
Technical Annexes
TECHNICAL ANNEX 1 LOSS AND DAMAGE CALCULATIONS FROM POST DISASTER NEED ASSESSMENTS
Post disaster needs assessments (PDNAs) are available online and were downloaded from PreventionWeb,av ReliefWeb,aw the Global Facility for Disaster Reduction and Recovery (GFDRR)ax and World Bankay websites. Those utilized in this report as data sources span from 2007 to 2022.
In particular, data was retrieved from 88 post disaster assessment exercises conducted in 60 countries across seven regions and subregions, as follows: Africa, 30; Asia, 24; Caribbean, 10; eastern Europe, 8; Near East, 1; Oceania, 10; and South America, 5. The data cover eight hazard types: cyclone, 4; drought, 7; earthquake, 9; flood, 32; multihazard, 6 (including – La Niña, 1); storm, 23; tsunami, 1; and volcanic activity, 3. This pool of PDNAs included different assessment types, particularly damage loss and needs assessments, post disaster needs assessments and rapid damage and needs assessments.
PDNAs produce damage and loss estimates by economic sector, which makes it possible to compare impacts across the economy. All reported damage and loss values were converted to USD for 2017 (either from current USD or local currency unit) using consumer price index data from the World Bank.
To calculate the total agricultural losses caused by disaster types, damage and loss values reported were summed up and aggregated by hazard category. The industrial accidents reported did not include impact values for the agricultural sector and thus are not displayed as a category in the results.
The share of agricultural losses in productive sector losses corresponds to the reported damage and loss in agriculture for all PDNAs divided by the total reported damage and loss for all the productive sectors of all PDNAs (including agriculture, industry, commerce and trade, and tourism) by disaster category.
Similarly, the share of agricultural losses on total losses is calculated by dividing the reported damage and loss in agriculture for all PDNAs by the total reported damage and loss of all PDNAs by disaster category.
A subsector breakdown of the reported damage and loss was provided for 50 PDNAs, which accounts for 56 percent of the sample. For this subsample, damage and loss by agricultural subsector were aggregated in 2017 USD to compute the respective shares.
TECHNICAL ANNEX 2 ESTIMATING GLOBAL LOSSES FROM SECONDARY DATA
Estimates of the losses resulting from disasters in crops and livestock from 1991 to 2021 were developed using a counterfactual production scenario specific to disaster years. This scenario is then compared to reported production to assess the impact of the disasters.
Data source
Four data sources are used to estimate the different parameters of the models.
- Disaster data: The occurrence of disasters is taken from the EM-DAT database, which provides the most comprehensive coverage of historical disaster events. The disasters recorded in this database meet the criteria of either ten or more dead, 100 or more injured, a declaration of a state of emergency, or a call for international assistance. The analysis includes all scales of disaster events – small, medium, and large – falling under the following hazard categories: storm, flood, drought, extreme temperature, insect infestation, wildfire, earthquake, landslide, mass movement and volcanic activity. The global count for these disasters was 10 190 events from 1991 to 2021.
- Production and price data: Nationally aggregated annual production, yield, area harvested for crops and number of animals for livestock, and price data was taken from FAOSTAT for 197 countries or areas. A total of 186 items are included in the analysis, divided into 11 commodity groups: cereals, legumes, coffee, tea, cocoa and spice crops, fruits and nuts, oilseeds, roots and tubers, sugar crops, tobacco, rubber and fibre crops, and vegetables, as well as the key livestock products commodities of meat and meat products, milk and eggs.
- Agricultural total factor productivity data from 1991–2020 was retrieved from the United States Department of Agriculture.
Production in the counterfactual scenario for disaster years builds production values under the assumption that disasters had not occurred. Yield values are imputed from the yield time series by country of more than 12 700 commodities drawn from FAOSTAT. Yield values in disaster years are substituted with counterfactuals based on the disaster events reported in EMDAT.
The analysis primarily uses a list of matrices that contain yield time series with the reported value of non-disaster years and yield for disaster years removed, Yield (j,t,i·d) where j are countries or areas, t are years (1991–2021), i are the commodities and d=0, which is non-disaster years. Three interpolation techniques are used to compute the counterfactual yields for the disaster years, depending on the number of non-disaster years for each time series.
- For time series with more than five years without disasters in 1991–2021, this applies to 58 percent of the sample, missing yield values are estimated by interpolating non-disaster year yields. A structural model fitted by maximum likelihood with Kalman smoothing is used for this computation. The structural model decomposes the time series into state–space model components, first through a measurement equation of the yield variable defining the state vector α:
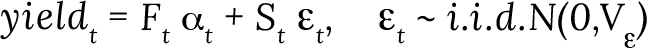
With α the vector of m state variables of dimension (m x 1), Ft and St are fixed coefficient matrices of dimensions N x m and N x r, r being the dimensions of the disturbance vector, and εt a r x 1 vector with zero mean and covariance matrix Vε.
