![]()
![]()
![]()
Part A: Purposes
Part B: Types of survey
Part C: Methods of data collection
Stage 1
Stage 2
References
Diagnostic surveys are conducted if the need for further systems research is indicated during the descriptive stage. This module outlines some of the principles of conducting diagnostic surveys and lays the foundation for Modules 3-10. It deals with some of the more practical issues applicable to diagnostic survey, including selection of samples, training of enumerators, designing questionnaires etc., which often determine the success of such surveys.
Diagnostic research may not always be necessary. It can be expensive and time consuming, and scarce resources should not be wasted in collecting unnecessary information. This can be prevented by stating at the start which informal on is not desired, so that research priorities are clearly understood (Gilbert et al, 1980, p. 50).
Diagnostic surveys are formal and structured. They are conducted with a randomly selected group or farmers or pastoralists to provide a quantitative basis for conclusions drawn during the descriptive stage. Enumerators are normally used to conduct interviews and collect data on particular aspects of the production system.
Diagnostic surveys can also be used to:
· redefine target groups
· test hypotheses made about relationships/linkages
· identify further relationships/linkages, and
· identify priorities for research.
Redefinition of target groups. When recommendation domains are identified during the descriptive stage farmers/pastoralists are broken into groups based on one or two characteristics (e.g. access to inputs, wealth etc.). Because diagnostic surveys use random sample methods, variability in these characteristics within a target group can be re-examined and quantified, and the initial groupings can be refined or modified.
Testing of hypotheses. For example, initial exploratory surveys may have suggested that the time of planting was related to the number of oxen in households. This hypothesis could be verified by conducing diagnostic surveys.
Identification of other relationships. Often, relationships/linkages not specifically recognised during the descriptive stage are found coring diagnosis. For example, a diagnostic survey of cattle herd size and household size in Matabeleland, Zimbabwe, in 1982 indicated that household size increased with increasing herd size (Table 1). Relationships like this can have a major effect on production and should be carefully examined and tested for statistical significance.
Table 1. Relationship between household size and herd size, Matabeleland, Zimbabwe, 1982.
|
Household size |
Herd size |
Standard error |
|
1-7 |
9.6 |
1.2 |
|
8-20 |
21.7 |
2.8 |
Source: Doran (1982).
Identification of research priorities. It is not always easy to identify research priorities with any confidence during the descriptive phase of livestock systems research. The pre-screening of technologies is only tentative, and quantitative data are required to continue the process of priority selection/identification. The options for further research can be narrowed and priorities can be more clearly defined through diagnostic surveys. Techniques such as partial budgeting can, for example, be used to examine the financial implications of making a change at the farm level (Module 3, Section 2).
Quantitative information collected during the diagnostic stage of livestock systems research may be helpful in the design and interpretation of on-farm experiments by specifying management practices (e.g. the timing of different operations) and the criteria used by farmers/pastoralists to evaluate different technological options (CIMMYT, 1985). The farmers or pastoralists in the target group can also be selected to take part in future trials.
Single-visit, single-subject surveys
Single-visit, multiple-subject surveys
Multiple-visit, single-subject surveys
Multiple-visit, multiple-subject surveys
The type of survey used in diagnostic research will largely depend on the:
· type of data to be collected
· degree of accuracy required
· manpower and financial resources available
· logistical considerations, and
· availability of complementary data.
Since each situation is different, only general guidelines can be given which should then be adapted to the prevailing circumstances and the research requirements. There are essentially four types of survey used in diagnostic research:1
· single-visit, single-subject surveys
· single-visit, multiple-subject surveys
· multiple-visit, single-subject surveys, and
· multiple-visit, multiple-subject surveys.1 Surveys are sometimes classified on the basis of whether data are obtained by recall or by observation or direct measurement. When data are collected by recall, the information derives from the respondent's memory, while actual measurements are taken at the time of data collection (e.g. when measuring animal liveweight gains).
In this type of survey, one particular issue is identified for research (e.g. herd or flock structure, household assets, herd/flock numbers etc.) and data are collected from all sample households on that issue alone.
The main advantage of single-visit, single-subject surveys is that data on particular subjects can be collected in a relatively short time and at a low cost. Many farmers or pastoralists can normally be included in the sample to improve the chances of obtaining representative results. In addition, the supervision of enumerators tends to be minimal.2
2 However, this is not always the case. When, for instance, average weight gain (Module 5) is being estimated by once off surveys, close supervision of measurements is required, but less when collecting data on assets, herd/flock structure etc.
Single-visit, single-subject surveys cannot be used when observation and measurement over prolonged periods are required (e.g. for estimating individual animal weight gain performance - see Module 5). Since they are confined to the study of one issue only, they are also unsuitable for the study of relationships or linkages.
This type of survey is used to collect data on several subjects/issues awing one visit. These data can then be used to establish relationships/linkages between different variables, such as livestock holdings and cultivated area; household size and the marketed offtake of cattle; or livestock holdings and off-farm remittances.
Single-visit, multiple-subject surveys largely rely on recall by the respondent. If the periods of recall are long (e.g 1 year), data collected on farm activities/transactions performed regularly throughout the year will tend to be unreliable (Module 4), while less regular operations (e.g. cattle sales) are recalled more reliably over relatively long periods of time (see example below). Frequent but irregular events (e.g. expenditures on food, labour inputs) are usually very cliff cult to recall (Solomon Bekure, 1983; Grandin and Solomon Bekure, 1983).
Increased accuracy of results usually implies increased survey costs and/or reduced number of surveyed variables. When accuracy is less important than, for instance, a general description of the system, single-visit surveys will often be preferred to repeated recall or observation (Collinson, 1972; Gilbert et al, 1980, p.50).
