




食物不足发生率
定义:食物不足指一个人的惯常食物消费量平均不足以为维持正常、积极、健康的生活提供必要的膳食能量。
报告方式:这项指标(以“食物不足发生率”[PoU]表示)是指处于食物不足状态的个人在总人口中的估计百分比。国家估计数以三年移动平均值进行报告,以便减少食品库存年际变动等基本参数可靠性较低造成的影响;食品库存是粮农组织年度食物平衡表的内容之一,有关此项内容很难找到全面、可靠的信息。另一方面,区域和全球合计数则报告为年度估计数,因为预计国家之间的可能估计误差并不存在关联。
方法:为估计人口中的食物不足发生率,要对普通个体惯常膳食能量摄入水平(以每人每天千卡数表示)的概率分布进行建模,表示为参数概率密度函数(pdf),f(x)396,397。该指标显示为惯常膳食能量摄入量(x)低于最低膳食能量需求量(MDER)(即人口中有代表性的普通个体能量需求量最低容许范围)的累计概率,如下方公式所示:

其中 θ 是描述参数概率密度函数的参数向量。假设分布为对数正态,仅通过两项参数便能充分体现,即平均膳食能量消费量(DEC)及其变异系数(CV)。
数据来源:模型不同参数的估计使用了不同的数据来源。
最低膳食能量需求量(MDER):特定性别/年龄组个体能量需求量的确定方法:每公斤体重基础代谢率(BMR)的标准需求,乘以该性别/年龄组健康个体身高所对应的理想体重,再乘以体力活动水平(PAL)系数,以期反映体力活动。ao如果从体重指数看,一个人既非体重不足,也非超重,则该个人是健康的。粮农组织和世卫组织(2004年)发布了人类每公斤体重的能量需求标准。鉴于健康体重指数(BMI)和体力活动水平在同一性别和年龄组的积极健康个体中都有所不同,所以每个性别和年龄组都有若干个适用的能量需求数值。人群中普通个体的最低膳食能量需求量是食物不足发生率公式中采用的参数,以每个性别和年龄组人口比例作为权重,对各性别和年龄组的能量需求量范围下限平均值加权计算得出。与最低膳食能量需求量相似,平均膳食能量需求量(ADER)是基于体力活动水平中“积极或适度积极生活方式”类别的平均数值估计得出。
联合国经济和社会事务部(经社部)两年修订一次的《世界人口展望》中提供了世界上大多数国家和每年按性别和年龄划分的人口结构信息。本报告参照的是《世界人口展望》2019年修订版。398
特定国家各性别和年龄组的中位数身高信息来自最新人口和健康调查(DHS),或收集儿童和成人人体测量数据的其他调查。即使此类调查的年份不同于食物不足发生率的估计年份,但期间中位数身高的小幅变化对食物不足发生率估计数的影响可以忽略不计。
膳食能量消费量(DEC):理想情况下,食物消费数据应来自具有全国代表性的家庭调查(如“生活水平衡量调查”或“家庭收入和支出调查”)。然而,只有极少数国家每年开展这种调查。因此,粮农组织在估计用于全球监测工作的食物不足发生率时,采用本组织为大多数国家编制的食物平衡表(FBS)中报告的膳食能量供应量(DES)来估计膳食能量消费量(见粮农组织,2021)90。
自本报告前一版本发布以来,粮农组织统计数据库中新的食物平衡表域中所有国家的数据均以更新至2019年。此外,在本报告编写结束之时,食物平衡表系列已经更新到2020年,涵盖了以下63个食物不足人数最多的国家:阿富汗、阿尔及利亚、安哥拉、孟加拉国、多民族玻利维亚国、布基纳法索、柬埔寨、喀麦隆、中非共和国、乍得、中国大陆、哥伦比亚、刚果、科特迪瓦、朝鲜民主主义人民共和国、刚果民主共和国、厄瓜多尔、斯威士兰、埃塞俄比亚、危地马拉、几内亚、海地、洪都拉斯、印度、印度尼西亚、伊朗伊斯兰共和国、伊拉克、肯尼亚、老挝人民民主共和国、利比里亚、马达加斯加、马拉维、马里、墨西哥、蒙古、莫桑比克、缅甸、尼泊尔、尼日尔、尼日利亚、巴基斯坦、巴布亚新几内亚、秘鲁、菲律宾、卢旺达、塞内加尔、塞拉利昂、索马里、南非、斯里兰卡、苏丹、阿拉伯叙利亚共和国、塔吉克斯坦、泰国、多哥、乌干达、坦桑尼亚联合共和国、乌兹别克斯坦、委内瑞拉(玻利瓦尔共和国)、越南、也门、赞比亚和津巴布韦。
