




食物不足发生率
定义
食物不足被定义为个人惯常食物摄入量平均下来不足以提供健康、活跃和正常生活所需的膳食能量。
报告方式
“食物不足发生率”指标(简称PoU)估算人口中处于食物不足状态者所占百分比。国家估计值以三年移动平均值的形式呈现,以解决一些基础参数估计值因缺乏完整、可靠信息而导致的可靠性较低的问题。此类参数包括作为粮农组织每年食物平衡表组成部分之一的食品类商品库存年度变化等。而区域和全球汇总数据则以年度估计值的形式呈现,因为可能出现的估计误差预计相互之间不具关联性,因此将各国数据汇总的做法预计可将其降至可接受水平。
本报告每一期都会根据粮农组织获得的最新数据和信息,对食物不足发生率全系列数值进行修订。由于这一过程通常意味着对食物不足发生率全系列进行回溯性修订,因此建议读者避免比较本报告不同版本中的数据系列,应始终以当前版本为准,包括往年的估计值。
方法
要估算特定人群的食物不足发生率,需要将普通人个体惯常膳食能量摄入水平(以人均每日千卡数为单位)的概率分布建模为参数概率密度函数f(x)。1, 2该指标是指惯常膳食能量摄入(x)低于最低膳食能量需求(MDER)(即适合该人群代表性个体能量需求范围的下限)的累积概率,如以下公式所示:
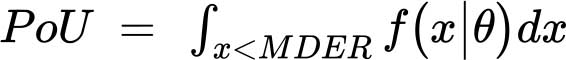
其中θ是描述概率密度函数的参数向量。在实际计算中,假定分布是对数正态分布,因此全面描述只需两个参数:平均膳食能量消费(DEC)及其变异系数(CV)。
数据来源
采用了不同数据来源来估算模型的不同参数。
最低膳食能量需求(MDER)
以每千克体重基础代谢率的标准需求,乘以该性别/年龄组健康个体在特定身高时应具有的理想体重,然后乘以体力活动水平系数(PAL),以期反映体力活动因素,最终确定个体的能量需求。bb由于对同一性别和年龄组中的健康活跃个体而言,健康的体重指数(BMI)和正常的体力活动水平(PAL)都可能存在差异,因此每个性别和年龄组的能量需求都有一个区间范围。计算人群中普通个体的最低膳食能量需求(MDER)(食物不足发生率公式中采用的参数)时,采用每个性别和年龄组在人口中所占比例作为权重,计算出该性别和年龄组能量需求区间下限的加权平均值。与此类似,估算平均膳食能量需求(ADER)(用于估算下文所述变异系数CV的一个组成部分)时,采用体力活动水平类别为“活跃或中度活跃生活方式”的平均值。3
对世界上大多数国家而言,计算最低膳食能量需求所需的按性别和年龄分类的年度人口结构信息,可参考联合国经济和社会事务部编写的《世界人口展望》,该报告每两年修订一次。本期《世界粮食安全和营养状况》采用的是《世界人口展望》2024年修订版。4
各国不同性别和年龄组的身高中位数信息来自最近的人口与健康调查(DHS)或其他收集儿童和成人人体测量数据的调查。即使这些调查的年份与估算食物不足发生率时的年份不同,但几年时间里身高中位数的小幅变化对最低膳食能量需求以及食物不足发生率估计值的影响可忽略不计。
膳食能量消费(DEC)
理想情况下,膳食能量消费可依据全国代表性家庭调查(如生活水平测量研究[LSMS]或家庭消费和支出调查)收集到的食品消费数据估算得出。然而,仅少数国家会每年开展此类调查。因此,粮农组织在估算用于全球监测的食物不足发生率时,所采用的膳食能量消费数值源自粮农组织为世界上多数国家编制的食物平衡表中的膳食能量供给(DES)数据。5
自上期报告发布以来,粮农组织统计数据库中所有国家的食物平衡表系列数值已更新至2022年。此外,在本报告截稿时,有72个国家的食物平衡表系列数字已更新至2023年,之所以选取这些国家进行优先更新,是因为它们对全球食物不足人数的贡献最大。相关国家包括:阿富汗、阿尔巴尼亚、安哥拉、阿根廷、孟加拉国、贝宁、多民族玻利维亚国、巴西、布基纳法索、喀麦隆、中非共和国、乍得、哥伦比亚、刚果、古巴、科特迪瓦、朝鲜民主主义人民共和国、刚果民主共和国、厄瓜多尔、埃及、埃塞俄比亚、加纳、危地马拉、几内亚、几内亚比绍、海地、洪都拉斯、印度、印度尼西亚、伊朗伊斯兰共和国、伊拉克、日本、约旦、肯尼亚、莱索托、利比里亚、利比亚、马达加斯加、马拉维、马来西亚、马里、摩洛哥、莫桑比克、缅甸、尼泊尔、尼加拉瓜、尼日尔、尼日利亚、巴基斯坦、巴布亚新几内亚、秘鲁、菲律宾、卢旺达、沙特阿拉伯、塞内加尔、塞拉利昂、索马里、南非、南苏丹、斯里兰卡、苏丹、阿拉伯叙利亚共和国、泰国、多哥、突尼斯、乌干达、乌克兰、坦桑尼亚联合共和国、越南、也门、赞比亚、津巴布韦。
对2023年(除上述国家之外其他国家)和2024年(所有国家)人均膳食能量供给的快报预测基于粮农组织开展的短缺市场展望结果,用于世界粮食形势门户网站,6同时用于计算每个国家2023年和2024年的膳食能量消费值。
浪费系数
本期报告更新了用于计算膳食能量消费的浪费系数,具体方法是从各国膳食能量供给中减去浪费百分比。流通环节的食物浪费百分比根据粮农组织统计数据库中提供的食物平衡表数据估算。
每个食物组别的卡路里浪费数量根据粮农组织《全球粮食损失和粮食浪费》7中给出的百分比计算和汇总而来,仅谷物例外,所有区域的谷物浪费系数均以2%计算。最后,卡路里浪费总量以在每年每个国家卡路里总量中所占百分比表示。数据已更新至2022年。2023年和2024年也同样采用了2022年的数值。
变异系数(CV)
人口惯常膳食能量消费(DEC)的变异系数是两项数值的几何平均值,这两项分别为CV|y和CV|r :
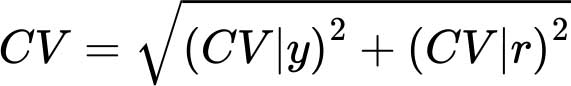
第一项(CV|y)指属于不同社会人口分层的家庭之间人均消费的差异,因此被称为“收入变异系数”,而第二项(CV|r)则代表由于性别、年龄、体重和体力活动水平上的差异造成的同一家庭中不同个体之间的差异。由于这些因素同时也是决定能量需求的因素,因此第二项被称为“能量需求变异系数”。
收入变异系数(CV|y)
如具备可靠的全国代表性家庭调查数据,就可以直接估算收入变异系数CV|y。自上一期报告发布以来,为更新CV|y,对以下14个国家的25项最新调查数据进行了处理:贝宁(2022年)、布基纳法索(2022年)、柬埔寨(2021年和2023年)、格鲁吉亚 (2022年和2023年)、几内亚比绍(2022年)、印度(2022年和2024年)、约旦(2022年)、哈萨克斯坦(2021年和2023年)、蒙古(2022年和2023年)、缅甸(2015年)、秘鲁(2023年)、索马里(2022年)、泰国(2016年、2017年、2018年、2019年、2020年、2021年和2023年)、多哥(2022年)。因此,在国家调查数据基础上估算CV|y时,共参考了71个国家的169项调查。
如不具备合适的调查数据,就采用粮农组织2014年以来收集的粮食不安全体验分级表FIES数据,根据观察到的重度粮食不安全趋势,预测2017年(或之后最近一次粮食消费调查年份)至2024年的CV|y变化。预测所依据的假设是,通过FIES衡量的重度粮食不安全程度所观察到的变化可能能反映出食物不足发生率PoU的同等变化。如果PoU的这种隐含变化不能完全用平均食物供给的供给侧影响来解释,那么就可以坚定地认为这些变化是由可能同时发生但未观察到的CV|y变化所造成。对PoU历史估计数据的分析表明,平均来看,在控制了DEC、MDER和CV|r的差异后,CV|y的差异就能解释不同时段和不同地区之间PoU差异的约三分之一。基于此,对每个具备FIES数据的国家,2017年或此后最近一次调查日期以来可能发生的CV|y变化,都可以被估算成重度粮食不安全发生率每观察到一个百分点的变化,就会使PoU产生三分之一个百分点的变化。对于所有其他国家,由于缺乏任何支撑证据,CV|y沿用最后一次估计值不变。与前四期报告一样,2020年、2021年、2022年、2023年和2024年的CV|y快报预测都需要做特殊处理,以便考虑到2019冠状病毒病疫情的影响(见第2章补充材料)。
能量需求变异系数(CV|r)
能量需求变异系数(CV|r)表示健康人群中一个有代表性的假定普通个体膳食能量需求分布差异,等于在该人群营养需求得到完全满足的情况下每个假定普通个体的膳食能量摄入分布的CV|y。为便于估算,我们假设这个假定普通个体的膳食能量需求为正态分布,其标准差(SD)可通过已知任意两个百分位数来估算。我们采用上文提及的MDER和ADER来粗略估算第一个和第五十个百分位数,8, 9随后通过MDER和ADER之间差值的逆累积标准正态分布推导得出CV|r值。
挑战和局限性
虽然从正规意义上讲,食物不足与否仅指个体状态,但由于可用数据均为大规模采集,很难准确识别特定人群中哪些个体实际处于食物不足状态。通过上文所述统计模型,只能针对具有足够代表性样本的一个人群或一组个体计算此项指标。因此,食物不足发生率只能估算为处于食物不足状态的个体占某个人群的百分比,但无法进一步细分到个体。
由于推导的盖然性以及模型中每项参数推算的不确定性,食物不足发生率估计值通常不够精准。虽然无法精确计算食物不足发生率估计值的误差区间,但多数情况下预计会超过5%。因此,粮农组织认为食物不足发生率估计值低于2.5%的数据不够可靠,不予报告。
需要注意的是,2020年至2024年食物不足发生率点估计值区间的上下限并不是统计学意义上的置信区间,而是用于预测CV|y值的不同情景、2020年至2024年浪费系数相关不确定性区间以及2023年和2024年DES快报预测相关不确定性区间(见第2章补充材料)。