The state vector can then be described in a state equation as follows:

With Gt an m x m matrix and Rt an m x g matrix of fixed coefficients, g being the dimensions of the disturbance vector, and ηt a g x 1 vector of mean zero and covariance matrix Wη.
The recursive Kalman filter allows for the model to be estimated in an iterative manner with the following equation:
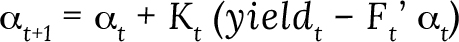
The Kalman gain (Kt) balances uncertainty between past observations and new information. If past observations are uncertain, Kt approaches one to give more weight to new information. If the difference between observed and estimated variables is unstable, Kt approaches zero.
• For time series with fewer than five years without disasters over 1991–2021:
- Estimation is based on country clusters – this applies to 39 percent of the sample. Countries are grouped into 20 groups derived from dynamic time warping based on agricultural total factor productivity (TFP) growth and factor analysis based on yield levels for all commodities. The cluster tendency of the data was assessed using the Hopkins statistic.244 A hierarchical clustering on principal component is conducted on the ten principal components resulting from the factor analysis conducted on 196 variables for 197 countries. Using the Ward criterion, countries are grouped together incrementally, while the growth of within-inertia corresponding to the last term in the following equation is minimized to form the most homogeneous clusters possible:
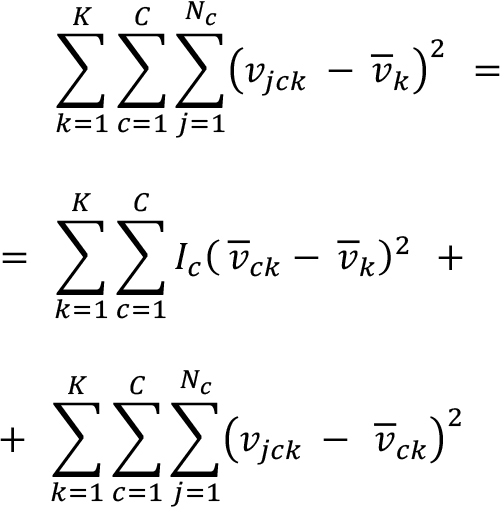
v is the value of the variable k, from the 10 principal components variables, for the country j of the cluster c.
For each cluster c, each item i, and each year t, an average annual yield change rate is calculated:

Where Nc is the number of countries in each cluster c.
Starting from the yields of 1990, this change rate is then applied to each country and each item to build a counterfactual time series from 1991 to 2021. The estimated counterfactual yield is calculated as follows for item i, country j and year t:
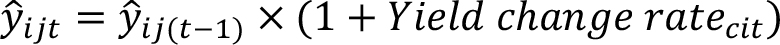
- Five countries were the only observation in their cluster (China, Guyana, Mexico, Peru and Uzbekistan). In these cases it was estimated using an ordinary least square regression model based on total factor productivity and lagged yield, following the equation:

yieldijt is the yield of for item i, country j, at time t
agTFPjt is the agricultural TFP of country j, at time t
Uijt is the error term
Predictors estimated are used to compute the counterfactual yield time series as follows:

- Estimation is based on country clusters – this applies to 39 percent of the sample. Countries are grouped into 20 groups derived from dynamic time warping based on agricultural total factor productivity (TFP) growth and factor analysis based on yield levels for all commodities. The cluster tendency of the data was assessed using the Hopkins statistic.244 A hierarchical clustering on principal component is conducted on the ten principal components resulting from the factor analysis conducted on 196 variables for 197 countries. Using the Ward criterion, countries are grouped together incrementally, while the growth of within-inertia corresponding to the last term in the following equation is minimized to form the most homogeneous clusters possible:
Once the counterfactual has been estimated, a yield deviation is calculated by the difference between the estimated counterfactual yield and the reported yield value in FAOSTAT.
To identify variability from non-disaster-related effects and remove background noise in yield variation, null distributions are computed by country and by item. Simulations were run on 10 000 simulated disaster matrices to build distributions of estimated yield deviations. Yield deviations under the 5 percent quantile of the distribution were removed from the estimated losses.
From yield losses to production losses, yields of a given year are multiplied by either the number of ha harvested, the number of animals slaughtered for meat products, or the number of laying or milking animals.
Production losses in values are obtained by multiplying tonnes by producer prices in FAOSTAT, expressed as 2017 purchasing power parity USD. Challenges arose from the earlier period of the time series in the 1990s when price reporting was less reliable than today. Without country prices, subregional medians, regional medians or world medians are used (12 percent of missing prices). When the local prices are three times higher than the world median, the world median is used.
