![]()
![]()
![]()
3.1 Biomass dynamics model (spreadsheets EX4A.XLS and EX4B.XLS)
3.2 Stock recruitment analysis (spreadsheets EX4C.XLS and EX4D.XLS)
3.3 Age-structured models
In this section, we outline the details of three worked examples based on three typical methods of stock assessment (biomass dynamics model, stock-recruitment model, and age-structured model). The first two examples are implemented using EXCEL and the third is implemented using the stock assessment package COLERAINE[10].
3.1.1 Stock assessment phase
3.1.2 Decision analysis phase
The objective of this worked example is to examine the implications of different harvest rates in terms of average future catches and changes in biomass. The outputs of the spreadsheet are decision tables that summarise the average catch over a 23-year projection period and the level of biomass after 23 years as a function of the chosen harvest rate (Table 3.1). The current (1996) biomass is grouped into 5 bins (centred on the values listed in the first line of each decision table) and seven harvest rates from 0 to 0.6 are considered.
Table 3.1: Example decision tables from spreadsheet EX4B.XLS (the actual results may differ from those in these tables due to differences in random numbers).
|
|
Average catch |
Ratio of the biomass in 2020 to that in 1996 |
||||||||
|
Current (1996) stock size |
Current (1996) stock size |
|||||||||
|
|
300 |
600 |
900 |
1200 |
1500 |
300 |
600 |
900 |
1200 |
1500 |
|
Posterior probability |
0.23 |
0.41 |
0.21 |
0.10 |
0.03 |
0.23 |
0.41 |
0.21 |
0.10 |
0.03 |
|
Harvest rate |
|
|
|
|
|
|
|
|
|
|
|
0 |
0 |
0 |
0 |
0 |
0 |
2.18 |
1.60 |
1.39 |
1.33 |
1.19 |
|
0.1 |
68 |
75 |
91 |
106 |
121 |
1.65 |
1.23 |
1.09 |
1.04 |
0.97 |
|
0.2 |
104 |
121 |
148 |
170 |
202 |
1.17 |
0.90 |
0.82 |
0.76 |
0.75 |
|
0.3 |
118 |
143 |
178 |
200 |
247 |
0.79 |
0.63 |
0.58 |
0.51 |
0.55 |
|
0.4 |
118 |
150 |
189 |
207 |
264 |
0.51 |
0.42 |
0.41 |
0.32 |
0.38 |
|
0.5 |
111 |
147 |
188 |
201 |
260 |
0.32 |
0.28 |
0.28 |
0.19 |
0.24 |
|
0.6 |
100 |
139 |
181 |
190 |
245 |
0.20 |
0.19 |
0.19 |
0.11 |
0.14 |
3.1.1.1 Theoretical background
The model used for the analysis is the Schaefer production model fitted to a time series of catch rates under the assumption that catch rate is linearly proportional to abundance and that the observation errors are lognormally distributed[11]. These assumptions lead to the following equations for the population dynamics and the likelihood function:
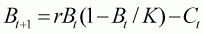 (3.1a)
(3.1a)
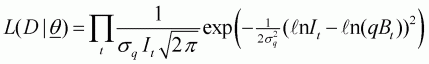 (3.1b)
(3.1b)
where
Bt is the biomass at the start of year t,As before, we make the assumptions that the value for sq is known and equal to 0.4 and that the biomass at the start of 1971 equals K. These assumptions reduce the number of estimable parameters to 3. In a real example, there would be a need to assess carefully whether these assumptions are valid and perhaps to consider sensitivity to different assumptions. For the reasons discussed in Section 4.4.1, we actually work with r, K and the natural logarithm of q. For simplicity, we place normal priors on all three of these parameters:r is the intrinsic rate of growth,
K is the carrying capacity (unexploited equilibrium level),
Ct is the catch during year t,
It is the catch rate for year t,
q is the catchability coefficient, and
sq is the standard deviation of the random fluctuations in catchability.
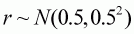 ,
,
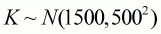 and
and
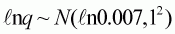 . These priors are very broad and
consequently supply little information about the values for the
parameters.