推荐阅读
Cafiero, C. 2014. Advances in hunger measurement: traditional FAO methods and recent innovations. FAO Statistics Division Working Paper, No. 14–04. Rome, FAO. https://openknowledge.fao.org/handle/20.500.14283/i4060e
FAO. 1996. Methodology for assessing food inadequacy in developing countries. In: The Sixth World Food Survey, pp. 114–143. Rome. https://www.fao.org/4/w0931e/w0931e16.pdf
FAO. 2003. Summary of proceedings: Measurement and assessment of food deprivation and undernutrition. International Scientific Symposium, 26–28 June 2002, Rome. https://www.fao.org/4/y4250e/y4250e00.pdf
FAO. 2025. Measuring hunger, food security and food consumption. In: FAO. [Cited 25 June 2025]. https://www.fao.org/measuring-hunger/en
Naiken, L. 2002. Keynote paper: FAO methodology for estimating the prevalence of undernourishment. Rome, FAO. https://www.fao.org/4/y4249e/y4249e06.htm
Wanner, N., Cafiero, C., Troubat, N. & Conforti, P. 2014. Refinements to the FAO methodology for estimating the prevalence of undernourishment indicator. FAO Statistics Division Working Paper, No. 14–05. Rome, FAO. https://openknowledge.fao.org/handle/20.500.14283/i4046e
以粮食不安全体验分级表衡量的粮食不安全发生率
定义
以此项指标衡量的粮食不安全指个人或家庭层面由于缺乏金钱或其他资源而导致食物获取受限。粮食不安全的严重程度通过粮食不安全体验分级表调查模块(FIES-SM)收集的数据加以衡量。该模块包括八个问题,让受访者自我报告通常与食物获取受限相关的状况和体验。为了便于对可持续发展目标进行年度监测,这些问题针对调查前12个月的情况。
利用基于Rasch模型的复杂统计技术,FIES SM调查收集到的信息先要经过内部一致性验证,并量化为从低到高的严重程度分级。全国代表性调查中接受调查的个人或家庭根据他们对问题的回答结果,按概率被归入以下三个类别之一:1)粮食安全或仅轻微不安全;2)中度粮食不安全;3)重度粮食不安全。三个类别按两个全球设定的阈值来区分。粮农组织根据2014年至2016年三年里收集到的FIES数据,创建了粮食不安全体验参考分级表,作为衡量粮食不安全体验的全球标准,并据此设定区分严重程度的两个参考阈值。
将中度粮食不安全和重度粮食不安全两个类别相加,就可得出可持续发展目标指标2.1.2的相关情况。若仅考虑重度粮食不安全单个类别,则可计算出另一项指标(FIsev)。
报告方式
在本报告中,粮农组织提供了两种不同严重程度的粮食不安全估计数据:中度或重度粮食不安全(FImod+sev)以及重度粮食不安全(FIsev)。针对每种严重程度都报告两个估计数:
- 总人口中所在家庭至少一名成人处于粮食不安全状态的个体比例(百分比);
- 总人口中所在家庭至少一名成人处于粮食不安全状态的估计个体人数。
数据来源
自2014年以来,由八个问题组成的FIES-SM调查已应用于盖洛普©世界民意调查所涵盖的140多个国家的全球代表性成人人口(15岁或以上)样本,覆盖全世界90%以上的人口。2024年,通过电话和面对面两种方式开展了访谈。而在2020年疫情期间因面对面访谈存在社区传播的风险而采用了电话访谈方式的一些国家,仍沿用了电话访谈的方式。
盖洛普©世界民意调查传统上在北美、西欧、亚洲部分地区以及海湾阿拉伯国家合作委员会成员国采用电话方式开展调查。在中欧和东欧、拉丁美洲大部分地区以及亚洲、近东、非洲几乎所有地区,盖洛普©世界民意调查通过区域框架设计开展面对面访谈。
在多数国家,样本包括大约1000名个体。一些国家的样本量较大,如中国大陆(3500人)、印度(3000人)、俄罗斯联邦(2000人)。2024年未在中国大陆收集数据。
利用官方调查数据计算了82个国家至少一年的粮食不安全发生率估计数,覆盖了世界人口的三分之一以上,具体方法是采用粮农组织的统计模型,按照统一的全球参考标准,对各国结果开展内部验证和调整。完成验证后,这些数据就可为国家系列数据提供参考或在此基础上更新国家系列数据(见下文)。如一个国家的人口在区域总人口中所占比例较高,就可能需要对区域和次区域系列数据进行修订或回溯修订。因此,应避免对不同年份报告中的估计数据进行比较,而应以当前版本为准。
本期报告采用了以下82个国家和领土的官方调查数据:阿富汗、安哥拉、安提瓜和巴布达、亚美尼亚、白俄罗斯、伯利兹、贝宁、博茨瓦纳、巴西、布基纳法索、布隆迪、佛得角、喀麦隆、加拿大、中非共和国、乍得、智利、哥伦比亚、哥斯达黎加、科特迪瓦、塞浦路斯、多米尼加共和国、厄瓜多尔、斯威士兰、斐济、加纳、希腊、格林纳达、几内亚比绍、圭亚那、洪都拉斯、印度尼西亚、以色列、意大利、哈萨克斯坦、肯尼亚、基里巴斯、吉尔吉斯斯坦、莱索托、马拉维、马里、毛里求斯、墨西哥、蒙古、莫桑比克、纳米比亚、瑙鲁、尼日尔、尼日利亚、巴基斯坦、帕劳、巴勒斯坦、巴布亚新几内亚、帕劳、巴拉圭、菲律宾、大韩民国、俄罗斯联邦、圣基兹和尼维斯、圣卢西亚、圣文森特和格林纳丁斯、萨摩亚、塞内加尔、塞舌尔、塞拉利昂、南非、南苏丹、斯里兰卡、苏丹、泰国、东帝汶、多哥、汤加、特立尼达和多巴哥、乌干达、阿拉伯联合酋长国、坦桑尼亚联合共和国、美利坚合众国、乌拉圭、瓦努阿图、越南、也门、赞比亚。如果这些国家某些年份具备国家数据,则采用这些数据。如某些年份没有国家数据,则采用以下方法处理:
- 若可获得不止一年的国家数据,则通过线性插值法补上缺失年份的数据。
- 如仅可获得一年的数据,则采用以下方法处理缺失年份:
- –若认为与国家调查具有可比性,则采用粮农组织数据作为参考;
- –若国家数据不具有可比性,则采用粮农组织数据呈现的趋势进行估算;
- –若没有其他可靠、及时的信息,则采用次区域趋势进行估算;
- –若次区域无法计算或其他调查或次区域的趋势不适用于特定国家的具体情况(考虑到该趋势的实证支撑,如贫困、极端贫困、就业和食物通胀等变化),则认为与国家调查水平一致;此条同样适用于粮食不安全发生率极低的国家(重度粮食不安全发生率低于3%)或极高的国家(中度或重度粮食不安全发生率高于85%)。
由于调查来源具有异质性且粮农组织一些调查的样本量较小,新数据偶尔会导致上一个年份与下一个年份之间出现数据大幅度增加或减少的情况。这种情况下,标准做法是寻找关于该国的外部信息(数据和/或报告,可通过与粮农组织国家或区域官员等国家专家磋商获得),以探究是否发生了重大冲击或干预。若趋势可通过实证得到支持,但看起来仍幅度过大,可采用该趋势但对其进行平滑处理(如采用三年平均值)。否则可采用与缺失年份相同的办法(即保持水平不变或采用次区域趋势)。2024年未在中国大陆收集FIES数据,因此趋势保持不变。
方法
数据经过验证后,采用Rasch模型构建粮食不安全严重程度分级表。模型假设受调者i对问题j给出肯定回答的概率是受调者在严重程度分级表上的位置ai与该项的位置bj之间距离的逻辑函数。
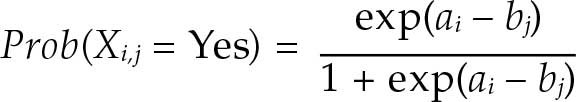
通过将Rasch模型应用于粮食不安全体验分级数据,就可估算出每个受调者i在每种粮食不安全严重程度L(中度或重度,或仅重度)上的跨国可比概率(pi,L),其中0 < pi,L < 1。
在每种严重程度(FIL)上,人群的粮食不安全发生率是样本中所有受调者(i)粮食不安全概率的加权总和:
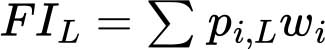
其中wi是后分层抽样权重,表示样本中每条记录所代表的个体或家庭在全国人口中所占比例。
由于盖洛普©世界民意调查仅对15岁或以上个体进行抽样,因此直接利用这些数据得出的发生率估计值仅适用于15岁及以上人群。要得出人口中(所有年龄组)个体的发生率和人数,就必须估算至少一名成人处于粮食不安全状态的家庭中个体的人数。这涉及到一个多步骤程序,详情参见《估算世界各地成年人粮食不安全发生率的方法》附件1B(见下文“推荐阅读”)。