2020年人均膳食能量供应量估计数(除上述63个国家之外的国家)和2021年估计数(所有国家)基于粮农组织为“世界粮食形势”提供参考而开展的短期市场前景预测汇编5,用于从食物平衡表系列中最新可获数据的年份开始,临近预测2020年和2021年每个国家的膳食能量消费量。
变异系数(CV):若具有全国代表性的家庭调查能够提供可靠的食物消费数据,则可以直接估计收入变异系数(CV|y)。自本报告上一版以来,对以下15国家的18项新调查进行了处理,以更新CV|y:科特迪瓦(2018年)、埃塞俄比亚(2019年)、伊拉克(2018年)、吉尔吉斯斯坦(2018年)、马拉维(2019年)、马里(2018年),缅甸(2017年)、尼日尔(2018年)、菲律宾(2018年)、塞内加尔(2018年)、斯里兰卡(2016、2019年)、多哥(2018年)、乌干达(2018年)、坦桑尼亚联合共和国(2001、2007、2017年)和瓦努阿图(2019年)。共计有60个国家的118项调查,CV|y估计值是基于国家调查得出。
对于没有合适调查数据的年份,则采用粮农组织2014年以来收集的粮食不安全体验分级数据,基于平滑处理的重度粮食不安全趋势(三年移动平均值),预测CV|y从2015年(或上次食物消费调查年份,若该年份时间更近)到2019年的变化。估计运用的假设是,使用粮食不安全体验分级表测量的重度粮食不安全状况近期变化能够密切反映食物不足发生率的潜在变化。鉴于食物不足发生率的变化无法通过平均食物供应量的观察变化或估计变化完全解释,因此此种变化可归结于CV|y在最近年份可能出现的一些潜在变化。对食物不足发生率历史估计数的分析表明,平均来看,在控制了膳食能量消费量和最低膳食能量需求量的差异后,CV|y就能解释各时段和各地区约三分之一的食物不足发生率差异。因此,对于每个已有粮食不安全体验分级数据的国家,就可以估计2015年之后或最近调查年份之后CV|y的变化,因为重度粮食不安全发生率每个观察到的百分点变化中,就有三分之一个食物不足发生率百分点是来自于CV|y的变化。对于所有其他国家,CV|y保持不变,均为2017年估计值。与去年报告一样,2020年和2021年(食物获取受到COVID-19疫情严峻影响)CV|y的临近预测需要进行特殊处理(见附件2A)。
在粮农组织的食物不足发生率参数法中,体重和生活方式差异相关的变异系数(即需求变异系数CV|r)反映的是代表健康人群的假设普通个体的膳食能量需求分布变异性,也等于假设普通个体在所属人群营养充足情况下的膳食能量摄入量分布变异系数。若假设普通个体的膳食能量需求量呈正态分布,那么就可以通过任意两个已知百分位数估计出标准差。我们用最低膳食能量需求量和平均膳食能量需求量(ADER)来粗略估计第1个和第50个百分位数,399,400随后通过最低膳食能量需求量和平均膳食能量需求量之间差值的逆累积标准正态分布推导得出CV|r值。
CV|y和CV|r的几何平均值即是总变异系数:
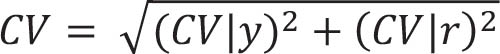
挑战和局限:从正规意义上讲,食物不足状态适用于个体;但由于可以获得的数据通常都是较大尺度,故无法准确地鉴别出特定群体中哪些个体面临实际的食物不足问题。通过上述统计模型,只有在可获得代表性样本的人群或群体中,才能计算出指标结果。因此,食物不足发生率仅为人群中处于此种状况的个体所占比例,无法进一步细分。
由于推断的概率性质和与模型参数估计相关的不确定性,食物不足发生率估计结果的准确度通常较低。食物不足发生率估计结果误差率虽无法准确计算,但在大多数情况下都可能超过5%。因此,粮农组织认为估计结果低于2.5%的食物不足发生率数据不够可靠,也未加以报告。
参考文献:
FAO. 1996. Methodology for assessing food inadequacy in developing countries. In FAO. The Sixth World Food Survey, pp. 114–143. Rome.