TECHNICAL ANNEX 2A ATTRIBUTION OF THE LOSSES TO DISASTER EVENTS
Losses are estimated per year per country and disaggregated by items. However, 85 percent of the disaster years considered are multidisaster years. To attribute these losses to different hazards taking place in the same year, a mixed effects regression model was used, with the positive production losses for each item in each country in each year as the dependent variable, year, and the number of each type of disaster as fixed effects and item and country as random effects as follows:

Where yijt is the production loss of item i in country j and year t; the βi are the fixed effect parameters; xt is the year t with t from 1991 to 2021; x2jt is the number of droughts in country j and year t; x3jt is the number of floods in country j and year t; x4jt is the number of storms in country j and year t; x5jt is the number of earthquakes in country j in year t; x6jt is the number of extreme temperatures in country j and year t; x7jt is the number of landslides in country j and year t; x8jt is the number of wildfires in country j and year t; yi is the random effect for commodity i; yj is the random effect country for j; and εijt are the residuals, which are independent and normally distributed. The parameters of the model are estimated using restricted maximum likelihood.
Insect infestation, land movement and volcanic eruptions were deleted from the attribution exercise because there were too few observations (38, 19 and 151, respectively) in EM-DAT compared to the other types of events. However, these types of disasters were included in the loss estimation using the counterfactual models in Technical annex 2. The parameters of each type of event were used as weights to attribute production losses of each item in each country during each year to each type of disaster that happened in the country that year as follows:

Where wdt is the weight for disaster type d in country j and year t; βd is the model (1) parameter for disaster type d; and Xdjt is the number of disasters of type d in country j and year t. Then the loss for item i in country j in year t due to disaster type d was calculated as:
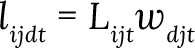
Where Lijt are the total losses for item i in country j and year t.
Those losses were added over items, countries and years to obtain the total losses by type of disaster:
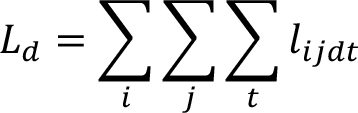
which was divided by the total number of disasters of that type, to obtain the average loss per disaster of each type:

Finally, this average loss per disaster of each type ad was calculated as a percentage pd of the average total losses of all types of disasters:
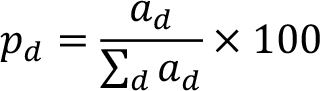
TECHNICAL ANNEX 3 CLIMATE ATTRIBUTION DATA AND METHODS
Full details on the four case studies (soy yields in Argentina, wheat yields in Kazakhstan and Morocco, and maize yields in South Africa) are published in a companion supplement technical paper. This section presents the data and methods used for section 3.1.
The attribution results presented are based on comparing observed yield records with estimated counterfactual and factual crop yield distributions. Factual yields are the yields simulated for climate as it has actually been evolving, while counterfactual yields are those simulated for climate as it might have been without greenhouse gas increases and other anthropogenic climate forcing factors. To that purpose, we build a statistical, multivariate crop yield model based on the observed crop yield data in the full length of their available record245 and observationally-derived climate data (20CRv3–W5E5). 246,247
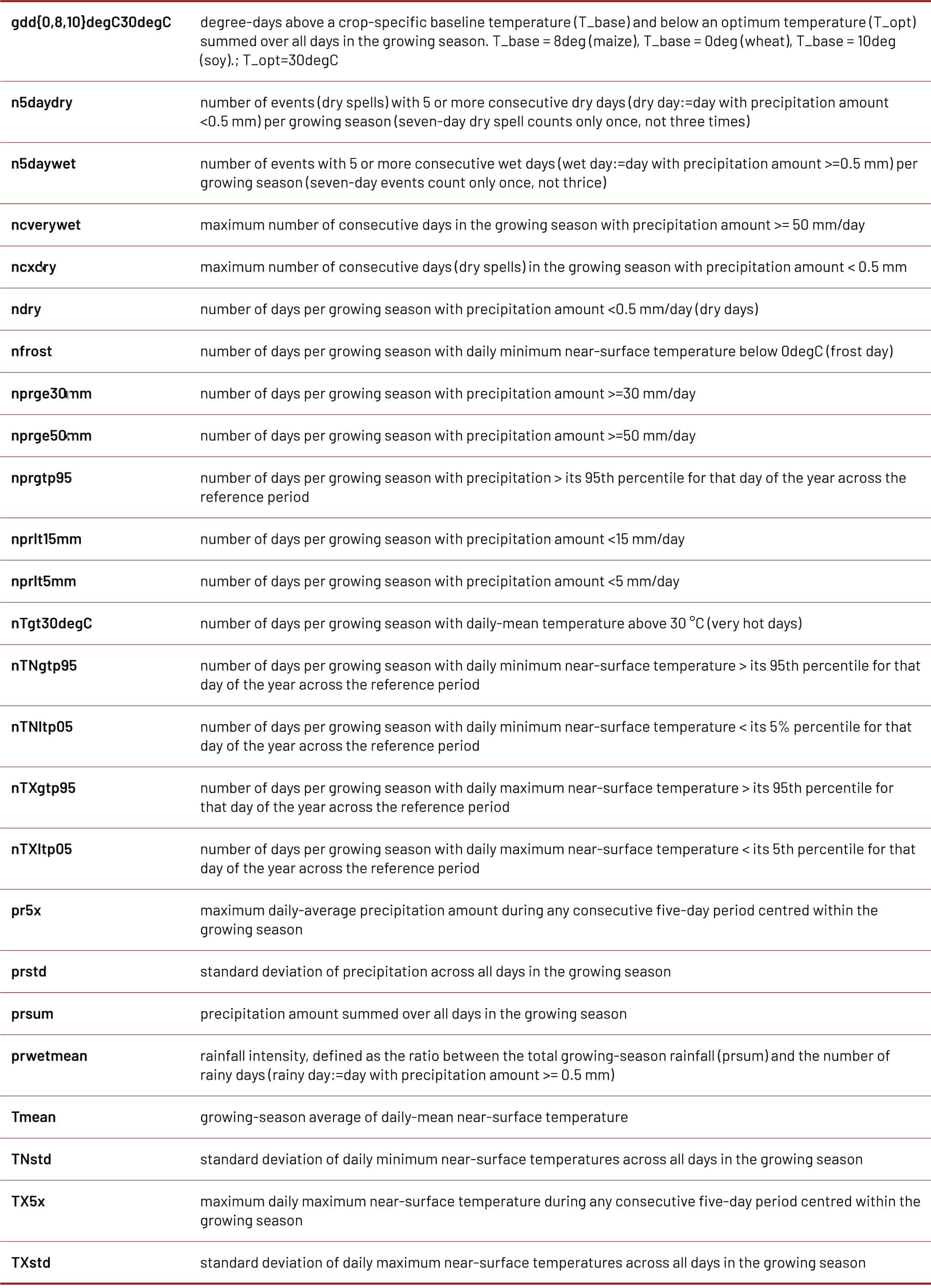