中度或重度粮食不安全以及重度粮食不安全的区域和全球汇总FIL,r计算公式如下:
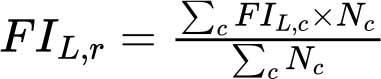
其中r表示区域,FIL,c是该区域中的国家c在严重程度L上的FI值,Nc是相应的人口规模。若一国缺少FIL估计值,则假定FIL等于同一次区域其余国家估计值的人口加权平均值。只有当具备估计值的国家至少占该区域总人口50%以上时,才会生成区域汇总数值。
全球统一的阈值根据FIES全球标准分级表(以2014年至2016年间盖洛普©世界民意调查涵盖的所有国家的结果为基础确立的一套项目参数值)确定,并根据本地分级表转换为对应数值。将每个国家的分级表与FIES全球标准校准的过程,可称为等同化,这样做可以生成具有国际可比性的个体受调者粮食不安全严重程度衡量标准,还可生成具有可比性的国家发生率。
由此产生的一个问题是,当粮食不安全的严重程度被界定为一种潜在特质时,要想评估它就缺少绝对参考标准。Rasch模型能够识别不同项目在分级表上所处的相对位置,称为logit单位,但“零值”为主观设定,通常等同于严重程度的估计平均值。这意味着分级表上的零点每次应用时都会发生变化。为了生成不同时间、不同人群之间可比的数值,就必须确立一个统一分级表作为参考标准,并找到所需公式将衡量结果在不同分级表之间进行换算。就像在不同温度计量法(如摄氏和华氏)之间换算一样,这一过程需要确定几个“锚”点。在FIES衡量方法中,这些锚点是各项目的严重程度,它们在严重程度分级表上的相对位置就是相对应项目在全球参考分级表上的位置。随后需要找到一个公式,将共同项目严重程度的平均值和标准差相互等同,从而将一种分级表上的数值“映射”到另一种分级表上。
挑战和局限性
当粮食不安全发生率估计数以盖洛普©世界民意调查中收集的粮食不安全体验分级表数据为基础,且大多数国家的样本量约为1000人时,置信区间很少高于所测得发生率的20%(即发生率为50%时,误差范围最大为正负5%)。然而,当估算国家发生率时采用更大的样本量,或估计值涉及几个国家的合计数时,置信区间会小很多。为减少每年抽样变化带来的影响,国家层面的估计数以三年平均值表示,由所涉及三年中所有年份的平均值计算而来。
各国官方调查是采用FIES分级表估算粮食不安全发生率时首选的参考来源。然而,这些调查可能不是每年都会进行,且数据可能在几年后才能提供给粮农组织。在没有年度国家调查的情况下,就采用上文介绍的方法(见“数据来源”)来推断各年度的系列数据,这样做可能导致对系列数值进行回溯修订。
推荐阅读
Cafiero, C., Viviani, S. & Nord, M. 2018. Food security measurement in a global context: The food insecurity experience scale. Measurement, 116: 146–152. https://www.sciencedirect.com/science/article/pii/S0263224117307005
FAO. 2016. Methods for estimating comparable rates of food insecurity experienced by adults throughout the world. Rome. https://openknowledge.fao.org/handle/20.500.14283/i4830e
FAO. 2025. Measuring hunger, food security and food consumption. In: FAO. [Cited 25 June 2025]. https://www.fao.org/measuring-hunger/en
健康膳食的成本
定义
健康膳食成本指购买最便宜、当地可得食物的成本,由这些食物构成的膳食结构能满足能量均衡水平为每日2330千卡的参考个体的能量需求和基于食物的膳食指南的要求。
报告方式
该项指标(“健康膳食成本”)是估计一国人民购买健康膳食所需的最便宜、当地可得食品时需要花费的最低成本平均值。为保证跨国可比性,健康膳食成本按照私人消费购买力平价从当地货币单位转换为国际元。因此,报告健康膳食成本指标时采用的单位是人均每日购买力平价美元。
数据来源
健康膳食所需的每组食物中的食品价格来自国际比较项目食品零售价格数据,该项目由世界银行负责协调,根据用当地货币单位标价的一系列国际标准化食品来估算购买力平价。10为了进行跨国比较,我们采用世界银行发展数据组计算得出并公布在世界发展指标数据库中的私人消费购买力平价换算系数,将用当地货币单位标注的价格转换成国际元。11如果某些年份国际比较项目未开展工作,那么更新健康膳食成本时就采用粮农组织发布的食品消费价格指数。12
方法
健康膳食篮的界定方法
由于健康膳食所包含的食品在不同地区各不相同,因此各国都制定了本国的基于食物的膳食指南,推荐符合当地独特文化背景的健康膳食习惯和当地可得食品。然而,并非所有国家都有自己的膳食指南,那些没有膳食指南的国家往往缺乏关于食物数量和所含能量的量化建议。为解决这一数据不足问题,并制定一项健康膳食全球标准来反映世界各地膳食指南的共性,我们选择了世界不同区域近年制定的具有代表性的十份膳食指南。为制定此项国际标准,我们创建了一个健康膳食篮,它基于各国膳食指南中不同食物组别所占比例的平均值,采用了十份膳食指南中推荐的食物组别数量中位数。健康膳食篮要满足每日2330千卡的膳食能量摄入,由六个食物组别中当地可得食物组成,即:淀粉类主粮;蔬菜;水果;动物源性食品;豆类、坚果和籽仁;油和脂肪。具体而言,健康膳食篮应提供1160千卡的淀粉类主粮、110千卡的蔬菜、160千卡的水果、300千卡的动物源性食品、300千卡的豆类、坚果和籽仁、300千卡的油和脂肪。共为173个国家估算了2017年至2024年的健康膳食成本。
有国际比较项目数据时的基准成本计算方法
为了计算每个时间点和每个地点成本最低的健康膳食,国际比较项目将每种食品归入食物组别,从中找出满足健康膳食篮要求的最便宜食品。健康膳食篮为每个国家挑选了11种成本最低的食品:淀粉类主粮2种、蔬菜3种、水果2种、动物源性食品2种、豆类、坚果和籽仁1种、油和脂肪1种。每个食物组别每天成本的计算方法是将该类别中选中的食品的价格乘以满足该类别健康膳食篮所需能量含量的数量。最后,将六个食物组别的成本相加得出每个国家的健康膳食成本。
无国际比较项目数据时的成本推算方法
国际比较项目目前是能够提供国际标准化食品零售价格数据的唯一来源,且这些数据每三到四年才能公布一次,无法每年据此对健康膳食成本进行更新。国际比较项目数据最近的系列数据于2024年发布,涉及2021年的价格。为了在国际比较项目未发布数据的年份里更新成本指标,我们将粮农组织公布的食品消费价格指数应用到2021年的健康膳食成本上,从而估算出国际比较项目未公布数据年份的成本。这一数据集以2015年为基线年份,跟踪国家层面每月的整体消费价格指数和食品消费价格指数。年度消费价格指数数据为一年12个月的消费价格指数数据的几何平均值。估算缺失年份健康膳食成本c(PPP)t的方法是将每个国家2021年的实际成本(以当地货币单位表示)乘以食品消费价格指数(FCPI)比值,最后除以购买力平价(PPP):
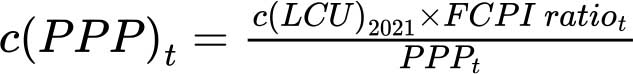
其中t=2017至2024年,不包括2021年,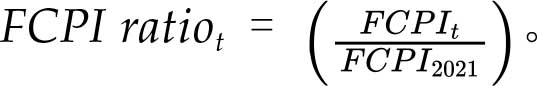 。
。
今年的报告首次做到了能报告健康膳食成本与可负担性指标在报告出版一年前的数据。此改进得益于及时获得世界银行现时预测贫困状况时所采用的有关2024年购买力平价换算系数、食品消费价格指数以及收入分布的数据。然而,就购买力平价换算系数而言,虽然数据来自世界发展指标数据库,但43个国家缺少2024年相关信息,5个国家缺少2023年相关信息(见附件1A,表A1.5)。因此,这些国家2023年和2024年的购买力平价数值采用世界银行世界发展指标推算法估算而来,13公式如下:
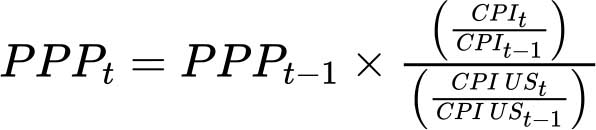
其中CPI代表整体消费价格指数,CPI US代表基准国家(本文中为美利坚合众国)的整体消费价格指数。
针对缺失三年及以上购买力平价(PPP)数据的15个国家,采用带外部解释变量的自回归差分移动平均模型(ARIMAX)估算PPP(见附件1A中的表A1.5)。根据世界银行世界发展指标的PPP估算法,将一个国家的整体消费价格指数与美利坚合众国的消费价格指数之间的比值放入模型,作为PPP值的一项关键预测因素。此外,人均国内生产总值(GDP)和人均家庭消费支出也被作为外部协变量,如有需要,采用Holt-Winter平滑法来填补这两个系列数据中的空白。ARIMAX方法能让我们为每个国家设定几种模型结构,其中包括自回归部分、差分部分、移动平均部分和以上三项的组合。当至少CPI比值的估计系数具有统计学显著性时,就能选出最佳模型结构,其次要看ARIMAX参数的统计学显著性。对于PPP系列数值随时间变化显示异常的国家和领土,其CPI比值就是影响PPP数值变化的唯一统计学显著系数。相反,对于PPP系列数值波动不大的国家和领土,PPP的历史趋势也在预测PPP数值以及人均GDP和/或人均支出系数估计值时发挥作用。ARIMAX能采用为每个国家/领土选择的最佳模型结构计算出预测值。