Single-visit surveys of a large number of respondents are commonly conducted in systems research. They are often complemented by more frequent interviews with a smaller, non-random sample of producers, known as case studies,3 to reduce measurement errors (Gilbert et al, 1980).
3 Case studies are variants of the informal curvy in which a few households are chosen within the sample for intensive study. They my provide data on several household activities, thereby contributing to a better understanding of linkages at the household level (Grandin and Solomon Bekure, 1983).
|
Example: In 1982, ILCA conducted two concurrent surveys (one with monthly and one with daily interviews) of household budgets in a non-random sample of households in Kenya's Maasailand. Table 2 shows that the daily and monthly recalls of expenditures on livestock transactions (irregular events) were not much different, but that of expenditures on food (regular and frequent events) differed greatly between the two types of interview. |
||||||||
|
Table 2. Monthly (M) and daily (D) recalls of cash expenditure in four households, Merueshi Group Ranch, Kenya, October 1982. |
||||||||
|
|
Food |
Livestock |
Other items |
Overall total |
||||
|
M |
D |
M |
D |
M |
D |
M |
D |
|
|
Expenditure |
||||||||
|
Kenya shillings |
1308 |
3047 |
1905 |
1980 |
1188 |
1015 |
4401 |
6042 |
|
Per cent of total |
30 |
50 |
43 |
33 |
27 |
17 |
100 |
100 |
|
Monthly: daily recall ratio |
0.43 |
|
0.96 |
|
1.17 |
|
0.73 |
|
Notes: M - monthly recall; D = daily recall.Source: Solomon Bekure (1983, p. 293).
If, after the initial enquiry, more detailed information is needed on one particular issue (e.g. individual animal losses or mortalities) over a prolonged period, repeat or 'continuous' surveys are conducted. Such surveys tend to be costly and generally require a high degree of supervision. The data may be obtained by recall or by direct observation and the frequency of data collection will depend on the type of data being collected.
|
Example: To collect reliable data on liveweight, milk production, labour use and household expenditures in the traditional systems, the frequency of visits required will be as follows: | |
|
Cattle liveweight gain: |
1st, 3rd, 7th and 18th month after birth |
|
Cow's milk: |
four visits/month over 2-3 months |
|
Sheep and goat milk: |
once a week over 2-3 months |
|
Labour use and household budget: |
very frequent measurements over a year or a season. |
Since multiple-visit, single-subject surveys are costly and require considerable supervision, the possibilities of obtaining the same data by other means should be explored. Often it may be better to use less precise methods with larger sample sizes (for details see Part C of Modules 3-6). Collinson (1972) stated that detailed measurement/observation, and the additional costs involved, are justified only if the implied level of accuracy sufficiently and consistently improves the understanding of the issue being researched.
Multiple-visit, multiple-subject surveys include farm management surveys which deal with a wide range of topics over a longer period of time (usually 1 year). They are costly in terms of data collection and handling and involve heavy supervision. Because masses of information are collected, data analysis and reporting are often delayed. In addition, enumerator boredom and respondent fatigue are common, and continual checks for accuracy and consistency must be made. The emphasis in systems research has, therefore, shifted to more 'efficient' (but possibly less accurate) rapid survey methods of data collection (Collinson, 1972; Gilbert et al, 1980).
Scheduling of survey operations
Design of questionnaires and record sheets
Recruitment, training and supervision of enumerators
Pilot testing of questionnaires
Sources of error
Sampling methods and errors
If the data collected in formal surveys are to be of any value, attention should be given to:
· scheduling of survey operations
· design of questionnaires and record sheets
· recruitment and training of enumerators
· pilot testing of questionnaires, and
· sampling methods and sampling error.4
4 Much of the discussion in Part C of this module is based on ClMMYT's (1985) manual on diagnostic research and on the field experiences of ILCA staff involved in system diagnosis (e.g. Grandin and Solomon Bekure, 1983).
To ensure the survey method adopted must be practical, efficient and inexpensive, which, in turn, means that operations should be carefully planned in advance and that schedules should be adhered to as closely as possible.
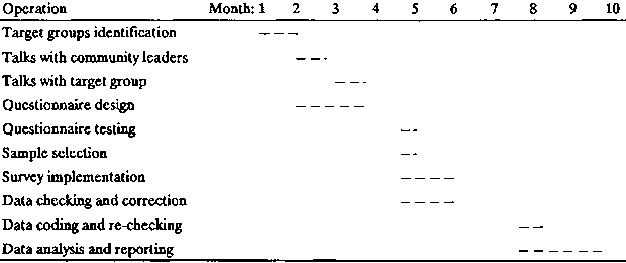
Operations whose starting and ending times need to be scheduled include:
· target group(s) identification· talks with community leaders and political and government officials about the aims of the survey of each target group
· talks with farmers/pastoralists within each group about the aims of the survey
· questionnaire design
· questionnaire testing and adjustment
· sample selection within each target group
· survey implementation/supervision
· correction of obvious non-sample errors
· data coding, re-checking and entering into the computer
· listing of computer data and re-checking for data entry errors, and
· data analysis for report writing.
Simple bar charts (Table 3) help the research team to think through the processes involved step by step and to determine the expected time of completion of each operation. For some operations (e.g. data coding, re-checking and entry), it is relatively easy to determine the amount of time required, while for others (e.g. selection and training of enumerators), allowance must be made for delays or for overlaps. If the research conducted is to become credible, the data collected must be rapidly analysed and the results published.5 Sufficient time should always be allocated to these tasks.
