vector
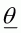 , it is necessary only to evaluate the
likelihood for each .
, it is necessary only to evaluate the
likelihood for each .
Conducting sensitivity tests involves re-running the entire assessment with a different set of specifications (e.g. with a different prior for q). For many problems (such as those in the next section), this can be accomplished computationally relatively easily. However, for more complicated Bayesian assessments (e.g. that of the eastern stock of gemfish - Smith and Punt (1998)), it may take days to conduct a single application of one of the above methods. We recommend that analysts consider the re-weighting approach of Givens et al. (1994). This approach, when combined with the SIR method, can substantially reduce the time needed to conduct sensitivity analyses.
![]()
![]()
![]()