挑战和局限性
由于并非每年都能获得国际标准化食品的价格数据,无法开展年度监测。用于更新健康膳食成本的方法有一个缺点,那就是成本的变化取决于食品消费价格指数,不反映具体食品项目的价格变化,也不反映不同食物组别价格变化的差异。bc粮农组织正与世界银行合作,探索如何扩大对具体食品层面价格或食品组别层面价格的报告,以便更频繁、更准确地监测健康膳食成本。
健康膳食成本的区域和全球汇总采用每个组别中各国的算术平均值计算。
推荐阅读
Bai, Y., Conti, V., Herforth, A., Cafiero, C., Ebel, A., Rissanen, M.O., Masters, W.A & Rosero Moncayo, J. 2024. Methods for monitoring the cost of a healthy diet based on price data from the International Comparison Program. FAO Statistics Working Paper Series, No. 24-43. Rome, FAO. https://doi.org/10.4060/cd3037en
Herforth, A., Bai, Y., Venkat, A., Mahrt, K., Ebel, A. & Masters, W.A. 2020. Cost and affordability of healthy diets across and within countries – Background paper for The State of Food Security and Nutrition in the World 2020. FAO Agricultural Development Economics Technical Study, No. 9. Rome, FAO. https://doi.org/10.4060/cb2431en
Herforth, A., Venkat, A., Bai, Y., Costlow, L., Holleman, C. & Masters, W.A. 2022. Methods and options to monitor the cost and affordability of a healthy diet globally – Background paper to The State of Food Security and Nutrition in the World 2022. FAO Agricultural Development Economics Working Paper 22-03. Rome, FAO. https://doi.org/10.4060/cc1169en
无力负担健康膳食
定义
无力负担健康膳食定义为家庭或个人在收入中扣除用以购置除食品外所有必需品的金额后,无力以最低价格购买满足健康膳食所需的当地可得食物组合。
报告方式
“无力负担发生率(PUA)”主指标指可支配收入扣除购置除食品外所有基本商品和服务所需金额后低于健康膳食最低成本的个体在人口中所占百分比估计值。各国估计值的计算方法是,将特定国家的收入分布情况与一项阈值(r)进行比较,该阈值通过将各国健康膳食的成本与非食品类基本需求的成本(n)相加得出。除了计算PUA外,还通过将PUA乘以参考人口规模,计算出无力负担健康膳食的人口数量(NUA)。
每一期新报告都会对PUA和NUA全系列(2017–2024年)进行修订,以反映最新成本数据、人口数据和收入分布情况。由于修订过程通常意味着对PUA和NUA全系列进行回溯修订,建议读者避免对本报告不同版本中的数据系列进行比较,而应以当期报告中的数值为准,包括以往年份数值。
方法
为了估算某一人群的PUA,我们为每个国家计算了每日人均成本阈值。由于缺乏用于确定特定国家非食品类基本商品和服务成本的信息,我们在世界银行国家收入四个分组基础上分析在非食品类支出上的差异。因此,每日人均成本阈值综合了一个国家i的健康膳食成本与国家i所属收入组别j的非食品类基本需求成本。最终成本阈值ri的确定方法如下:

其中ci是一国的健康膳食成本,nj是收入组别j的非食品类基本需求成本。最终nj用参考年份贫困线的货币价值表示(即2017年购买力平价美元),其计算方法是将世界银行国际贫困线乘以每个收入组别非食品类基本商品和服务支出在总支出中所占比例,如下所示:

确定收入中用于非食品类商品和服务的比例时,其参考依据是低收入和中等偏下收入国家属于收入分布第二个五分位数的家庭以及中等偏上收入和高收入国家属于收入分布第一个五分位数的家庭所报告的数据。具体比例来自世界银行汇编的最新家庭调查结果,其中包括来自不同收入组别的71个国家的实际消费信息。
虽然非食品类基本成本(nj)已经用2017年购买力平价表示,但健康膳食成本要采用以下公式从现值(ct)换算成2017年购买力平价值(ct2017 PPP):
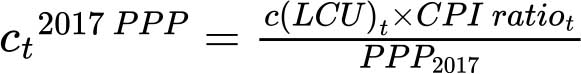
其中t=2017至2024年,不包括2021年,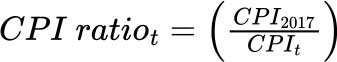 用整体消费价格指数计算。
用整体消费价格指数计算。
最后,将用2017年购买力平价表示的成本阈值ri与反映家庭可支配收入的特定国家收入分布情况x_i进行比较,估算出收入低于该阈值的人口百分比,如以下公式所示:
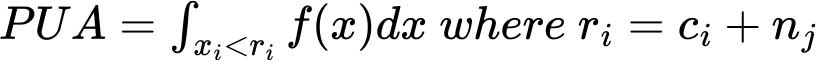
数据来源
收入分布数据来自世界银行贫困与不平等数据平台,截至2024年约150个国家有数据可查。14
无力负担发生率的区域和全球汇总通过计算有数据国家的PUA人口加权平均值获得,如下所示:
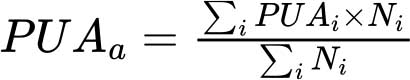
其中a表示区域或其他汇总值,PUAi是汇总值中国家i的PUA估计值,Ni是相对应的人口规模。当有估计值的国家至少覆盖汇总人口的50%时,才会生成区域汇总值。
接下来要计算无力负担健康膳食的人口数量(NUAa),具体方法是将平均PUAa(根据有数据国家计算而来)乘以汇总所涉所有国家总人口规模Na。

全球NUA数值的计算方法是,将世界五大区域中每个区域的PUA乘以每个区域的总人口。应避免采用将其他国家分组方法(如按收入水平分组法)得出的NUA相加来计算全球NUA的做法。人口数据来自《世界人口展望》2024年修订版。4
挑战和局限性
在本期报告中,我们对方法做了调整,以便考虑到不同国家在非食品类需求成本方面的差异。然而,由于缺乏具体国家信息,只能按收入组别而不是按国家来考虑非食品类支出差异。此外,除了需要通过校正来调整不同国家间的差异之外,另一个重要方面是认识到每个国家内部在最低体面生活水准的成本(r = c + n)上也存在差异。特别是对那些多元化大国而言,无法考虑这些差异并采用按国家平均水平设定的成本阈值r,都可能导致对不可负担性的估算出现偏差。偏差的方向和程度取决于收入水平与正确、因地而异的阈值之间可能存在的关联的方向和大小。
推荐阅读
Bai, Y., Herforth, A., Cafiero, C., Conti, V., Rissanen, M.O., Masters, W.A. & Rosero Moncayo, J. 2024. Methods for monitoring the affordability of a healthy diet. FAO Statistics Working Paper Series, No. 24-44. Rome, FAO. https://doi.org/10.4060/cd3703en
Herforth, A., Bai, Y., Venkat, A., Mahrt, K., Ebel, A. & Masters, W.A. 2020. Cost and affordability of healthy diets across and within countries – Background paper for The State of Food Security and Nutrition in the World 2020. FAO Agricultural Development Economics Technical Study, No. 9. Rome, FAO. https://doi.org/10.4060/cb2431en
五岁以下儿童消瘦
定义
身高/身长(厘米)别体重(公斤)低于世卫组织儿童生长标准中位数2个标准差(−2 SD)。
报告方式
0至59月龄儿童中,身高别体重低于世卫组织儿童生长标准中位数2个标准差(−2 SD)的人数所占百分比。相关估计值来自《儿童营养不良水平和趋势:联合国儿童基金会/世界卫生组织/世界银行集团儿童营养不良联合估计 — 2025年版主要发现》。43由于每期新报告都会对整个汇总数据系列进行修订,建议读者避免将区域和全球系列数据与往期报告中的数据进行比较。