5 The analysis and presentation of survey results are discussed in detail in Module 11.
Table 3. Schedule of a hypothetical single-visit diagnostic survey.
Questionnaires are prepared to obtain answers to specific questions, while record sheets are used to record observations and/or measurements. To meet the stated objectives of the survey, the content and format (or design) of the forms to be used should be carefully considered at the outset.
Content
Pour questions need to be answered regarding the content of a survey form. They are:
· What are the objectives of the survey?
· What information is needed to achieve those objectives?
· How will the data be analysed and processed?
When deciding on the content of the survey form, it is advisable to follow four steps:
· Define priorities for the surveyThis should be done on the basis of the findings of initial exploratory surveys or the insights obtained from a review of secondary data sources (see Module 1).
· List the main categories of data to meet these priorities
· List the important components of each main category of data
For instance, if information on household structure is needed, data on the age and sex of household members, and their occupations and availability for farm work, should also be obtained. If livestock management is to be related to labour supply, the indicators of management performance, and management practices, which might be affected by labour supply must be identified.
· Specify methods of presentation and analysis
This must be done for each type of data collected and for each type of analysis to be made, and involves such considerations as how the data will be tabulated and what computer programmes will be used to analyse and present the data.
In general, the content of the survey form will vary with each target group, reflecting the different characteristics of that group identified during the descriptive stage (CIMMYT, 1985).
Format
Proper format (or design) will take into account the structure of the survey form and the wording and layout of its questions.
Structure. This includes considerations about the two main parts of any survey form: the title page and the part of specific questions/records. The title page should give:
· the respondent's name or code number
· the name or code number of the enumerator
· the location of the surveyed household (ward, village etc)
· the date of the survey
· the starting and ending times of the interview, and
· the number of the questionnaire.
This information serves as a general record of the survey conducted, but it is also a means of identifying respondents, should the need arise, and of checking on enumerators if the data entered are suspect.
After the title page, the rest of the questionnaire should be structured using the following guidelines:
· Order the topics of inquiry into logical sequence and mark them clearlyMoving from one topic or category of data to another in a logical manner improves the understanding and cooperation of the respondents and facilitates data analysis. It also helps the enumerator to ascertain whether each category of data has been dealt with exhaustively. Marking each section or group of data with an alphabet (or another distinct marker) is also helpful in that it breaks the questionnaire/record sheet into distinct categories of information.
|
Example: In a single-visit, mutt-subject questionnaire intended for a mixed farming system, the subject categories for data collection might be grouped as follows: |
· Sequence questions within each category of information specifiedCIMMYT (1985) gives six generally applicable rules believed to facilitate this task:
- Move from the general to the specificFor instance, find out the size of the household before asking questions about the age and sex of its members.
- Move from the simple to the complex
Questions which require a simple "yes" or "no" should precede those which have multiple choices and require considerable thought on the part of the respondent.
- Maintain a logical flow in the questions asked
Attempt to order questions so that one question leads logically to the next, or helps to elaborate the questions which follow.
- Move from recent to more distant events
- Sequence questions about farm activities in the order the activities are normally performed. For instance, questions about ploughing should precede questions about harrowing.
- Leave opinion and sensitive questions to the end
Example of an opinion question is, What cattle diseases do you consider most important? A sensitive question is, How many head of cattle do you own/hold?
Questions asked within each subject category should be identified by a number. The instructions for the enumerator should be specific, clearly worded and written in an obvious place so that he/she can find them. Space should be left for the enumerator to make comments about the responses obtained. An example of a questionnaire layout is given in the Appendix.
· Code all questions
Questions should be coded before the survey is conducted. Answers to questions may be in numeric form or may be stated in words. If they are in numeric form, sufficient space should be provided for the entry of the maximum possible value. If the answers are not in numerical form, it is usual to group them (ex-post and after the survey is completed) into different categories and to provide a code for each category.
For open-ended question, coding is done after the form has been returned, by grouping the answers given into major response categories and assigning a code number to each category.
Codes should also be provided for missing responses, which may be due to the enumerator failing to ask the relevant question(s) or because the respondent refused to give an answer. The reason for non-response should be clarified. The code used for a missing response is optional, but should be different from the codes given to particular responses (e.g. 101 to 106 in the example below). Often the same number (e.g. 0 or 99) will be used to indicate missing responses throughout the questionnaire.
|
Example: | ||
|
Question: |
Which source of cash do you primarily use to pay for the purchase of food for your household? | |
|
|
(Enter code number) | |
|
Answer: |
Cash obtained from |
|
|
101. Sale of cattle | ||
|
102. Sale of smallstock | ||
|
103. Sale of crops | ||
|
104. Sale of handicrafts or home-made beer | ||
|
105. Off-farm earnings | ||
|
106. Other sources (specify)............................................................................................................ | ||
|
Option 6 is an example of a 'catch-all' data category used for answers thought to be relatively unimportant. If a large proportion of the answers falls into this category, the importance of the other categories must have been misjudged. Additional categories should therefore be identified on the basis of the answers given under option 6 and provided with new codes. | ||
· Include data cross-checking mechanismsAlthough well trained enumerators will often detect inconsistencies, subtle cross-checks should be built into the questionnaire to ensure that the data obtained are consistent. Some time should be spent with the enumerator before the survey to explain why and how cross-checks are used. When an inconsistent response is detected, he/she is expected to remind the respondent of an answer given before to a similar question and clarify the issue with him before moving on.
|
Example: | |||
|
Q: Do you own/hold cattle? | |||
|
|
(Enter code number) | ||
|
A: 1. yes |
2. no |
2 | |
|
The respondent indicated that he owns/holds no cattle. At a later point in the questionnaire there was a cross-check: | |||
|
|
Q: How did you pay for the fertiliser you used on the maize crop this year? | ||
|
|
A: By using cash from the sale of cattle. | ||
|
This answer is at variance with the one above where the respondent indicated that he owns/holds no cattle. Having drawn the respondent's attention to the two answers, the enumerator found that the respondent had sold all his cattle before the time of the survey, to purchase fertiliser, food and other household needs. This means that the two answers were consistent with the respondent's circumstances at each point in time. | |||
Cross-check questions can be double-checked during data entry to determine whether the enumerator has been able to detect inconsistencies in the data obtained, thereby also checking on his/her diligence in filling out the questionnaire.