The modelling approach is constructed as to be generally applicable across case study countries or crops. For that, a pool of potentially relevant climate indices is determined (TABLE 8). This selection is informed by expert judgement including biophysiological factors and statistical crop modelling experience together with literature input.248,249,250 These indices are calculated for growing seasons specific to the sub-region and crop with the highest production at the gridded scale of available climate data (1.4 x 1.4-degree resolution). From all data (observationally-based climate indices and crop yields), anomalies are taken with respect to a non-linear trend to account for the confounding influence of agricultural management changes such as fertilizer application. The variables to be used for the linear regression model are then selected in a two-step process similar to Laudien et al.251 First, interdependency among the regression variables is removed by discarding those correlated by +/-0.7 or more with another variable that has a higher correlation with the yield data. The thus-reduced pool of variables is passed onto a Lasso regression that selects up to five variables that best explain the yield data. A linear fit gives the model parameters, and an out-of-sample validation is performed.
TABLE 8 POOL OF CLIMATE INDICES USED FOR THE STATISTICAL CROP MODELLING, WHICH IS THEN REDUCED BASED ON INDEPENDENCE AND EXPLANATORY POWER
The statistical yield model is then applied to a set of factual and counterfactual climate data, taken from the Detection and Attribution Model Intercomparison Project (DAMIP)252 component of the Coupled Model Intercomparison Project Phase 6 (CMIP6). A set of historical simulations include historical changes of both anthropogenic (greenhouse gases, ozone, aerosols, land use, etc.) and natural (solar irradiance, volcanic aerosol) climate forcing factors. A set of hist–nat simulations include only historical changes of the natural factors, while the anthropogenic ones are kept at pre-industrial levels. The 50 historical and 50 hist–nat simulations from DAMIP’s only large ensemble with daily data availability, the sixth version of the Model for Interdisciplinary Research on Climate (MIROC6)253 are for this purpose bias-corrected with the ISIMIP3 method (v3.0.2).254 Model evaluation255,256 shows no conspicuous biases beyond what is commonly accepted in climate impact modelling studies. For the case study regions specifically, precipitation in northern Kazakhstan has been shown to be well represented by the model);257 for precipitation in Morocco the same is true at least at the coast and in the north,258 which is the region of interest here. Earlier versions of the same model have been used to provide datasets for impact attribution studies,259,260 including agriculture.261,262
MIROC6’s equilibrium climate sensitivity (ECS) and Transient Climate Response (TCR) are with 2.60 °C and 1.58 °C at the lower side of the CMIP6 spread of 3.78 °C +/- 1.12 °C (ECS) and 1.98 °C +/- 0.48 °C (TCR) (mean +/- one standard deviation).263 More importantly, it is within the IPCC’s likely range for ECS of 2.5 °C to 5.1 °C (central value: 3.4 °C; very likely range: 2.1 °C to 7.7 °C) that is the best estimate to date, assessed based on multiple lines of evidence. It is slightly below the assessed likely range of 1.6 °C to 2.7 °C (central value: 2.0 °C) but within the very likely range of 1.3 °C to 3.1 °C. The model’s total aerosol effective radiative forcing is with -0.99 W/m2 well within the CMIP6 spread of -1.23 W/m2 +/- 0.48 W/m2 (mean +/- 5-95 percent confidence range) as well as within the IPCC’s assessed range of -2.0 W/m2 to -0.6 W/m2 (central value: –1.3 W/m2) (medium confidence).264 Together, these numbers imply that the model response to greenhouse gases and other forcing factors is plausible. The global temperature response at the lower end implies further that the attribution results obtained might be biased low rather than high, meaning they provide more conservative estimates.