FAO. 2003. Proceedings: Measurement and Assessment of Food Deprivation and Undernutrition: International Scientific Symposium. Rome.
FAO. 2014. Advances in hunger measurement: traditional FAO methods and recent innovations. FAO Statistics Division Working Paper No. 14–04. Rome.
Naiken, L. 2002. Keynote paper: FAO methodology for estimating the prevalence of undernourishment. Paper presented at the Measurement and Assessment of Food Deprivation and Undernutrition International Scientific Symposium, Rome, 26–28 June 2002. Rome, FAO.
Wanner, N., Cafiero, C., Troubat, N. & Conforti, P. 2014. Refinements to the FAO methodology for estimating the prevalence of undernourishment indicator. Rome, FAO.
用粮食不安全体验分级表衡量的粮食不安全发生率
定义:本指标所衡量的粮食不安全是指:个人或家庭由于缺乏资金或其他资源而导致的粮食获取受限。粮食不安全的严重程度使用了通过“粮食不安全体验分级表调查模块”(FIES-SM)收集的数据加以衡量。该模块有8个问题,要求受调者自我报告通常与粮食获取受限有关的状况和体验。为每年监测可持续发展目标实现情况,问题涉及调查前12个月的情况。
采用基于Rasch测量模型的复杂统计技术,从调查中收集到的数据经过内部一致性验证后,转换成从低到高的严重程度等级量化值。之后,根据对“粮食不安全体验分级表调查模块”问题的答复,为全国代表性人口调查中访问的个人或家庭分配一个划入三个等级其中之一的概率,分别为:(1)粮食安全或仅有轻度粮食不安全;(2)中度粮食不安全;(3)重度粮食不安全(由两个全球设定的阈值界定)。根据2014-2016年三年间收集的“粮食不安全体验分级表”数据,粮农组织制定了“粮食不安全体验分级表”参考量表,作为基于体验的粮食不安全衡量方法的全球标准,并设定了两个严重程度参考阈值。
可持续发展目标指标2.1.2是属于中度和重度粮食不安全两类中其中一类的累积概率。另一项指标(FIsev)则仅考虑重度粮食不安全一类计算得出。
报告方式:在本报告中,粮农组织提供了两个不同严重程度的粮食不安全估计数:中度或重度粮食不安全(FImod+sev);重度粮食不安全(FIsev)。每种严重程度都报告了两个估计数:
- 总人口中所在家庭至少一位成人处于粮食不安全状态的个体比例(百分比);
- 总人口中所在家庭至少一位成人处于粮食不安全状态的个体估计数。
数据来源:自2014年以来,由8个问题组成的“粮食不安全体验分级表调查模块”已在盖洛普世界民意调查所包括的140多个国家(覆盖90%的世界人口)开展,调查对象为具有全国代表性的成人(定义为15岁或以上)样本。2021年,访谈采用了电话和当面结合的形式。鉴于COVID-19疫情期间当面收集数据极引发群体传播风险较高,因此在2020年已采用电话访谈的部分国家仍保留了此种模式。通过评价双框架覆盖方法(即固定电话和移动电话访谈加在一起覆盖的成人比例),以计算机辅助电话访谈的形式,将覆盖率至少达到70%的国家纳入了2020年世界民意调查。
一直以来,盖洛普调查在北美洲、西欧、亚洲部分地区以及海湾阿拉伯国家合作委员会国家采用的是电话调查。在中东欧、拉美多数地区、亚洲几乎所有国家以及近东和非洲,通过区域框架设计组织了面对面访谈。
在多数国家,人群样本数约为1000人,印度(3000人)、中国大陆(3500人)和俄罗斯联邦(2000人)样本数更大一些。