. These priors are very broad and
consequently supply little information about the values for the
parameters.3.1.1.2 Implementation details
The MCMC algorithm (see Section 2.3) is used to evaluate the posterior distribution (sheet "Main" of spreadsheet EX4A.XLS). For this application, we conduct 50,000 cycles, disregard the first 5,000 as a "burn in" period, and select the parameter vector after every 40th cycle as the basis for the decision analysis. To ease the process of evaluating whether the MCMC algorithm has converged adequately to the posterior distribution, a variety of diagnostic plots are produced:
a) a plot of the r-K points included in the posterior sample,The last two of these plots do not exhibit any obvious patterns with increasing cycle number so it can be concluded that the algorithm has converged adequately. The output from the MCMC algorithm is stored from row 63 onward and the posterior distributions for r, q and K are displayed in the sheet "Posterior".b) a plot of the r values included in the posterior sample as a function of cycle number (the magenta line is a ten-point moving average to ease interpretation), and
c) a plot of the posterior density as a function of cycle number (the magenta line is again a ten-point moving average).
3.1.2.1 Theoretical background
The second part of this example (spreadsheet EX4B.XLS) involves using the results from the stock assessment as the basis for an evaluation of the consequences of different levels of future harvest rate. The basic projection model is a stochastic version of Equation (3.1) that allows for temporal autocorrelation in process error (to mimic factors such as variation in recruitment that would propagate through time):
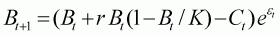 (3.2)
(3.2)
where
is the factor to account for process error:

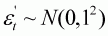 (3.3)
(3.3)
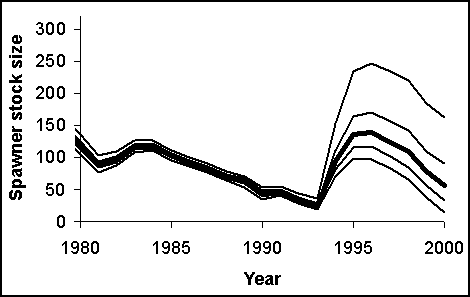
The value of e1997 (the process error for the first year of the projection period) has, for simplicity, been assumed to be 0. The scheme for determining the actual catch to be applied (Equation 3.2) as a function of the true level of biomass and the intended harvest rate allows for implementation error (Equation 3.4a) and error in estimating the biomass in the future (Equation 3.4b). The catch for year t is therefore determined by implementing (with error) a catch limit based on applying the harvest rate to a biomass estimate derived from a stock assessment. The estimates of biomass from the stock assessment are subject to estimation error which is itself auto-correlated, i.e.:is the amount of correlation in process error, and
is the process error variance.
where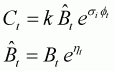
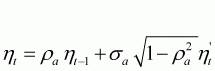
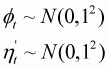
k is the harvest rate,The values for the parameters that determine the extent of process, implementation and assessment error, and the magnitude of the autocorrelation in the process and assessment error cannot be determined from the data, and are instead pre-specified by the analyst. It is also necessary to supply the estimate of biomass for the first year of the projection in order to apply Equation (3.4b). For the purposes of this example, the quantities
is the estimate of the biomass at the start of year t,
is the relative difference between the catch limit (=
) and the realised catch - the "implementation error",
determines the extent of implementation error,
reflects the amount of error in the estimate of biomass based on a stock assessment,
is the amount of temporal autocorrelation in stock assessment error, and
determines the variability of the estimates of biomass.
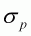 ,
,
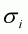 ,
,
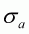 ,
,
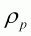 and
and
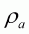 are assumed to be 0.1, 0, 0.1, 0.5 and
0.8 respectively. These choices reflect no implementation error and low levels
of process and assessment error. In contrast, the extent of autocorrelation in
process and (particularly) assessment error is assumed to be high. The initial
estimate of biomass is taken to be 813 - this is the biomass that corresponds to
selecting the values for r, q and K that maximize the
product of the prior and likelihood in spreadsheet EX4A.XLS).
are assumed to be 0.1, 0, 0.1, 0.5 and
0.8 respectively. These choices reflect no implementation error and low levels
of process and assessment error. In contrast, the extent of autocorrelation in
process and (particularly) assessment error is assumed to be high. The initial
estimate of biomass is taken to be 813 - this is the biomass that corresponds to
selecting the values for r, q and K that maximize the
product of the prior and likelihood in spreadsheet EX4A.XLS).3.1.2.2 Implementation issues
The values for the parameters that determine process, implementation and assessment error are stored in cells G6 to G10 in the sheet "Main" of spreadsheet EX4B.XLS while cell G12 contains the initial estimate of biomass. The number of harvest rates is stored in cell G4 and the harvest rates are listed in cells I5, I6,.. etc. The number of stock sizes considered when the results are summarised is stored in cell G5 and the stock sizes are listed in cells J4, K4, ...