The 50 simulations in either experiment vary among each other in terms of internal climate variability, i.e. they each have different weather realized, and together give a picture of the climate with and without greenhouse gases and other anthropogenic climate forcings. The factual climate model data is processed in the same way as the observationally derived climate data. The counterfactual climate model data is processed analogously, only that in the percentile-based thresholds, these thresholds for the computation of indices are taken from the respective factual climate data, and, similarly, that anomalies for the counterfactual indices are computed with respect to the non-linear trend in the respective factual rather than the counterfactual data. Using the variable selection and model parameters from the observationally derived statistical model gives the distributions of factual and counterfactual yields.
TECHNICAL ANNEX 4 METHODOLOGICAL NOTE ON THE COST–BENEFIT ANALYSIS CALCULATION
This note aims at presenting the different calculation methods used for the section in Part 4 on the benefit cost analysis and to demonstrate that the three approaches – preventative/risk reduction, anticipatory action (AA) and risk-informed action to curb the spread of desert locust (preventative and AA) – complement one another for building resilience. FAO has developed methodologies to calculate the benefit of farm-level disaster risk reduction good practice and anticipatory action interventions across a range of its programmes. While these methodologies are still being developed to include a wider range of programmatic activities, they provide an overview of the steps and structures of FAO’s benefit cost analysis methods for analysing farm-level DRR good practices and AA interventions.
Section 1: Methodology assessing the benefits of disaster and climate risk reduction good practices based on FAO’s 2019 publication, Disaster risk reduction at farm level: Multiple benefits, no regrets
Summary: The cost–benefit analysis (CBA) process calculates and compares the benefits and costs of suggested DRR good practice technologies for agriculture (crop, livestock, fisheries and forestry) and existing local technologies over time based on primary farm-level data collected on agricultural on a seasonal basis. On each farm, both the DRR suggested good practice technology and the existing local technology are monitored in different adjacent plots simultaneously. Plots that were not affected by hazards during the monitored period are the non-hazard scenario, whereas plots that were affected by hazards during the monitored period are part of the hazard scenario. Data collected at the farm level for the CBA include costs such as inputs, labour, maintenance and capital costs, and benefits, i.e. the gross value of production. The CBA compares the net benefits, i.e. the net return on investment in the suggested DRR good practice technology and existing local technology, over an observed period of analysis and then extrapolates these over a longer time (in this context, 11 years).
A three-step process was conducted to assess the benefits of the disaster and climate risk reduction good practices, including data collection, field-level appraisal and scaling up analysis.
Step 1: Data collection
The first step was to collect certain baseline data, which involved conducting background desk research on the target villages, households and their agricultural production activities, in addition to information on the hazard exposure, and extreme weather events and disasters that have affected them over the last five years. It also involved selecting target DRR practices, which were identified by a team of experts who also identified sites for the initial pre-selection and the villages to be involved in the study, based on local agroecological zones. These were then validated, which included identifying the households interested in participating in the field testing.
Selected study field plots of the participating farmers were divided into two parts of which one was used to test the innovative DRR good practice, while the other served as a control plot, on which the previously used farming practice was implemented, unchanged. In some cases, due to unavailability of land or in the case of perennial crops, the control plot was established on a nearby field, which had the same site conditions as the one on the DRR test plot to ensure that the conditions were the same for testing both the traditional as well as the good practice.
The performance on both the test and control plots was analysed season by season during non-hazard years (when no hazards occurred) and was compared to the performance under hazard conditions (when one or more hazards occurred). In this way, practices could be identified that:
- performed best under hazard conditions; and
- performed at least as well, in the absence of hazards, as the conventional agronomic practices used previously.
Step 2: Field-level appraisal through cost–benefit analysis
The second step was to create the CBA, which quantitatively evaluated the net benefits (feasibility and effectiveness) derived from the new DRR good practice as compared to the previously used practice, under both hazard and non-hazard conditions. CBA involved assigning a monetary value to the costs, added benefits, and avoided costs associated with implementing both the good practice and the previously used practice, under both hazard and non-hazard conditions. The valuation of unpriced goods or services, such as family labour or open-access water resources, was estimated by using prices of marketed goods as substitutes. TABLE 9 shows that the types of costs and benefits varied depending on the type of practice.
TABLE 9 COSTS AND BENEFITS

The BCR was used to compare practices and to indicate the relationship between the costs and benefits, which is expressed as a ratio of the discounted present value of benefits to the discounted present value of costs.