2021年,除盖洛普世界民意调查以外,粮农组织还通过Geopoll®公司和Kantar®公司在20个国家收集数据,具体目标是填补粮食获取方面的数据缺口。涉及国家如下:安提瓜和巴布达、巴哈马、巴巴多斯、科摩罗、刚果民主共和国、吉布提、多米尼克、斯威士兰、几内亚比绍、海地、老挝人民民主共和国、马达加斯加、马尔代夫、尼日尔、卢旺达、圣基茨和尼维斯、圣多美和普林西比、苏里南、特立尼达和多巴哥以及赞比亚。
在阿富汗、安哥拉、亚美尼亚、伯利兹、贝宁、博茨瓦纳、布基纳法索、佛得角、加拿大、乍得、智利、哥斯达黎加、科特迪瓦、多米尼加共和国、厄瓜多尔、斐济、加纳、希腊、格林纳达、几内亚比绍、洪都拉斯、印度尼西亚、以色列、哈萨克斯坦、肯尼亚、基里巴斯、吉尔吉斯斯坦、莱索托、马拉维、墨西哥、纳米比亚、尼日尔、尼日利亚、巴基斯坦、巴勒斯坦、巴拉圭、菲律宾、大韩民国、俄罗斯联邦、圣基茨和尼维斯、圣卢西亚、圣文森特和格林纳丁斯、萨摩亚、塞内加尔、塞舌尔、塞拉利昂、南非、南苏丹、斯里兰卡、苏丹、多哥、汤加、乌干达、阿联酋、坦桑尼亚联合共和国、美国、瓦努阿图、越南和赞比亚,采用了政府调查数据,利用粮农组织的统计方法,按照相同的全球参考标准对国家结果进行调整,然后估计出粮食不安全发生率,这些国家约占世界人口的四分之一。在可获得国家数据的年份,将相关国家纳入考虑。对于其余年份,采用了如下策略:
- 若可获得一年以上的国家数据,则采用线性插值法将缺失年份的数据补充进来。
- 若仅能获得一年的数据,则采用以下方法处理缺失年份:
- –若与国家调查具有可比性,则使用粮农组织数据;
- –若国家数据不可比,则使用粮农组织数据呈现的趋势进行估计;
- –若无其他可用数据,则使用次区域趋势进行估计;
- 考虑到支撑趋势的各类实证(例如贫困、极端贫困、就业和食品价格上涨等因素的发展动态),若次区域数据无法计算,或其他调查或次区域趋势不适用于特定国家情境,则考虑保持国家调查水平不变。
方法:对数据进行验证后,通过Rasch模型构建出粮食不安全严重程度分级表。该模型假定观察到受调者i对问题j做出肯定回答的概率是严重程度分级表上受调者所在位置(ai)与项目(bj)所在位置之间距离的逻辑函数。
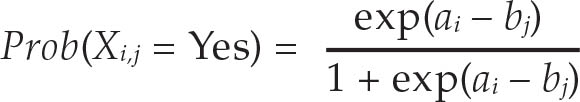
通过将Rasch模型应用于“粮食不安全体验分级表”数据,可以估计出每个受调者 i 在每个粮食不安全严重程度 L(中度或重度,或重度)上粮食不安全的概率(pi,L),其中0 < p i,L < 1。
人口中每种严重程度(FIL)的粮食不安全发生率以样本中所有受调者(i)的粮食不安全概率的加权求和计算得出:
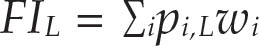
其中 wi 是分层后的权重,表示样本中每条记录所代表的个人或家庭在全国人口中的比例。
由于盖洛普世界民意调查只对15岁或以上个人进行抽样调查,因此从这些数据中直接得出的发生率估计数仅适用于15岁及以上的人口。为了得出人口中(所有年龄组)粮食不安全发生率和人数,需要对家庭中估计至少有一个成人处于粮食不安全状态的人数进行估计。这就需要采用“饥饿者之声”技术报告附件II详细介绍的多步骤程序(见下文“参考文献”中的链接)。
中度或重度以及重度粮食不安全的区域和全球合计数FIL,r的计算公式如下:
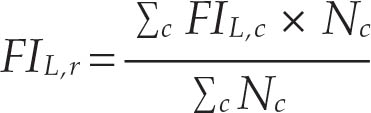
其中r表示区域,FIL,c 是该区域c 国在L级的FI估计数,Nc是相应的人口规模。若一国缺乏FIL的估计数,则假定FIL等于同一区域其余国家估计数的人口加权平均值。只有当有估计数的国家至少占该区域人口的50%时,才会生成区域合计数。
我们根据“粮食不安全体验分级表”全球标准分级表(以2014-2016年间盖洛普世界民意调查涵盖的所有国家的结果为基础确立的一系列项目参数值)确定了通用阈值,并按照当地分级表将其转换成对应数值。对照“粮食不安全体验分级表”全球标准校准每个国家分级表的过程可称为“等同法”,有助于针对个体受调者制定具有国际可比性的粮食不安全严重程度衡量标准以及可比的国家发生率。