Question types and layout. Whether the researcher obtains the desired information will depend on the type of question he/she asks. Questions can be formulated to obtain facts or opinions.
Factual questions can be 'closed' or 'open-ended' (CIMMYT, 1985, p. 64). A closed question gives the respondent no other options to answer than those specified in the questionnaire. An open-ended question gives the respondent the option to say what he/she wishes in its response. Opinion questions are always open-ended.
Each type of question has its place in the survey. When specific information is needed about the household (e.g. number of adult males, number of cattle owned/held, types of other assets owned) or when we wish to find out if a particular practice (e.g. ploughing and weeding) is widely used and how much time is spent on it, then the appropriate type of question to use is the factual question. When, however, the aim is to elicit community views about particular practices/beliefs/cultural obligations etc., then opinion questions should be used.
There are advantages and disadvantages with each type of question. With opinion questions, the danger is that the respondent will give an answer which he/she thinks the researcher (or the enumerator) wants to hear. Therefore, leading questions such as, Do you think the government should provide a dip-tank service for this area?, should be avoided. Factual questions lack flexibility, but the answers to them are easy to analyse.
The type of question asked will influence its layout. There are essentially four layouts possible (see examples on the next page):
· single-option, closed
· multiple-choice, closed
· tabular, closed, and
· open-ended.
Wording. Each question should be worded clearly so that there is no doubt about its meaning. The aim should always be to:
· tap the precise information required· enhance recall, and
· minimise 'enumerator effects' by encouraging standardised responses (Grandin and Solomon Bekure, 1983).
Proper wording therefore implies the use of correct terminology and the avoidance of vague terms, Jargon and multiple-issue questions.
|
Examples: |
|||
|
a) Single-option, closed question layout |
|||
|
|
(Enter code number) |
||
|
Do you own/hold goats? |
|||
|
(1. yes; 2. no) |
|||
|
b) Multiple-choice, closed question layout |
|||
|
|
(Enter code number) |
||
|
Q: How do you plough your fields? |
|||
|
A: By using |
|||
|
1. your own tractor |
|||
|
2. a hired tractor |
|||
|
3. your own oxen |
|||
|
4. hired oxen |
|||
|
5. your own donkeys |
|||
|
6. hired donkeys |
|||
|
c) Tabular, closed question layout |
|||
|
Answer the following questions about land preparation: |
|||
|
Operation |
|
Is animal or tractor owned or rented? |
|
|
Performed? |
When? |
Method used? |
(owned/rented) |
|
(yes/no) |
(month) |
(animal/tractor) |
|
|
Ploughing |
|||
|
Harrowing |
|||
|
Seeding |
|||
|
Source: Adapted from Byerlee and Collinson (1980, p. 35). |
|||
|
d) Open-ended question layout |
|||
|
Why do you keep cattle?................................................................................................................................ |
|||
Correct terminology. It is advisable to translate the questionnaire into the local language, particularly when the enumerator's knowledge of English (or French) is limited. The translation should be tested with several enumerators to ensure that the interpretation is correct. Translations by enumerators in the field are likely to result in errors of interpretation (CIMMYT, 1985, p. 68, gives examples of some of the errors involved).
Vague terms. Words such as 'often', 'frequently' and 'always' may be misinterpreted and should be avoided. Words which may have several different meanings in the local language should not be used either.
For instance, the question 'How often did you dip your cattle last year?' would be more specific if worded as 'How many times did you dip your cattle from May to December last year?'
Jargon. The use of technical agricultural terms such as 'stocking rate,, 'carrying capacity and 'livestock unit' can cause confusion and result in misinterpretation by the respondents. Every-day words which convey the same meaning are therefore preferable, as are local terms for diseases and units of measurement. Abbreviations such as FMD (for foot-and-mouth disease) should be avoided.
Multiple-issue questions. Questions such as, Do you own/hold cattle and smallstock? are confusing and should be broken down into questions dealing with one issue only (e.g. Do you own/hold cattle? and Do you own/hold smallstock?).
In surveys based on questionnaires, enumerators are normally used to collect the data. Therefore, a properly designed survey form would not serve its purpose, if the enumerators are not carefully chosen, properly trained and adequately supervised.
Selection and recruitment
Enumerators should have a good educational background to enable them understand the objectives and principles of data collection, communicate these to the interviewees in their own language, and perform basic arithmetic calculations and other functions as required. Fluency in the local language is a must, but if the research team does not speak that language, enumerators should also tee bilingual. In addition, they should be familiar with local terms, customs and farming practices, and be open-minded, tactful and flexible.
Extension officers, school teachers and other similarly qualified people resident in the study area should be used to conduct once-off interviews in their spare time. They are normally very effective because while they are familiar with the people and their customs, they are usually also sympathetic to efforts aimed at obtaining information about the community. More often, however, only enumerators from less educated groups in the population are available.
Training
Irrespective of the background of the enumerator, sufficient time should be given to training each time a new questionnaire is used. Training on the use of the interviewing technique selected for the survey, and its merits and demerits, should be emphasised (CIMMYT, 1985).