The net returns were also evaluated through calculating the net present value (NPV) of both the good practice and the previously used or common practice, which was then compared to evaluate the added benefits (such as increased productivity) and avoided damage and losses achieved by the good practice. An appraisal period of 11 years was used, applying a 10 percent discount rate with a 5 percent and 15 percent sensitivity check. In general, on the one had, a positive NPV indicates that the present value of benefits outweighed the present value of costs over the assessed period. On the other hand, a negative NPV shows that the upfront and running costs are not fully repaid by the benefits accrued over time. A practice is considered more profitable when its NPV is higher.
Besides the quantitative analysis of the field level appraisal, a qualitative analysis was also conducted of the social and environmental co-benefits of the good practice as perceived by farmers. This information was gathered through semi-structured interviews and, when feasible, focus group discussions. The topics covered included the socioeconomic feasibility of the practice, its sustainability, and the associated social and environmental benefits. These benefits encompassed reduced vulnerability, increased income and livelihood opportunities, the potential to alleviate temporary food shortages during and after disasters, and enhanced nutrition. The discussions also explored whether these benefits helped mitigate adverse environmental impacts. In this way, additional benefits, unintended impacts and barriers were qualitatively identified and assessed, which may not become known if only quantitative evaluation is undertaken.
Step 3: Scaling up analysis
The third step that was undertaken as part of the FAO 2019 study, involved assessing the scaling up potential of selected good practices. For this, customized simulation models through the system dynamics methodology were used to simulate the potential impacts of scaling up three highly promising good practices. Through the system dynamics approach, biophysical variables can be integrated in monetary models and vice versa. This helps to better understand the dynamic non-linear behaviour of complex systems over time based on key causal relationships and feedback loops across its indicators. The simulation models that were developed were based on the findings from the field-level appraisals and context-specific potential barriers (e.g. agroecological and socioeconomic constraints) were also considered.
The simulation models were established for two main scenarios: i) the good practice scaling up scenario that assumes that the assessed DRR good practice is widely adopted by the farmers; and ii) a business-as-usual scenario is introduced during the simulation period of 11 years, functioning as though only the previously used practice by farmers was used without any other DRR good practice. In addition, three hazard frequency scenarios were simulated: i) a low-hazard frequency, where hazards recur every three years; ii) a medium-high-hazard frequency, considers hazards returning every two years; and iii) a high-hazard frequency, which assumes the hazards recur yearly.
Section 2: Anticipatory action benefit–cost analysis methodology
This note presents the calculation methods used for the benefit–cost analysis from the implementation of anticipatory action interventions. FAO has developed frameworks for calculating the direct benefits from AA interventions across a range of its programmes. While these methodologies are still being developed to include a wider range of programmatic activities, this methodology provides an overview of the steps and structures of FAO’s benefit–cost analysis methods for AA.
The main output of the benefit–cost analysis is the benefit–cost ratio of the anticipatory action intervention. The BCR measures the ratio between the direct benefits resulting from anticipatory actions and the costs of designing and implementing the anticipatory actions, all expressed in present monetary values. Therefore, the BCR provides a summary of the value for money of acting before the occurrence of a forecasted hazard to prevent or mitigate its impact on the livelihoods of affected communities. To conduct this, FAO gathers quantitative data through structured interviews with beneficiary and control households, the counterfactuals between the two samples are used to form the bases of outcomes from AA interventions that then follow a range of formulas calculating added benefits and avoided losses from the intervention. The key steps to calculate the BCR of an anticipatory action project are summarized here.
Step 1: Data collection
The benefit–cost analysis of AA projects is based on primary data collected at the household level for both control and beneficiary samples. The differences between these two sample populations forms the basis of the calculation of benefits of the analysis.
There are several actions that are implemented to ensure the accuracy of the data collected.
Samples for beneficiary and control groups are collected and are stratified along several social, demographic and economic characteristics to ensure that the control and sample populations are as close as possible, to avoid any bias in data collection that may skew the results. Statistical tests are performed to confirm the comparability of the samples.
The timing of data collection is important to ensure that the most accurate data are collected, and the type of intervention that is being implemented is also accounted for and is representative of the project outcomes.
Prior to the calculation, data are reviewed to assess any inaccuracies that may arise from the enumerators. Assessing these issues early can greatly assist the quality of the analysis and remove or limit any data collection errors that might hinder the analysis.
Step 2: Calculating the costs of the interventions
The valuation of project costs per beneficiary household is a fundamental step in the calculation of the benefit–cost ratio of anticipatory actions. All the costs related to the analysed activities are accounted for, including direct costs (e.g. procurement) as well as logistics, administrative and other support costs. Project costs are calculated based on reported project expenditures detailed on FAO’s financial reporting systems available on the Field Programme Management Information System (FPMIS).
Two categories of costs are considered:
programme costs, which include the costs of purchased items, logistics and letters of agreement with implementing partners; and
support costs, which are the running costs of project implementation, including administrative costs, field monitoring, general operating expenses and technical support services, among others.
Step 3: Calculating the benefits of anticipatory actions
The benefit–cost analysis only focuses on the direct benefits of the anticipatory actions, i.e. benefits derived directly from FAO’s assistance.