The spreadsheet EX4B.XLS involves first pasting the values for the parameters r, q, and K from the stock assessment into the sheet "Posterior samples" (it may be necessary to press the F9 key for this to happen or to supply the directory in which the file EX4A.XLS is located). The subroutine "Project" in the macro "Projections" in the sheet "Main" controls how the projections are conducted. This macro first (through the subroutine "readpars") determines the harvest rates to consider and the bins to be used when presenting the results. It then conducts projections (through the subroutine "project") based on each of the 1,000 sets of parameter vectors for each of the harvest rates using the following algorithm:
a) Generate all of the normal random variates needed to apply Equations (3.2), (3.3) and (3.4), i.e. the values for the variablesThe results for each simulation and harvest rate are stored in column format in the sheet "ModelOutputs". The results from this sheet are then summarised in the decision table (Table 3.1).,
. The values are stored in cells M60 to O83. Note that the same random numbers are used for all harvest rates for a given set of values for r, q and K.
b) For each harvest rate, project the model from 1997 to 2020. Column K is used to compute values for the assessment errors and column L the process errors (Equations (3.4b) and (3.3) respectively). Cells G60 to G83 contain the estimates of biomass (the estimate for 1997 being pre-set to the maximum likelihood estimate of 813) while cells B60 to B83 and D60 to D83 contain the realised catches and the true biomass trajectory.
3.2.1 Stock assessment phase
3.2.2 Decision analysis phase
Stock-recruitment models are applied to populations (such as Pacific salmon) that have discrete generations. The objective of this worked example is to examine the long-term implications of different harvest rates on the population of sockeye salmon in the Skeena River. The final results of the analysis are presented in the form of a table that lists the expected average catch, the expected coefficient of variation of the catch, and the expected average stock size for eight different possible harvest rates over a 50-generation projection period.
As before, the analysis involves two spreadsheets. The first spreadsheet (EX4C.XLS) conducts a Bayesian assessment of Skeena River sockeye salmon using data on the observed numbers of spawners and the recruits from 1908-1952 to produce a large number (1,000 for the purposes of this example) of equally likely sets of model parameters. These 1,000 sets of parameters represent the alternative states of nature. The second spreadsheet uses the results from the Bayesian assessment as the basis for the series of 50-year projections for a variety of harvest rates. These projections allow for process error in the population dynamics, and error when estimating stock size.
3.2.1.1 Theoretical background
The model used for the analysis is the Ricker stock-recruitment curve (Ricker, 1954; Hilborn and Walters, 1992) fitted to data for the population of sockeye salmon in the Skeena River (Shepherd and Withler, 1958). The equations and likelihood function are:
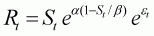
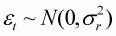 (3.5a)
(3.5a)
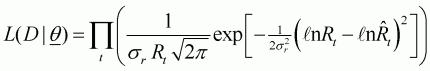 (3.5b)
(3.5b)
where
is the observed number of recruits during year t,
is the observed number of spawners during year t,
is the model-estimate of the number of recruits during year t:
is the parameter that determines the productivity of the stock (
is the slope of the stock-recruitment relationship at the origin),
is the parameter that determines the carrying capacity, and
is the standard deviation of the fluctuations in recruitment about the stock-recruitment relationship.
is considered
uncertain and is hence included in the parameter set to be estimated. It is
assumed that size of the spawning stock and the recruitment can be measured
without error, and that differences between observed and predicted recruitments
are due to natural variation (i.e. process error). The priors for the parameters
of this model (,
, and
) are
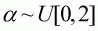 ,
,
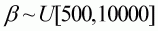 and
and
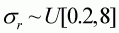 .
.3.2.1.2 Implementation details
The SIR algorithm (spreadsheet EX4C.XLS sheet "Main") is used
to generate the information needed to conduct the decision analysis. The
likelihood calculations (Equation 3.5) are evaluated in cells A16 to E60. The
variant of the SIR algorithm implemented in spreadsheet EX4C.XLS incorporates
the modification (see Section 2.6.1) that only outputs the set of parameters
actually needed for the decision analysis (rows 68 onwards). This substantially
reduces the amount of intermediate storage needed to perform the calculations.