Orientation. Enumerators should be acquainted with the purposes and principles of data collection and be given a proper background on the target group (farming practices, political and cultural aspects etc.). The orientation sessions with enumerators should include discussions about:
- the timing of operations- functional support (food, clothing, accommodation, materials, salaries/wages, transport)
- the number of households in the sample and their location
- the division of responsibilities
- who should interviewed (e.g. household head) and when during the day, and
- the questionnaire itself (its content, layout, cross-checks, consistency of interpretation and interviewing technique).
Interviewing technique. Enumerators should be made aware that the method of interview they use can 'make or break' the survey. Poor technique can mean that the respondent loses interest and becomes uncooperative. The essential principles of a good method are:
· Stress confidentiality of informationRespondents should be assured that the information given will be treated as confidential, particularly in respect of livestock ownership. If a respondent refuses to answer a question, the interviewer should record the fact without further debate.
· Cooperate with the interviewees
The time, place, length and pace of the interview should suit the respondent. An interview should be completed in less than 1 1/2 hours, and the respondent should always be thanked for participating.
· Adhere to the contest of the questionnaire
The interviewer should keep the respondent 'on track' and confine his questioning to the survey. He/she should also be alert to inconsistencies in the answers given and avoid suggestive questioning. At the end of the interview, survey forms should be checked to ensure that all questions have been properly answered.
Often it is useful to give a new enumerator an opportunity to practice using the questionnaire, either with a member of the research team or with other, are experienced enumerators.
Supervision
The need to supervise enumerators cannot be overemphasised. Supervision of enumerators will involve checks in the field and in the office.
Field checks. Periodic checks in the field are recommended to ensure that the required data are indeed being collected (instances when enumerators fill questionnaires without ever having visited the interviewees are, unfortunately, common), and that the collection is done properly. A check early in the survey will often prevent mistakes being made throughout the survey. This should be followed by random visits during the survey period to check the data, ensure adequate support for the data collection and prevent enumerators from filling in forms with fictitious information.6
6 Enumerators may skip particular questions either because of embarrassment or because they assume that the answer is self evident and requires no further confirmation.
Office checks. When completed forms are returned, they should be checked for inconsistencies and missing answers, and then re-checked during data entry on the computer.
All questionnaires should be pre-tested with a small number of non-random y selected respondents. The aims of pre-testing are to:
· isolate inconsistencies and sensitive issues in the questionnaire· determine whether each question is properly worded and understood by the enumerator as well as the respondent. Enumerators' suggestions for re-wording should be included in the revision
· decide whether all questions are relevant or whether additional ones may be needed
· test the layout of the questionnaire and the coding system, and
· determine expected duration of each interview.
Pre-testing can have a useful training function, though some of its objectives may not be fulfilled if novice enumerators are used (CIMMYT, 1985, p. 85).
There are two potential types of error in sampling: sample and non-sample errors.
Sample errors
Sampling techniques are used when complete enumeration of a population is considered impractical (because of cost, manpower and/or logistic of reasons, for instance). Sampling produces errors in estimation because of chance or the sampling method used. The magnitude of sampling errors is normally unknown but can be estimated from the sample data.
Non-sample errors
Non-sample errors occur because of incomplete or poor responses, enumerator error or bias and mistakes made during data processing. They can thus occur both when sampling is applied or when complete enumeration is used. Sources of non-sample error common y encountered during the diagnostic stage of livestock systems research are discussed in detail below (see also CIMMYT, 1985, p. 92).
Respondent error or bias. Such errors will occur if the information given by respondents is incorrect or when questions are asked which cannot be answered. There are six potential sources of respondent error:
· Refusal of selected respondents to participate in the surveyThis can result in missing data. For practical purposes, cases of refused participation are treated as 'missing cases'. To compensate for such cases, a larger sample than necessary may be selected (known as oversampling). There will always be some refusals to participate in a survey, but their number can be considerably reduced through preliminary discussions with farmers/pastoralists and community leaders to identify a sample of willing and representative respondents.
· Refusal to answer particular questions
This may happen when questions are asked about household income (Module 4), animal mortality (Module 5), livestock ownership/holdings and the disposal or acquisition of livestock (Module 9).
· Deliberate provision of misleading information
Grandin (1983, p. 282) reported that the Massai in Kenya dislike talking about livestock acquisition, and because of this, tend to report giving more than they receive (for instance, exchanges of adult steers for young females tend to be understated because such exchanges, though common, are regarded as 'begging'). Deliberate misrepresentation of stock numbers is common in most African societies, and is exacerbated by fears of taxation.
· Misinterpretation or misunderstanding of questions
Errors due to misinterpretation or misunderstanding of questions can be significantly reduced by using appropriate language in the questionnaires, by choosing enumerators familiar with local terminology and, last but not the least, by periodically checking on the progress of the survey.
· Recall problems
These problems are discussed in Part B above (pages 44-46) and in various of the following modules.
· Inability to answer questions accurately
This may occur when questions are asked about measurements (e.g. distance walked when herding) or when the measurement/time standards used by the enumerator differ from those of the respondents. Errors can also arise when the wrong respondent is chosen (for instance, the household head may know little about an operation such as milking which is normally done by women).
· Respondent fatigue
Lengthy interviews lead to loss of concentration on the part of the respondent, which affects the accuracy of the answers given. Respondent fatigue is also common when surveys are complex or when they are conducted over several months (e.g. multiple-visit, multiple-subject surveys; see Part B. p. 46).