Two types of direct benefits should be analysed:
added benefits: early actions determine an increase in agricultural output or an increase in the value of agricultural output; and
avoided losses: early actions prevent or reduce damage and losses caused by hazards on agricultural assets and/or output.
The benefits are calculated by analysing the differences in outcome variables between beneficiary and control groups. Statistical tests are performed to evaluate the significance of the observed differences.
Importantly, qualitative data are also collected – through focus group discussions and key informant interviews – and analysed to gain an in-depth understanding of the perceptions of affected communities; triangulate the quantitative findings; assess the strengths and weaknesses of the decision-making and operational procedures followed to link early warnings with anticipatory actions; and derive fundamental insights for improving future programming.
Example: the methodology used to calculate avoided losses of animal mortality
The example outlines the steps taken to calculate the avoided losses of animal mortality.
Calculate the total number of goats owned by each household. The number should include goats owned before the start of the project interventions plus goats purchased during the project.

For each household, calculate the mortality rate (MR) of goats by dividing the reported number of goats that died due to drought by the total number of goats owned:
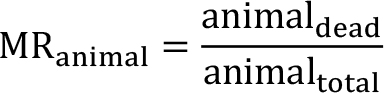
Calculate the average mortality rate of goats for the whole beneficiary sample and for the whole control sample. Note: households that do not own goats should not be included in the calculation of average goat mortality rates.
Calculate the difference in average goat mortality rates between beneficiary and control samples.

Calculate the total additional number of goats that survived (or died) throughout the project duration. Multiply by the total number of goats owned by beneficiary households.

Calculate the value of the additional number of goats that survived (or died) throughout the project duration using the average market price of goats during the project implementation period.
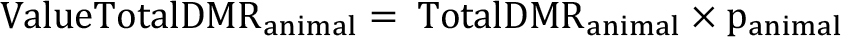
Calculate the value of saved animals per household.

Step 4: The benefit–cost ratio
The BCR is calculated as the ratio between total costs per beneficiary household and the sum of all statistically significant added benefits and avoided losses calculated based on replies from beneficiary and control households. Sensitivity analysis is performed by altering some of the key assumptions adopted in the BCR calculations and assessing the results variation. In particular, worst-case and best-case scenarios are simulated.
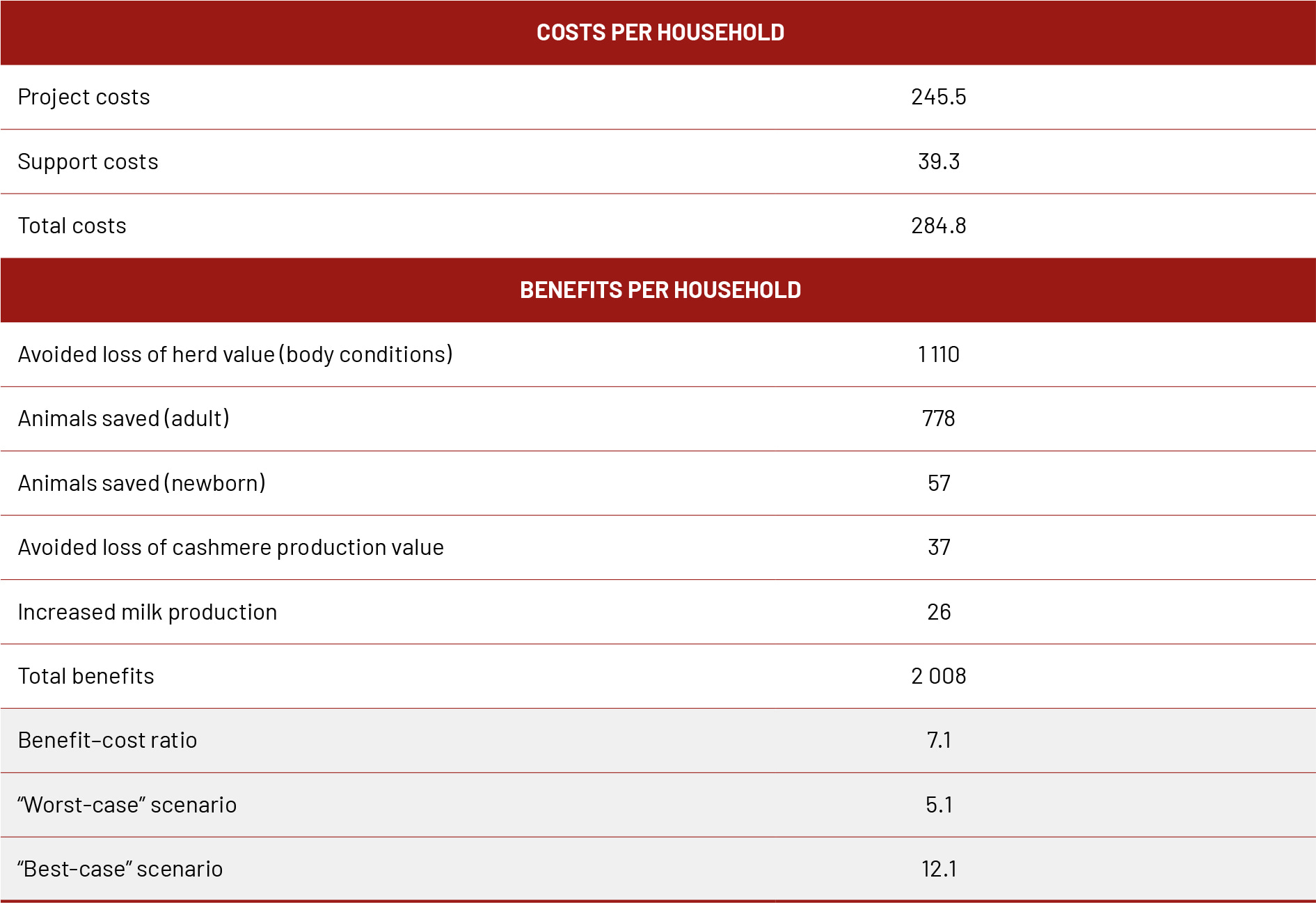
TABLE 10 provides an example of how this would be calculated given a project’s costs and total accumulated benefits and avoided losses.