方法
国家层面
儿童营养不良联合估计(JME)数据集里包含点估计值,可能时还包含标准差、95%置信区间和未加权样本大小。如有微观数据,数据集会采用经过重新计算的估计值,以符合全球标准定义。如果没有微观数据,则采用所报告的估计值,除非因为以下原因需要进行调整以实现标准化:
- 采用了2006年世卫组织儿童生长标准里的替代生长参考标准;
- 年龄范围不包括完整的0至59个月年龄组;
- 数据来源仅对居住在农村地区的人口具有全国代表性。
区域和全球汇总
我们利用2025年5月JME数据集里有关消瘦发生率的数据,采用联合估计的次区域多级模型和《世界人口展望》2024年修订版中五岁以下儿童人口权重,来生成1990年至2024年的区域和全球估计值。4
数据来源
具有全国代表性的家庭调查,如人口与健康调查、多指标类集调查、救济与过渡标准化监测与评估调查、生活水平测量研究调查,是最常见的用于收集五岁以下儿童身高、体重和年龄相关全国代表性营养数据的来源,可用于估算消瘦在国家层面的发生率。也可采用行政数据来源(如来自常规系统或监测系统的数据),前提是其人口覆盖率较高。
鉴于全国调查可在任何季节进行,调查时儿童消瘦发生率可能处于高位或低位,有时如果数据收集工作跨越多个季节,发生率就可能介于高位和低位之间。因此,消瘦发生率反映的是特定时间点的消瘦情况,而不是一整年的情况。调查在不同季节进行,使得我们很难对趋势做出推断。
挑战和局限性
建议各国每三到五年报告一次消瘦情况,但一些国家收集数据的频率较低。尽管已尽最大可能使统计数据在不同国家和不同时段之间具有可比性,但各国数据在收集方法、人口覆盖率和估算方法等方面均可能存在差异。调查得出的估计数据由于抽样误差和非抽样误差(技术测量误差、记录误差等)具有一定程度的不确定性。在估算国家层面或区域和全球层面数据时,以上两种误差问题都未得到充分解决。
推荐阅读
de Onis, M., Blössner, M., Borghi, E., Morris, R. & Frongillo, E.A. 2004. Methodology for estimating regional and global trends of child malnutrition. International Journal of Epidemiology, 33(6): 1260–1270. https://doi.org/10.1093/ije/dyh202
UNICEF (United Nations Children’s Fund), WHO & World Bank. 2024. The UNICEF-WHO-World Bank Joint Child Malnutrition Estimates (JME) standard methodology. New York, USA. https://iris.who.int/bitstream/handle/10665/379080/9789240100190-eng.pdf?sequence=1
UNICEF, WHO & World Bank. 2025. Levels and trends in child malnutrition: UNICEF/WHO/World Bank Group Joint Child Malnutrition Estimates. Key findings of the 2025 edition. New York, USA, Geneva, Switzerland and Washington, DC. https://data.unicef.org/resources/JME, https://www.who.int/teams/nutrition-and-food-safety/monitoring-nutritional-status-and-food-safety-and-events/joint-child-malnutrition-estimates/latest-estimates, https://datatopics.worldbank.org/child-malnutrition
WHO. 2014. Comprehensive Implementation Plan on maternal, infant and young child nutrition. Geneva, Switzerland. https://www.who.int/publications/i/item/WHO-NMH-NHD-14.1
WHO. 2024. Nutrition Landscape Information System (NLIS) country profile indicators: interpretation guide. Second edition. Geneva, Switzerland. https://www.who.int/publications/i/item/9789241516952
五岁以下儿童发育迟缓
定义
年龄(天)别身高/身长(厘米)低于世卫组织儿童生长标准中位数2个标准差(−2 SD)。
报告方式
0至59月龄儿童中,年龄别身高低于世卫组织儿童生长标准中位数2个标准差(−2 SD)的人数所占百分比。相关估计值来自《儿童营养不良水平和趋势:联合国儿童基金会/世界卫生组织/世界银行集团儿童营养不良联合估计 — 2025年版主要发现》。43由于每期新报告都会对整个汇总数据系列进行修订,建议读者避免将区域和全球系列数据与往期报告中的数据进行比较。
方法
国家层面
儿童营养不良联合估计(JME)数据集里包含点估计值,可能时还包含标准差、95%置信区间和未加权样本大小。如有微观数据,数据集会采用经过重新计算的估计值,以符合全球标准定义。如果没有微观数据,则采用所报告的估计值,除非因为以下原因需要进行调整以实现标准化:
- 采用了2006年世卫组织儿童生长标准里的替代生长参考标准;
- 年龄范围不包括完整的0至59个月年龄组;
- 数据来源仅对居住在农村地区的人口具有全国代表性。
我们在2025年5月JME数据集基础上,采用带有异质误差项的惩罚纵向混合模型在logit(对数几率)尺度上对发育迟缓发生率进行建模。模型的质量通过模型拟合标准进行量化,该标准能平衡模型的复杂性与观测数据的拟合度。这一方法具有重要特征,包括非线性时间趋势、区域趋势、特定国家趋势、协变量数据和异质误差项。所有具备数据的国家均为估计总体时间趋势及协变量数据对发生率的影响提供了数据。协变量数据包含线性和二次社会人口指数(SDI)bd以及过去五年卫生服务平均可及性。
JME于2025年公布了2000年至2024年162个国家和地区关于发育迟缓的年度国家层面模型估计值。另外还为43个国家建模生成了国家估计值,仅用于生成区域和全球汇总数据。
区域和全球汇总
1990年至2024年间所有年份全球和区域汇总数据的计算方法是:采用205个国家和地区基于模型的估计值,以《世界人口展望》2024年修订版4中各国五岁以下儿童人口为权重,计算出各国平均值,其中162个国家和地区的估计值已公布,还有43个国家是为了生成区域和全球汇总数据而建模生成估计值,但未公布建模生成的国家估计值。
数据来源
具有全国代表性的家庭调查(如人口与健康调查、多指标类集调查、救济与过渡标准化监测与评估调查、生活水平测量研究调查)是最常见的用于收集五岁以下儿童身高和年龄相关全国代表性营养数据的来源,可用于估算发育迟缓在国家层面的发生率。也可采用行政数据来源(如来自常规系统或监测系统的数据),前提是其人口覆盖率较高。
挑战和局限性
建议各国每三到五年报告一次发育迟缓情况,但一些国家收集数据的频率较低。尽管已尽最大可能使统计数据在不同国家和不同时段之间具有可比性,但各国数据在收集方法、人口覆盖率和估算方法等方面均可能存在差异。调查得出的估计数据由于抽样误差和非抽样误差(技术测量误差、记录误差等)具有一定程度的不确定性。在估算国家层面或区域和全球层面数据时,以上两种误差问题都未得到充分解决。
推荐阅读
Brauer, M., Roth, G.A., Aravkin, A.Y., Zheng, P., Abata, K.H., Abate, Y.H., Abbafati, C. et al. 2021. Global burden and strength of evidence for 88 risk factors in 204 countries and 811 subnational locations, 1990-2021: a systematic analysis for the Global Burden of Disease Study 2021. The Lancet, 403(10440): 2162–2203. https://doi.org/10.1016/S0140-6736(24)00933-4. Erratum. The Lancet, 404(10449): 244. https://doi.org/10.1016/S0140-6736(24)01458-2.