Enumerator error or bias. This type of error is commonly due to:
· Deliberate laziness or dishonesty and boredom (in multiple-visit surveys)· Misunderstanding/misinterpretation of questions and answers
Errors of this type can tee avoided by selecting enumerators proficient in the language spoken by the interviewees and through practice in the use of questionnaires and relevant interviewing techniques.
· Incorrect measurements or use of incorrect conversion standards
Measurement errors may occur if the enumerators are not familiar with the measurements used or the conversions applied. They can be prevented by proper training of enumerators before they are involved in measurement.
· Mistakes in data entry
Mistakes can be made when filling in questionnaires or entering data into the computer if the enumerators and data coders are inexperienced or unfamiliar with the questionnaire. Data entry can be simplified by using properly designed questionnaires. Regular checking during the survey of responses and adequate practice in the use of questionnaires are also likely to reduce mistakes in data entry.
Other sources of non-sample error. These include incomplete coverage or listing of sample units, loss of questionnaires and data, incomplete data entry and incorrect data conversions at the office after correct information had been collected in the field.
· Incomplete coverage
Obtaining a complete listing of sample units (e.g. all households in the target group) is a major practical difficulty in livestock systems research, particularly when no supplementary information is available (e.g. census and extension lists) or when populations are dispersed, as in pastoral communities. Specific sampling methods (e.g. cluster sampling) can overcome such problems.
If available, census lists should always be checked for reliability, as they may be out of date. Lists made by extension officers are likely to reflect their biases and to be incomplete. The researcher must weigh the time and cost involved in obtaining an accurate listing against possible inaccuracies resulting from the use of easily available, but less accurate, lists (CIMMYT, 1985, p. 76).
· Incomplete computer data entry
This type of error can be checked by listing all computer entries and comparing them with the original data entries in the questionnaires or record sheets.
It is not possible, in this manual, to explain the theory and practice of sampling adequately to readers not acquainted with it. Such readers should consult one of the standard textbooks such as Cochran (1977), Yates (1981) and Snedecor and Cochran (1984). What follows here is an aid to the memory of those who already have some acquaintance with sampling.
Sampling methods are used when complete enumeration is impractical for financial, manpower or logistic reasons. Sampling is necessary because different units within populations (e.g. households, cattle, smallstock) vary in their individual characteristics. Given this variation, the samples selected for examination must be representative of the entire population.
Because the number of cases studied is less, sampling permits a more detailed study of particular population characteristics than would normally be possible in a census. In addition, non-sample errors tend to be less because sampling permits greater attention to detail during data collection and analysis.
Estimates from samples are subject to sample error, the extent of which can be approximated by statistical formulae. When probability methods of sampling are used (see below) 'confidence intervals' can be established for any given estimate to indicate the reliability of the figure obtained. (See Module 11 for further information on confidence intervals.)
The sampling method used in the field will be influenced by two main concerns - sample selection and estimation.
Sample selection. This involves the manner in which sample units are chosen for study and their definition. In livestock systems research, the unit most commonly chosen is the household, but individuals within a household or individual animals may also be identified as sample units.
Estimation. This involves the manner in which inferences are drawn about the population as a whole and the precision/accuracy of these inferences or estimates.
The objective should always be to select that method which produces results of acceptable precision at the lowest possible cost and in the shortest possible time. This implies an ability to evaluate the level of precision required before diagnostic research begins.
The sampling methods most commonly used in livestock systems research fall into two main categories - the probability and non-probability methods.
Probability methods. These methods make it possible to draw inferences about the population which can be statistically evaluated. Probability methods are used if the probability (or chance) of selection of each unit (e.g. household) in the sample is known.
Non-probability methods. When the probability of selection of each unit is unknown (because complete population lists are not available), 'non-probability samples' are chosen (CIMMYT, 1985). With these methods, inferences about the population can be drawn, but they cannot be statistically evaluated.
Non-probability methods are commonly used in livestock systems research when rapid appraisals of the target group are needed.
Probability sampling methods
Four main methods of probability sampling are used in livestock systems research:7
· simple random
· stratified
· systematic, and
· multi-stage.7 Details about the statistical formulae applicable to each method are discussed in Cochran (1977) and Yates (1981).
Simple random sampling. With this technique, each unit in the population has an equal chance of being selected.
Sample units are 'drawn' at random (one at a time), usually from random number tables. Particular variables (e.g. household size, livestock holdings, livestock sales) are then measured for each sample unit to make inferences about the whole population. For each characteristic, variability within the sample is measured by the standard deviation. Methods which yield unbiased estimates are subsequently used to estimate population statistics (e.g. the total number of cattle within an area) together with their confidence limits (which are calculated using standard errors).
In general, the larger the sample, the smaller the standard error and the greater the confidence in the estimate obtained. The size of the sample will therefore determine the precision of each estimate made. Sample size will, in turn, be determined by the need for precision as well as by financial, manpower and logistic considerations.
Advantages. Simple random sampling is very easy to implement. It requires no prior knowledge of population characteristics with respect to each variable measured and is most appropriate when all that is known about the population is the mere existence of each individual unit. It is also appropriate when the population concerned is relatively concentrated in a single area.
Disadvantages. Simple random sampling is dependent on the availability of a complete population list (e.g. of all households in a target area). When additional information is available (e.g. on the dispersion of livestock holdings within the population), simple random sampling tends to be less precise than other methods (such as stratified sampling). In addition, it can be costly if sampled units are spread over a large geographic area.