TABLE 10 COSTS AND BENEFITS PER HOUSEHOLD
TECHNICAL ANNEX 5 METHODOLOGY TO CALCULATE AVOIDED LOSSES FOR RISK-INFORMED DESERT LOCUST INTERVENTION
Based on the experience of implementing the desert locust control operation, a new living methodology was developed to calculate the return on investment of FAO’s risk-informed interventions, using various considerations and assumptions. The FAO Locust Handbook and FAO-Desert Locust Forecasting Manual were consulted for desert locust food requirements and the average density of the swarms and bands. The control operation profile derived from these sources was used to determine the size of the swarms, infested areas and areas treated and avoided losses of green matter/vegetation because of areas protected.
Desert locust food requirements (FAO-locust handbook and FAO-DL forecasting manual):
- 1 adult consumption (lifetime) = 60 gr of green matter/vegetation
- 1 hopper consumption (lifetime) = 3.7 gr of green matter/vegetation
Considering the average density of swarms and bands (Desert Locust Forecasting Manual and FAO Desert Locust Guidelines I Biology and Behaviour), it is estimated that the consumption requirements per hectare are:
- Swarm consumption (lifetime)/ha = 36 tonnes of green matter/vegetation
- Hopper bands consumption (lifetime)/ha = 4 tonnes of green matter/vegetation
Control operation profile:
Reports from the field provided details about the nature of the control operation (air and ground) as well as the ratio of hoppers to swarms. Two years of control operation reports indicated that 80 percent of hectares treated were infested with immature and mature swarms, while 20 percent of areas treated were infested with hoppers at various stages (from instar 1 to 5).
Based on this information, every time we treat one hectare, there are around 30 tonnes of green matter and vegetation that is not consumed by desert locusts (protected).
The productive green matter:
In order to estimate losses and impacts affecting the productive livelihoods of farmers, agropastoralists and pastoralists, we need to introduce (adopt) the concept of productive green matter and vegetation. We considered productive vegetation to be any palatable species (for animals) in the rangeland and/or farms and any species directly used as food (for humans).
- Assumption 1. It is estimated that during their lifetime, desert locusts will get only 50 percent of their dietary requirements from productive green matter and vegetation, while the remaining half will come from the leaves of unpalatable or non-food producing species.
- Assumption 2. Looking at the land cover averages in the areas where desert locusts have been most present during the current upsurge, it is estimated that of the total productive green matter and vegetation consumed, 70 percent comes from rangeland and 30 percent from farmland.
From desert locust consumption to rangeland and crop losses:
Following these assumptions and the considerations that will follow, it is possible to calculate how much one hectare of desert locusts (hoppers and swarms) can destroy over their life cycle in rangeland and farmland.
Consideration 1. Average productivity value for rangeland at 0.75 T/ha in East Africa.265
Consideration 2. Cropland protected in the Horn of Africa, applying 3 tonnes/ha as average green forage yield ratio and considering a ratio leaf/stalks of 0.49.
Consideration 3. Average production of cereals (major crops in arid and semi-arid land areas): 1.3 tonnes and an estimated 50 percent reduction in yield due to desert locust.
Consideration 4. 1 TLU/ha carrying capacity of rangeland and an estimated 60 percent in the reduction of carrying capacity due to desert locusts. Sixty percent reduction (in the case of a desert locust infestation) is estimated taking into consideration field observations.
Consideration 5. 4.5 TLU/HH is used as an average in the region.
Consideration 6. USD 300 is used as an average price per tonne of cereal.
Consideration 7. 150 kg is used as average cereals requirement per person/year.