McLain, A.C., Frongillo, E.A., Feng, J. & Borghi, E. 2019. Prediction intervals for penalized longitudinal models with multisource summary measures: An application to childhood malnutrition. Statistics in Medicine, 38(6): 1002–1012. https://doi.org/10.1002/sim.8024
UNICEF, WHO & World Bank. 2024. The UNICEF-WHO-World Bank Joint Child Malnutrition Estimates (JME) standard methodology. New York, USA. https://iris.who.int/bitstream/handle/10665/379080/9789240100190-eng.pdf?sequence=1
UNICEF, WHO & World Bank. 2025. Levels and trends in child malnutrition: UNICEF/WHO/World Bank Group Joint Child Malnutrition Estimates. Key findings of the 2025 edition. New York, USA, Geneva, Switzerland and Washington, DC. https://data.unicef.org/resources/JME, https://www.who.int/teams/nutrition-and-food-safety/monitoring-nutritional-status-and-food-safety-and-events/joint-child-malnutrition-estimates/latest-estimates, https://datatopics.worldbank.org/child-malnutrition
WHO. 2014. Comprehensive Implementation Plan on maternal, infant and young child nutrition. Geneva, Switzerland. https://www.who.int/publications/i/item/WHO-NMH-NHD-14.1
WHO. 2024. Nutrition Landscape Information System (NLIS) country profile indicators: interpretation guide. Second edition. Geneva, Switzerland. https://www.who.int/publications/i/item/9789241516952
WHO & UNICEF. 2019. Recommendations for data collection, analysis and reporting on anthropometric indicators in children under 5 years old. Geneva, Switzerland and New York, USA. https://www.who.int/publications/i/item/9789241515559
五岁以下儿童超重
定义
身高/身长(厘米)别体重(公斤)高于世卫组织儿童生长标准中位数2个标准差(+2 SD)。
报告方式
0至59月龄儿童中,身高别体重高于世卫组织儿童生长标准中位数2个标准差(+2 SD)的人数所占百分比。相关估计值来自《儿童营养不良水平和趋势:联合国儿童基金会/世界卫生组织/世界银行集团儿童营养不良联合估计 — 2025年版主要发现》。43由于每期新报告都会对整个汇总数据系列进行修订,建议读者避免将区域和全球系列数据与往期报告中的数据进行比较。
方法
国家层面
儿童营养不良联合估计(JME)数据集里包含点估计值,可能时还包含标准差、95%置信区间和未加权样本大小。如有微观数据,数据集会采用经过重新计算的估计值,以符合全球标准定义。如果没有微观数据,则采用所报告的估计值,除非因为以下原因需要进行调整以实现标准化:
- 采用了2006年世卫组织儿童生长标准里的替代生长参考标准;
- 年龄范围不包括完整的0至59个月年龄组;
- 数据来源仅对居住在农村地区的人口具有全国代表性。
我们在2025年5月JME数据集基础上,采用带有异质误差项的惩罚纵向混合模型在logit(对数几率)尺度上对超重发生率进行建模。模型的质量通过模型拟合标准进行量化,该标准能平衡模型的复杂性与观测数据的拟合度。这一方法具有重要特征,包括非现象时间趋势、区域趋势、特定国家趋势、协变量数据和异质误差项。所有具备数据的国家均为估计总体时间趋势及协变量数据对发生率的影响提供了数据。协变量数据包含线性和二次社会人口指数。
JME于2025年公布了2000年至2024年163个国家和地区关于超重的国家层面模型年度估计值。另外还为42个国家建模生成了国家估计值,仅用于生成区域和全球汇总数据。
区域和全球汇总
1990年至2024年间所有年份全球和区域汇总数据的计算方法是:采用205个国家基于模型的估计值,以《世界人口展望》2024年修订版4中各国五岁以下儿童人口为权重,计算出各国平均值,其中163个国家和地区的估计值已公布,还有42个国家是为了生成区域和全球汇总数据而建模生成估计值,但未公布建模生成的国家估计值。
数据来源
具有全国代表性的家庭调查(如人口与健康调查、多指标类集调查、救济与过渡标准化监测与评估调查、生活水平测量研究调查)是最常见的用于收集五岁以下儿童身高、体重和年龄相关全国代表性营养数据的来源,可用于估算超重在国家层面的发生率。也可采用行政数据来源(如来自常规系统或监测系统的数据),前提是其人口覆盖率较高。
挑战和局限性
建议各国每三到五年报告一次超重情况,但一些国家收集数据的频率较低。尽管已尽最大可能使统计数据在不同国家和不同时段之间具有可比性,但各国数据在收集方法、人口覆盖率和估算方法等方面均可能存在差异。调查得出的估计数据由于抽样误差和非抽样误差(技术测量误差、记录误差等)具有一定程度的不确定性。在估算国家层面或区域和全球层面数据时,以上两种误差问题都未得到充分解决。
推荐阅读
Brauer, M., Roth, G.A., Aravkin, A.Y., Zheng, P., Abata, K.H., Abate, Y.H., Abbafati, C. et al. 2024. Global burden and strength of evidence for 88 risk factors in 204 countries and 811 subnational locations, 1990-2021: a systematic analysis for the Global Burden of Disease Study 2021. The Lancet, 403(10440): 2162–2203. https://doi.org/10.1016/S0140-6736(24)00933-4. Erratum, The Lancet, 404(10449): 244. https://doi.org/10.1016/S0140-6736(24)01458-2.
McLain, A.C., Frongillo, E.A., Feng, J. & Borghi, E. 2019. Prediction intervals for penalized longitudinal models with multisource summary measures: An application to childhood malnutrition. Statistics in Medicine, 38(6): 1002–1012. https://doi.org/10.1002/sim.8024
UNICEF, WHO & World Bank. 2024. The UNICEF-WHO-World Bank Joint Child Malnutrition Estimates (JME) standard methodology. New York, USA. https://iris.who.int/bitstream/handle/10665/379080/9789240100190-eng.pdf?sequence=1
UNICEF, WHO & World Bank. 2025. Levels and trends in child malnutrition: UNICEF/WHO/World Bank Group Joint Child Malnutrition Estimates. Key findings of the 2025 edition. New York, USA, Geneva, Switzerland and Washington, DC. https://data.unicef.org/resources/JME, https://www.who.int/teams/nutrition-and-food-safety/monitoring-nutritional-status-and-food-safety-and-events/joint-child-malnutrition-estimates/latest-estimates, https://datatopics.worldbank.org/child-malnutrition
WHO. 2014. Comprehensive Implementation Plan on maternal, infant and young child nutrition. Geneva, Switzerland. https://www.who.int/publications/i/item/WHO-NMH-NHD-14.1
WHO. 2024. Nutrition Landscape Information System (NLIS) country profile indicators: interpretation guide. Second edition. Geneva, Switzerland. https://www.who.int/publications/i/item/9789241516952
WHO & UNICEF. 2019. Recommendations for data collection, analysis and reporting on anthropometric indicators in children under 5 years old. Geneva, Switzerland and New York, USA. https://www.who.int/publications/i/item/9789241515559
纯母乳喂养
定义
指六月龄内婴儿只接受母乳喂养,不额外添加任何食物或饮料,甚至水。
报告方式
调查前24小时内只接受母乳喂养、不额外添加任何食物或饮料(甚至水)的0至5月龄婴儿所占百分比。
相关估计值来自联合国儿童基金会婴幼儿喂养全球数据库。15
方法
国家层面
此项指标指纯母乳喂养,不添加其他食物或饮料,甚至是水。估计值基于对0至5月龄婴儿前一天喂养情况的回忆。

由乳母喂养、用挤出的母乳喂养以及用捐赠的母乳喂养都算作母乳喂养。处方药、口服补液溶液、维生素和矿物质不算作液体或食物。但草药液体和类似的传统药物算作液体,食用此类液体的婴儿不算作纯母乳喂养。
区域和全球汇总