Stratified sampling. With this method, the population is broken into groups or strata on the basis of one or more characteristics. In livestock systems research, for instance, strata are formed using wealth, livestock holdings, household size or other characteristics thought to influence production performance. Secondary data sources and/or rapid survey techniques (such as wealth ranking) may be used to identify each different stratum in the population.8
8 The appendix to Module 1 shows low Maasai pastoralists in Kenya were stratified on the basis of wealth ranking criteria by ILCA scientists.
Strata should be defined in such a way that the units within each stratum are homogeneous, i.e. they differ little in respect of the variable being considered. In contrast, differences between strata should be wide.9 Standard errors in stratified sampling tend to be less than in simple random sampling of the same population and the estimates are, therefore, more precise.
9 In stratified sampling, only the within-stratum variation is considered, and not the variability between strata, when the standard errors of population estimates are calculated.
The method treats each stratum as a separate 'population'. Sample units are selected within each stratum by either simple random sampling or systematic sampling (see below). The proportion of units selected from within each stratum will be influenced by:
- the size of each stratum, and
- the degree of homogeneity within each stratum.
Other things being equal, the proportion of units selected from within each stratum should generally be greater for the less homogeneous strata and for those more important. However, 'importance of the stratum' is not the same thing as size in terms of numbers of members.
For instance, a few big milk producers may account for a much higher proportion of milk production than hundreds of small farmers. Therefore, to estimate milk production more precisely, it would be correct to sample a much higher proportion of the big farmers' stratum than of the 'small farmers' stratum.
The various methods available to select samples from different strata are discussed in detail by Cochran (1977), Yates (1981) and others.
Advantages. Stratified sampling is a relatively simple method ensuring that each group in the population is adequately represented. Compared with simple random sampling, extreme cases are less likely to be missed because within-stratum variation is minimised and the estimates obtained for the population as a whole tend to be more precise, as well.
Disadvantage. The method is dependent on the availability of reliable supplementary information in order to break the population into homogeneous strata.
Systematic sampling. In systematic sampling, every kth unit in the sample list is selected for survey. The size of 'k' (say 10) is known as the sampling interval and this, in turn, determines the number of units that will be selected from the list. A number between 1 and 'k' is chosen at random as the starting point for selection (known as the 'random start').
|
Example: Households were grouped into strata and assigned numbers to allow systematic sampling of units from within each stratum. In one stratum there were 35 households; unit 3 was chosen as the random starting point, and every 6th unit (shown in square brackets) from that point was selected for the survey. |
|||||||
|
Assigned household number in stratum |
1 |
2 |
[3] |
4 |
5 |
6 |
7 |
|
8 |
[9] |
10 |
11 |
12 |
13 |
14 |
|
|
[15] |
16 |
17 |
18 |
19 |
20 |
[21] |
|
|
22 |
23 |
24 |
25 |
26 |
[27] |
28 |
|
|
29 |
30 |
31 |
32 |
[33] |
34 |
35 |
|
Advantage. Systematic sampling allows speedy selection of sample units in a simple way. It is therefore appropriate for large-scale sampling operations in which unskilled personnel are used.
Disadvantages. If there is any repetitive pattern in the listing of sample units and the units are, therefore, arranged in non-random order, systematic sampling can lead to biases. However, when a random order can be guaranteed, the method will be at least as efficient as simple random sampling.
Multi-stage sampling. The methods discussed above are all 'single-stage' sampling methods involving only one drawing of sample units before a survey can commence. When two or more stages are involved, samples are selected by a "multi-stage' process.
Cluster sampling is an example of a multi-stage method commonly used in systems research. It may involve two or more stages before units are finally chosen for survey. If a two-stage cluster sample were to be selected, the following procedure would be adopted:
Step 1. The population is grouped into 'clusters' using existing geographical, political or cultural characteristics (e.g. households within a chiefdom may be grouped into recognised village units). To be able to do this, a list of the main groups concerned (e.g. a list of all villages in the chiefdom) must first be obtained.10
10 When existing divisions are used to cluster population units, the grouping is said to be 'arbitrary' - i.e. groupings are made as they actually occur. When units are grouped deliberately into clusters for sampling, the grouping is said to be 'purposive'. In systems research arbitrary groupings are more common.
Step 2. A sample of clusters is then selected by simple random, stratified systematic or some other appropriate sampling technique.
Step 3. From the sample of cluster units chosen, final units (e.g. households) are selected for survey using an appropriate sampling technique.
Step 4. Data are collected by a survey of the chosen sample units and population estimates are derived by the use of appropriate statistical formulae.
For a three-stage cluster sampling, the procedure would be:
· select two or more chiefdoms in a country (stage 1)
· select sample villages from these chiefdoms (stage 2),
· and select sample households for survey from each selected village (stage 3).
Advantages. Multi-stage sampling is particularly suitable in extensive agricultural systems where households are widely dispersed but grouped into definite political, social or geographical units. With this method, a costly and time-consuming listing of all the households in the total population is not necessary; only in the selected clusters will a complete listing of households be required. The final selection of households will then be confined to relatively few locations, thereby reducing the amount of travel required for the survey and hence the overall cost.
The critical criterion is cost. For a given size of sample, greater precision can normally be achieved by using simple random or stratified sampling techniques. However, when a fixed sum of money is available for a survey, cluster (multi-stage) sampling with a larger overall sample size will give greater precision than the other techniques.
Multi-stage sampling methods offer a wide range of options in choosing the nature, number and size of clusters at each stage of the selection process. The sampling configuration chosen can thus be adapted, within reason, to suit the particular administrative and operational capabilities of the research team.
Disadvantages. One disadvantage is a loss of precision in the estimates obtained. Because the units within a given cluster (e.g. households in a village) tend to have similar characteristics, cluster sampling can lead to biased results if an insufficient number of clusters is chosen.11 Therefore, total sample size in multi-stage sampling must be somewhat larger than in single-stage methods to give results of a given level of accuracy. However, because multi-stage sampling tends to be easier to administer, the selection of larger samples will not normally be a problem.