The SIR algorithm (see the subroutine "sir") has been modified for this problem
so that it is run until 1,000 parameter sets have been generated. The threshold
(cell B12) is set to that corresponding to the maximum likelihood for any
combination of ,
, and
(2x10-13) as this
guarantees that no parameter vectors will be sampled more than once. For this
application, it was found that about 1 in 160 samples from the priors were
retained in the resample and that to obtain 1,000 unique parameter vectors took
about 20 minutes on a 200 Mhz desktop computer. A presentation of the joint
posterior distribution for a and b and the marginal posterior distributions for a, b, and
sr are shown for diagnostic
purposes on the sheet "Posterior graphs".
3.2.2.1 Theoretical background
The second part of this example (spreadsheet EX4D.XLS) involves using the results from the stock assessment as the basis for an evaluation of the consequences of different future harvest rates. The basic projection model extends Equation (3.5) to consider the relationship between recruitment and future spawner stock size:
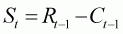 (3.6)
(3.6)
where
Ct is the catch during year t.Equation (3.6) and all subsequent modelling for this example ignore natural mortality. This would be an appropriate assumption if the fishery takes place immediately before spawning. The catch during year t is determined by applying a harvest rate to an estimate of the number of recruits:
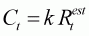 (3.7)
(3.7)
where
k is the harvest rate,
is the estimate of the number of recruits at the start of year t:
is the error associated with estimating the number of recruits during year t:
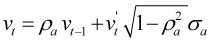
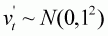
The values for the parameters a, b, and sr (Equation 3.5) are selected from the posterior distribution and the values for sa and ra are set equal to 0.2 and 0.7 respectively. The spawner stock size at the start of the projection is assumed (arbitrarily) to be 5000.
3.2.2.2 Implementation details
The values for the parameters a, b, and sr are copied from columns C, D and E, starting in row 68, in spreadsheet EX4C.XLS and stored in columns C, D and E starting in row 74 of spreadsheet EX4D.XLS (it may be necessary to press the F9 key for this to happen or to supply the directory in which the file EX4A.XLS is located). The COUNTIF function is used to determine the number of sets of parameter vectors to consider in the projections (cell B7). This is needed because it is not always possible to determine how many parameter sets will be generated when applying the SIR algorithm when the modification in Section 2.6.1 is implemented. The number of harvest rates to consider is listed in cell G2 and the actual harvest rates are given in cells G3 to G10.
The macro "ProjectSR" controls the calculations needed to construct the output table (cells H4 to J10). For each parameter vector and harvest rate, the calculation involves projecting from 5000 spawners at the start of year 1 to year 50 taking account of process and estimation error (cells B15 to H64).
3.3.1 Basic dynamics equations
3.3.2 Fitting to data
3.3.3 A worked example
Many of the world's fish stock assessments make use of information about the age-structure of the catches and keep track of the age- (and occasionally size-) structure of the population. Assessments based on age-structured models can utilize many data types (e.g. catch, catch rate, catch age-composition, catch size-composition, and tagging data). Bayesian assessments for the simplest types of age-structured models (e.g. Hilborn (1990b)) can be conducted using EXCEL. However, for most realistic age-structured assessment models (e.g. Gavaris, 1988; Fournier and Archibald, 1982; Deriso et al., 1985), it is necessary to use more powerful software tools. One tool that we have found useful is the package COLERAINE (Hilborn et al., 2000). This package incorporates options that allow the analyst to apply a general stock assessment model to typical types of assessment data and to use the results of the assessment to conduct a decision analysis. The calculations involve first finding the mode of the posterior distribution (i.e. the set that maximises the product of the likelihood and the prior) using the AD Model Builder package, then applying the MCMC algorithm to obtain the probabilities for different states of nature, and finally conducting forward projections as the basis for a decision analysis. The input to and output from COLERAINE is done through EXCEL, which allows the analyst to use EXCEL to produce data and output summaries for presentation to the decision makers.
This section briefly outlines the model that underlies the COLERAINE package, how the likelihood function is constructed, and provides details of a (simple) application of the package to data for southern blue whiting, Micromesistius australis, off the Campbell Islands, New Zealand. The software used to undertake these analyses is not included in this package.