2012年的区域和全球纯母乳喂养估计值采用2005年至2012年间各国的最新估计值生成。同样,2022年的估计值采用2017年至2023年间各国的最新估计值生成(五个国家除外,对它们采用的是2024年的数据)。计算全球和区域估计值时,将《世界人口展望》2024年修订版(2012年为基线年份,2023年为当前年份)中0至5月龄婴儿总数(零岁人口的一半)作为权重,计算出每个国家纯母乳喂养率加权平均值。4仅在现有数据代表相应区域0至5月龄婴儿总数至少50%的情况下才显示估计值,除非另有说明。
数据来源
数据来自具有全国代表性的家庭调查,如人口与健康调查和多指标类集调查。估计值基于0至23月龄婴儿调查前24小时内的液体和食物摄入量。
挑战和局限性
虽然有较高比例的国家收集纯母乳喂养数据,但高收入国家尤其缺乏数据。根据建议,应每三到五年报告一次纯母乳喂养情况,但一些国家的报告频率较低,这意味着喂养方式的变化往往在变化发生几年后才被发现。
区域和全球平均值可能会受到本报告所涉期间哪些国家具有数据的影响。
采用前一天喂养情况作为依据可能会导致纯母乳喂养的婴儿比例被高估,因为部分婴儿可能不定期被喂食其他液体或食物,而调查前一天没有喂食。
推荐阅读
UNICEF. 2024. Infant and young child feeding. In: UNICEF. [Cited 30 April 2025]. https://data.unicef.org/topic/nutrition/infant-and-young-child-feeding
WHO. 2014. Comprehensive implementation plan on maternal, infant and young child nutrition. Geneva, Switzerland. https://www.who.int/publications/i/item/WHO-NMH-NHD-14.1
WHO. 2024. Nutrition Landscape Information System (NLIS) country profile indicators: interpretation guide. Second edition. Geneva, Switzerland. https://www.who.int/publications/i/item/9789241516952
WHO & UNICEF. 2021. Indicators for assessing infant and young child feeding practices: definitions and measurement methods. Geneva, Switzerland and New York, USA. https://www.who.int/publications/i/item/9789240018389
低出生体重
定义
出生时体重低于2500克。
报告方式
出生时体重低于2500克(低于5.51磅)的新生儿所占百分比。估计值来自联合国儿童基金会和世卫组织《低出生体重联合估计》2023年版。16由于每期新报告都会对整个估计值系列进行修订,建议读者避免与往期报告中的数据系列进行比较。
方法
国家层面
报告整理了158个国家2000年至2020年具有全国代表性的低出生体重数据,包括调查数据和行政数据。之后采用数据质量标准和调整方法,形成最终的国家数据集,并将其纳入建模过程。国家数据在被输入数据集之前,已经过覆盖面和质量审查,再进行调整,以解决出生体重数据缺失和堆积造成的偏差。行政数据中关于出生体重的数据要想被纳入数据集,条件是必须覆盖《世界人口展望》2022年修订版17中活产婴儿估计数的至少80%。国家家庭调查数据要想被纳入数据集,必须符合以下条件:
- 调查数据中至少30%的样本有出生体重;
- 数据集中至少有200个出生体重数据;
- 没有严重的数据堆积或不可信数据分布,即:1)所有出生体重数据中,不超过55%属于三种最常见出生体重(即如果3000克、3500克和2500克是三种最常见的出生体重,则三者相加在数据集中不超过55%);2)所有出生体重数据中,不超过10%为4500克及以上;3)所有出生体重数据中,不超过5%为小于500克或大于5000克的数值;
- 已对缺失出生体重和数据堆积做了调整。
在国家层面,低出生体重发生率估计值采用贝叶斯多层次回归模型进行预测,在logit(对数几率)尺度上进行拟合,以确保比例介于0和1之间,然后进行逆变换,并乘以100,最终得出发生率估计值。
分层随机国家特定截距(全球范围内各区域内各国家)可解释不同区域内部和不同区域之间的相关性。对不同时间序列采用惩罚样条做了时间平滑处理,这意味着可在不让随机变化对趋势产生影响的前提下捕捉到国家层面的非线性时间趋势。模型中最终包含的协变量有:按购买力平价计算的人均国民总收入、be成年女性体重不足发生率、成年女性识字率、现代避孕法普及率以及城市人口比例。
本报告通过数据质量类别来应用偏差偏移和额外方差项。偏差偏移应用于较低质量类别的行政数据上,类似于调查数据调整时已经考虑到的堆积预期偏差。额外方差项基于行政数据的数据质量类别以及行政数据和调查数据之间的加权(如果该国既有行政数据又有调查数据)。
本报告进行了标准诊断检查,以评估收敛性和抽样效率;实施了交叉验证,平均采用20%的测试数据和80%的训练数据进行了超过200个随机划分;进行了敏感型分析,包括对协变量、偏差方法、时间平滑和非信息性先验的检查。所有模型均采用R统计软件以及“rjags”和“R2jags”包进行拟合。18, 19
模型中包括所有符合纳入标准的2040个国家年份数据,并为195个有低出生体重输入数据或协变量数据的国家和地区生成了2000年至2020年的年度估计值,具有95%的可信区间。报告仅呈现了有数据的国家和地区的估计数。对无数据或数据不符合纳入标准的(195个国家中)37个国家,最终模型根据用所有国家年份区域和国家层面协变量估算出来的国家截距和时间趋势,预测出低出生体重发生率估计值。
区域和全球汇总
本报告采用所有195个国家和地区的所有估计值,用《世界人口展望》2022年修订版17估计的当年活产婴儿数量加权,生成了区域和全球汇总数据。
数据来源
关于低出生体重发生率的全国代表性估计数据可从多个来源获取,广义上包括国家行政数据或代表性家庭调查。国家行政数据来自包括民事登记和生命统计系统、国家卫生管理信息系统和出生登记在内的各类国家系统。国家家庭调查,如包含出生体重信息以及母亲对出生时大小的感知等关键指标在内的人口与健康调查和多指标类集调查也是低出生体重数据的重要来源,特别是在出生体重没有记录和/或有数据堆积问题的情况下。
挑战和局限性
要想在全球范围内监测低出生体重,所面临的一项主要局限性就是世界上许多儿童缺少出生体重数据。值得注意的显著差异是,与出生在较富裕的城市地区家庭、母亲受教育程度较高的儿童相比,出生在贫困农村地区家庭、母亲受教育程度较低的儿童不太可能有出生体重记录。近三分之一包含出生体重数据的调查未被纳入最终分析,主要是因为数据缺少或质量不高,其中多数是低出生体重风险较高区域低收入国家开展的调查。
由于缺少出生体重数据的新生儿具有发生低出生体重的风险,因此不包含此类儿童的估计值可能低于真实数值。此外,低收入和中等收入国家的数据由于在500克或100克倍数上过度堆积而存在质量不高的问题,可能会进一步低估低出生体重数值。当前数据库中用于处理出生体重数据缺失和调查估计数堆积问题的方法就是用来解决这一问题。但当前方法的一项局限性是,行政数据中没有个人层面的数据,而且这些数据无法通过直接调整去除堆积和缺失造成的偏差。
建模中采用的地理分组可能不适用于流行病学或经济学意义上的区域异常值。总的来说,195个国家中有37个(没有输入数据)的估计值可能受到影响。此外,鉴于约半数建模国家每次采用自举法预测时都会随机对该国生成正面或负面影响,因此区域和全球估计值的置信限可能被人为地调小,使得区域和全球层面的相对不确定性小于国家层面。
推荐阅读
Blanc, A. & Wardlaw, T. 2005. Monitoring low birth weight: An evaluation of international estimates and an updated estimation procedure. Bulletin World Health Organization, 83(3): 178–185. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2624216
Chang, K.T., Carter, E.D., Mullany, L.C., Khatry, S.K., Cousens, S., An, X., Krasevec, J. et al. 2022. Validation of MINORMIX approach for estimation of low birthweight prevalence using a rural Nepal dataset. The Journal of Nutrition, 152(3): 872–879. https://doi.org/10.1093/jn/nxab417
Okwaraji, Y.B., Krasevec, J., Bradley, E., Conkle, J., Stevens, G.A., Gatica-Domínguez, G., Ohuma, E.O. et al. 2024. National, regional, and global estimates of low birthweight in 2020, with trends from 2000: a systematic analysis. The Lancet, 403(10431): 1071–1080. https://doi.org/10.1016/S0140-6736(23)01198-4
UNICEF & WHO. 2023. Low birthweight. In: UNICEF. [Cited 28 April 2025]. https://data.unicef.org/topic/nutrition/low-birthweight
UNICEF & WHO. 2023. Joint low birthweight estimates. In: WHO. [Cited 28 April 2025]. https://www.who.int/teams/nutrition-and-food-safety/monitoring-nutritional-status-and-food-safety-and-events/joint-low-birthweight-estimates
成人肥胖
定义
体重指数(BMI)≥30.0 kg/m2。体重指数指体重与身高之比,通常作为成人营养状况分类标准。计算方法是体重(公斤)除以身高(米)的平方(公斤/米2)。体重指数大于或等于30 kg/m2即为肥胖。
报告方式
按性别加权并按年龄标准化后,体重指数≥30.0 kg/m2的18岁以上人口所占比例。所报告的估计值基于世卫组织(2024)。44由于每期新报告都会对整个估计值系列进行修订,建议读者避免与往期报告中的数据系列进行比较。
方法
国家层面
采用了贝叶斯分层回归模型,使用马尔可夫链蒙特卡洛(MCMC)样本拟合,并使用后验MCMC样本进行推断,以估算1990年至2022年不同体重指数类型肥胖发生率趋势,按性别、年龄、国家和年份分类。以地理位置和国家收入为主要依据,将各国分为20个区域和8个超级区域。模型采用分层结构,即每个国家年份的估计值参考本国数据(如有本国数据)以及同一国家其他年份的数据和其他国家的数据,特别是同一区域和超级区域具备相近时间段数据的国家的数据。模型包括通过线性和二阶随机游走项的组合来表示非线性时间趋势,所有这些都以分层方式建模。采用三次样条对体重指数的年龄关联进行建模,以考虑不同国家之间不同的非线性年龄分布规律。对样条系数进行分层建模,允许随时间变化而变化,以便反映不断变化的年龄关联。通过采用世卫组织标准人口年龄权重,对特定年龄性别估计值进行加权平均,完成对年龄的标准化。20
区域和全球汇总
全球和区域发生率估计值为所有成员国家的人口加权平均值。
数据来源