11 For a given total size of sample, the larger the number of clusters chosen, and hence the fewer second-stage units on average in each, the lower the variance of the estimates made.
The accuracy of the estimates can be improved by deliberately grouping elementary units (e.g. households) into 'similarly sized' clusters, thereby reducing the variability between them.12 When there is already a natural division on the basis of geographical, political or cultural characteristics, such a procedure will, however, mean that some of the advantages of easier contact and administration are lost.
12 In multi-stage sampling, both variability within clusters and between clusters must be taken into account in the estimation of standard errors.
The two non-probability sampling methods often used in livestock systems research are:
Purposive sampling. Purposive sampling is when the researcher selects a sample with a view to obtaining a cross-section of the population. The method relies on the researcher's judgement for the selection of respondents, and results may therefore be biased by the researcher's perceptions of the system or area. Purposive sampling is also called 'judgement sampling'.Quota sampling. This method is a form of stratified sampling, and it is used when the cost or time associated with obtaining a complete listing of sample units is considered unjustified. Quota sampling is particularly recommended when the main groups in a population are known (e.g. as a result of informal surveys or from secondary data sources) but when a full listing of units within each group cannot be obtained.
A quota of respondents is established for each group, and farmers/pastoralists are interviewed to determine which group they belong to, until the quota for each group is filled. Respondents may be selected by simple random or systematic sampling, or the selection may be 'accidental' (i.e. the researcher interviews the people he/she meets by accident). Researchers use their judgement to allocate respondents to different strata. A drawback of quota sampling is that since it is a non-probability method, the estimates obtained with it cannot be tested statistically.
|
An example of a questionnaire layout | ||
|
1. Enumerator |
| |
|
2. Communal area |
| |
|
3. Ward |
| |
|
4. Kraalhead area |
| |
|
5. Farm number |
|
|
|
SECTION 'A': HOUSEHOLD CHARACTERISTICS | ||
|
6. How many persons are there in your household? |
| |
|
How many of these persons are: |
| |
|
7 (a) children under the age of 10? |
| |
|
8. (b) males between 10 and 14 years old? |
| |
|
9. (c) females between 10 and 14 years old? |
| |
|
10. (d) males between 15 and 64 years old? |
| |
|
11. (e) females between 15 and 64 years old? |
| |
|
12. (f) adults older than 65 years? |
| |
|
How many persons in your household: |
| |
|
13. (a) normally attend school? |
| |
|
14. (b) are females older than 15 years of age who normally stay at home? |
| |
|
15. (c) are males older than 15 years of age who normally stay at home? |
| |
|
16. (d) are females older than 15 years of age who are normally absent from home? |
| |
|
17. (e) are males older than 15 years of age who are normally absent from home? |
| |
|
18. (f) are children who do not attend school? |
| |
Byerlee D and Collinson M (eds). 1980. Planning technologies appropriate to farmers: Concepts and procedures. Economics Program, CIMMYT (Centro Internacional de Mejoramiento de Maiz y Trigo), Mexico, Mexico. 71 pp.
CIMMYT. (Centro internacional de Mejoramiento de Maiz y Trigo). 1985. Teaching notes on the diagnostic phase of OFR/FSP; Concepts, principles and procedure. CIMMYT Occasional Paper 14. Eastern African Economics Programme, CIMMYT (International Maize and Wheat Improvement Centre), Nairobi, Kenya. 121 pp.
Cochran W G. 1977. Sampling techniques. Third edition. John Wiley and Sons, New York, USA. 427 pp.
Collinson M P. 1972. Farm management in peasant agriculture: A handbook for rural development planning in Africa Praeger Publishers, New York, USA. 444 pp.
Doran M H. 1982. Communal Area Development Report 2: South Matabeleland. Agricultural and Rural Development Authority, Bulawayo, Zimbabwe. 14 pp.
Gilbert E H. Norman D W and Winch F E. 1980. Farming systems research: A critical appraisal. MSU Rural Development Papers 6. Department of Agricultural Economics, Michigan State University, East Lansing, Michigan, USA. 135 + xiii pp.
Grandin B E. 1983. Livestock transactions data collection. In: Pastoral systems research in sub-Saharan Africa Proceedings of the IDRC/ILCA workshop held at ILCA, Addis Ababa, Ethiopia, 21-24 March 1983. ILCA (International Livestock Centre for Africa), Addis Ababa, Ethiopia. pp. 277-287.
Grandin B E and Solomon Bekure. 1983. Household studies in pastoral systems research. In: Pastoral systems research in sub-Saharan Africa Proceedings of the IDRC/ILCA workshop held at ILCA, Addis Ababa, Ethiopia, 21-24 March 1983. ILCA (International Livestock Centre for Africa), Addis Ababa, Ethiopia. pp. 263-275.
Snedecor G W and Cochran W G. 1984. Méthode statistique. Association de coordination technique agricole, Paris, France. 647 pp.
Solomon Bekure. 1983. Household income and expenditure studies. In: Pastoral systems research in sub-Saharan Africa Proceedings of the IDRC/ILCA workshop held at ILCA, Addis Ababa, Ethiopia, 21-24 March 1983. ILCA (International Livestock Centre for Africa), Addis Ababa, Ethiopia. pp. 289-304.
Yates F. 1981. Sampling methods for censuses and surveys. Fourth edition. Charles Griffin and Co. Ltd, London, UK 458 pp.
![]()
![]()
![]()
{kind=link}