The model keeps track of the age- and sex-structure of the population, and assumes that natural mortality occurs continuously throughout the year while the harvest occurs in the middle of the year (after half of the natural mortality):
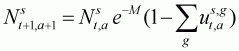 (3.8a)
(3.8a)
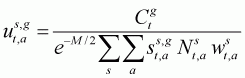 (3.8b)
(3.8b)
where
Equations (3.8a) and (3.8b) are very general, making allowance for multiple gear-types (fleets), each of which differ in terms of selectivity, and by allowing selectivity and weight to change as a function of time as well as of sex and age. Selectivity is modelled using a flexible function that allows it to be domed shape or asymptotic as a function of age. Time-trends in selectivity are modelled by allowing the age at full selectivity (i.e. the age for whichis the number of fish of age a and sex s at the start of year t,
is the instantaneous rate of natural mortality (assumed to be independent of age, sex, and time),
is the exploitation rate on fish of age a and sex s by gear-type g during year t,
is the relative selectivity of the gear used by gear-type g on fish of age a and sex s during year t,
is the catch (in weight) by gear-type g during year t, and
is the weight of a fish of age a and sex s during year t.
is 1) to change slowly over
time.The number of age 0 fish (births) is related to the spawner stock size according to a Beverton-Holt stock-recruitment relationship, i.e.:
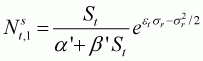 (3.9)
(3.9)
where
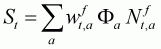 (3.10)
(3.10)The values for most of the parameters of the model (e.g. the parameters of the stock-recruitment relationship, the rate of natural mortality, and the annual recruitments) are estimable. However, it is necessary to pre-specify weight-at-age, fecundity-at-age, and the annual catches.is relative fecundity as a function of age,
a’, b’ are the parameters of the Beverton-Holt stock-recruitment relationship, and
sr is the standard deviation of the fluctuations in recruitment about the stock-recruitment relationship.
Priors have to be specified for all of the parameters. COLERAINE allows the prior distributions to be uniform, normal or log-normal. It has the capacity to make use of commercial catch rate data, survey indices of absolute and relative abundance, and data on the age-/size-composition of the catches by gear-type. The likelihood is assumed to be log-normal, except for age-/size-composition information for which the robust likelihood formulation of Fournier et al. (1990) is used.
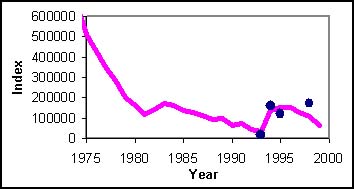
COLERAINE was used in a recent assessment of southern blue whiting, Micromesistius australis, off the Campbell Islands, New Zealand. The primary data available for this assessment were catches-at-age and acoustic survey estimates of biomass for 1993, 1994, 1995 and 1998 (Figure 3.1). The key feature of this example is the very large 1991 year-class that has dominated the fishery in recent years.
Figure 3.1: The acoustic estimates of biomass and the maximum likelihood fit to these data.
COLERAINE was used to obtain maximum likelihood estimates for the parameters (see Figure 3.1 for the fit to the acoustic estimates of biomass) and then to conduct a Bayesian analysis. The results of the stock assessment provided estimates for the historical trajectories of exploitable biomass, spawner stock size and recruitment. For example, Figure 3.2 shows a representation of the posterior distribution for the historical trajectory of spawner stock size.
Figure 3.2: Posterior percentiles (from top to bottom, 5, 25, 50 (bolded), 75 and 95%) for spawner stock size.
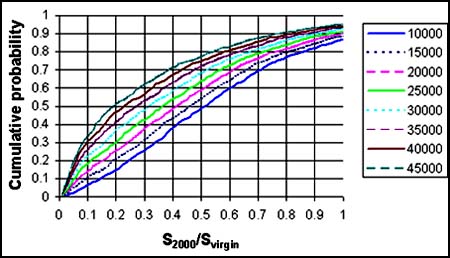
The results of the assessment were used as the basis for forward projections. In this case because the stock is declining due to the mortality on the 1991 cohort, the primary management concern relates to the relationship between the spawner stock size and its virgin level. COLERAINE was used to make 1-year-ahead projections for catch levels from 10,000 tonnes to 45,000 tonnes, recognizing that most of these catches are much larger than the long term sustainable yield, but that the 1991 cohort represents a special opportunity. Figure 3.3 shows the cumulative probability for the ratio of the 2000 spawner stock size to the virgin level for eight different levels of catch. This graph can be understood by choosing a target ratio (e.g. 0.4) and then going upwards to a specific probability (e.g. 0.5). These specifications correspond to a catch of 20,000 tonnes. Therefore, there is a 0.5 probability that the stock will be greater than or equal to 40% of virgin spawner stock size in 2000 if a catch of 25,000 tonnes is taken.
![]()
![]()
![]()
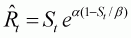
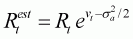
{kind=link}
{kind=link}