监测成人肥胖的多数数据来自全国代表性家庭调查等基于人口的研究,这些研究会对身高和体重进行测量。
挑战和局限性
体重指数并非衡量体脂程度和分布的完美指标,但基于人口的调查中普遍具备此项数据,同时也被用于临床实践中。它还与更复杂、成本更高的双能X射线吸收法有关。
一些国家的数据很少,三个国家完全没有数据。这些国家的估计值较大程度上通过地理分层参考其他国家的数据估算。
不同年龄组的数据齐备程度也存在差异,老年人(65岁及以上)相关数据较少,这增加了该年龄组估计值的不确定性。
推荐阅读
Ahmad, O.B., Boschi-Pinto, C., Lopez, A.D., Murray, C.J., Lozano, R. & Inoue, M. 2001. Age standardization of rates: A new WHO standard. GPE Discussion Paper Series 31. Geneva, Switzerland, WHO. https://cdn.who.int/media/docs/default-source/gho-documents/global-health-estimates/gpe_discussion_paper_series_paper31_2001_age_standardization_rates.pdf
NCD-RisC (NCD Risk Factor Collaboration). 2024. Worldwide trends in underweight and obesity from 1990 to 2022: a pooled analysis of 3663 population-representative studies with 222 million children, adolescents, and adults. The Lancet, 403(10431): 1027–1050. https://doi.org/10.1016/S0140-6736(23)02750-2
WHA (World Health Assembly). 2013. Sixty-sixth World Health Assembly – Follow-up to the Political Declaration of the High-level Meeting of the General Assembly on the Prevention and Control of Non-communicable Diseases. https://apps.who.int/gb/ebwha/pdf_files/WHA66/A66_R10-en.pdf?ua=1
WHO. 2022. Updated Appendix 3 of the WHO Global NCD Action Plan 2013-2030 – Technical Annex (version dated 26 December 2022). Geneva, Switzerland. https://cdn.who.int/media/docs/default-source/ncds/mnd/2022-app3-technical-annex-v26jan2023.pdf?sfvrsn=62581aa3_5
WHO. 2024. Noncommunicable Diseases Data Portal. In: WHO. [Cited 8 April 2024]. https://ncdportal.org
WHO. 2024. Nutrition Landscape Information System (NLIS) country profile indicators: interpretation guide. Second edition. Geneva, Switzerland. https://www.who.int/publications/i/item/9789241516952
WHO. 2024. Global Health Observatory data repository: Prevalence of obesity among adults, BMI ≥ 30, age-standardized – Estimates by country. [Accessed on 24 July 2024]. https://www.who.int/data/gho/data/indicators/indicator-details/GHO/prevalence-of-obesity-among-adults-bmi-=-30-(age-standardized-estimate)-(-). Licence: CC-BY-4.0.
15至49岁女性贫血
定义
15至49岁非孕妇和非哺乳期女性血红蛋白浓度低于120 g/L,孕妇低于110 g/L,已考虑海拔高度和吸烟因素。
报告方式
15至49岁女性中孕妇血红蛋白浓度低于110 g/L、非孕妇低于120 g/L的人数所占比例。估计值基于世卫组织(2025)。45由于每期新报告都会对整个估计值系列进行修订,建议读者避免与往期报告中的数据系列进行比较。
方法
国家层面
按妊娠状态分类的2025年版15至49岁女性贫血估计值数据来自世卫组织维生素和矿物质营养信息系统(VMNIS)中的微量元素数据库以及1995年至2023年匿名个人数据。必要时(对海拔高度较高的国家而言)根据海拔高度对血红蛋白浓度数据进行调整,可行时根据吸烟情况进行调整。已排除生物学上不合理的血红蛋白值(<25 g/L或>200 g/L)。
报告采用贝叶斯分层混合模型,参考同一国家同一年份数据、同一国家其他年份数据以及同一区域其他国家数据来估算每个国家年份的趋势。模型将更多关注放在数据不足的国家上,而不是数据充足的国家。对趋势进行建模时,得出的是国家、区域、全球层面的线性加上平滑非线性趋势。估计值还参考了社会人口指数、肉类供应量、超重发生率等协变量。更多信息参见背景文件《世卫组织按妊娠状态分类估算关于15至49岁女性贫血发生率的可持续发展目标2.2.3指标的标准方法》。21
本期报告改进了对末梢采血和HemoCue® 301血红蛋白分析仪相关数据因存在潜在测量误差和偏差而进行处理的方法。对末梢血,我们采用血红蛋白浓度平均值来最大限度减少误差,而对静脉血则采用所有现有数据进行评估。模型中包含一项HemoCue® 301血红蛋白分析仪指标,以充分考虑到仪器测量可能存在的偏差,提高贫血发生率预测的准确性。
通过这种方法根据世卫组织1989年以来的阈值(孕妇<110 g/L,非孕妇<120 g/L)生成了关于血红蛋白水平和贫血发生率的连贯估计值。22虽然由于个人数据不足无法开展重新分析而未采用2024年的最新标准,23但目前正在为下一轮更新工作做准备,届时将纳入新的划分标准。
区域和全球汇总
全球和区域发生率估计值为所有成员国家的人口加权平均值。
数据来源
首选的数据来源是基于人口的调查。有些情况下可能会采用监测系统的数据,但诊断记录通常会出现低估。世卫组织VMNIS系统的微量元素数据库24汇总各种其他资料中有关人群微量元素状况的数据,其中包括从科学文献中以及通过合作伙伴收集的数据,合作伙伴包括世卫组织区域和国家办事处、联合国机构、各国卫生部、研究学术机构和非政府组织。此外,还从多国调查中获取匿名个人数据,这些调查包括人口与健康调查、疟疾指标调查和生殖健康调查。
挑战和局限性
尽管有较高比例的国家具备关于贫血的全国代表性调查数据,但就这一指标的报告仍然不足,特别是在高收入国家里。此外,本轮估计值中仅包含采用已知衡量方法的数据来源。因此,估计值可能无法完全反映出不同国家之间的差异,因而在数据不足时趋向于“收缩”至全球平均水平。
推荐阅读
Stevens, G.A., Paciorek, C.J., Flores-Urrutia, M.C., Borghi, E., Namaste, S., Wirth, J.P., Suchdev, P.S., Ezzati, M., Rohner, F., Flaxman, S.R. & Rogers, L.M. 2022. National, regional, and global estimates of anaemia by severity in women and children for 2000–19: a pooled analysis of population-representative data. The Lancet Global Health, 10(5): e627–e639. https://doi.org/10.1016/S2214-109X(22)00084-5
WHO. 2011. Haemoglobin concentrations for the diagnosis of anaemia and assessment of severity – Vitamin and Mineral Nutrition Information System. Geneva, Switzerland. https://iris.who.int/bitstream/handle/10665/85839/WHO_NMH_NHD_MNM_11.1_eng.pdf
WHO. 2014. Comprehensive Implementation Plan on Maternal, Infant and Young Child Nutrition. Geneva, Switzerland. https://www.who.int/publications/i/item/WHO-NMH-NHD-14.1
WHO. 2025. Global nutrition Targets 2030 to improve maternal, infant and young child nutrition. Dashboard. In: WHO. [Cited 6 June 2025]. https://data.who.int/dashboards/nutrition?m49=004
WHO. 2025. Nutrition Data Portal. In: WHO. [Cited 8 May 2025]. https://platform.who.int/nutrition/nutrition-portals
WHO. 2025. Vitamin and Mineral Nutrition Information System (VMNIS). In: WHO. [Cited 8 May 2025]. https://www.who.int/teams/nutrition-and-food-safety/databases/vitamin-and-mineral-nutrition-information-system
WHO. 2025. WHO global anaemia estimates, 2025 edition. In: WHO. [Cited 8 May 2025]. https://www.who.int/data/gho/data/themes/topics/anaemia_in_women_and_children
WHO. 2025. WHO standard methodology to estimate SDG 2.2.3 indicator on anaemia prevalence in women 15-49 years, by pregnancy status. 2000-2023. Geneva, Switzerland. [Cited 6 June 2025]. https://www.who.int/teams/nutrition-and-food-safety/monitoring-nutritional-status-and-food-safety-and-events/global-anaemia-estimates/methodology-for-the-global-anaemia-estimates