问题在于,如果被视为一项隐性特性,那么粮食不安全严重程度在评估时就缺乏绝对参考标准。Rasch模型有助于找出各个条目在分级表上的相对位置,称为逻辑单位,但“零”值为主观设置,通常等于严重程度的估计平均数。这意味着每次应用时,分级表上的零值都会发生变化。为了生成不同时间、不同人群之间的可比数值,就必须确立通用的分级表作为参考标准,同时找到所需的公式,便于在不同分级法之间进行换算。就像在不同温度计量标准(如摄氏和华氏)之间相互换算一样,这个过程需要确定几个“锚”点。在粮食不安全体验分级法中,这些锚点就是与各项相关的严重程度,它们在分级表上的相对位置可以被等同为相对应项目在全球参考分级表上的位置。这样,通过找到公式将共同项严重程度的平均数和标准差(SD)相互等同,就能将一个分级表上的数值“映射”到另一个上。
挑战和局限:当粮食不安全发生率估计数以盖洛普世界民意调查中收集的“粮食不安全体验分级表”数据为基础,且大多数国家的样本量约为1000时,置信区间很少高于测得发生率的20%(即发生率为50%时,误差范围最大为正负5%)。然而,当估计国家发生率时采用更大的样本量,或估计几个国家的合计数时,置信区间就可能小很多。为减少年际抽样方法变化带来的影响,国家层面的估计数以三年平均值表示,由所涉及三年中所有年份的平均值计算而来。
参考文献:
Gallup. 2020. Gallup Keeps Listening to the World Amid the Pandemic. In: Gallup. Cited 25 May 2021. https://news.gallup.com/opinion/gallup/316016/gallup-keeps-listening-world-amid-pandemic.aspx
FAO. 2016. Methods for estimating comparable rates of food insecurity experienced by adults throughout the world. Rome. www.fao.org/3/a-i4830e.pdf
FAO. 2018. Voices of the Hungry. In: FAO. Rome. Cited 28 April 2020. www.fao.org/in-action/voices-of-the-hungry
五岁以下儿童发育迟缓、消瘦和超重
发育迟缓的定义(五岁以下儿童):年龄(月龄)别身高/身长(厘米)低于世卫组织儿童生长发育标准中位数2个标准差。年龄别身高较低表明出生后甚至出生前曾受营养不足和感染的累积影响,可能是长期营养不足、反复感染以及水和卫生基础设施不足所致。
报告方式:比世卫组织儿童生长发育标准年龄别身高中位数低2个标准差的0-59月龄儿童比例。
消瘦的定义:身高/身长(厘米)别体重(公斤)低于世卫组织儿童生长发育标准中位数2个标准差。身高别体重较低表明体重显著下降或体重增加不足,可能是食物摄入不足和/或传染病(特别是腹泻)发病所致。
报告方式:比世卫组织儿童生长发育标准身高别体重中位数低2个标准差的0-59个月龄儿童比例。
超重的定义:身高/身长(厘米)别体重(公斤)高于世卫组织儿童生长发育标准中位数2个标准差。这一指标反映出身高别体重增加过度,一般是能量摄入超过儿童能量需求所致。
报告方式:比世卫组织儿童生长发育标准身高别体重中位数高2个标准差的0-59个月龄儿童比例。
数据来源:联合国儿童基金会、世卫组织和世界银行。2021。《联合国儿童基金会、世界卫生组织和世界银行集团儿童营养不良联合估计 — 水平和趋势》(2021年版)。2022年4月6日引用。https://data.unicef.org/resources/jme-report-2021、www.who.int/data/gho/data/themes/topics/joint-child-malnutrition-estimates-unicef-who-wb、https://datatopics.worldbank.org/child-malnutrition
方法:
国家层面估计数
《联合国儿童基金会、世界卫生组织和世界银行集团儿童营养不良联合估计》国家数据集
《联合国儿童基金会、世界卫生组织和世界银行集团儿童营养不良联合估计》国家数据集要求收集包含儿童营养不良信息的国家数据源,即五岁以下儿童身高、体重和年龄数据,用于估计各国的发育迟缓、消瘦和超重发生率。这些国家层面数据源主要为家庭调查(例如多指标类集调查及人口和健康调查)。如人口覆盖率高,也可包含一些行政数据(例如监测系统)。截至最近一次审核的结束日期,即2021年1月31日,一手数据集包含了157个国家和领地的997个数据源,近80%的儿童所在国家过去五年至少有一个发育迟缓、消瘦和超重数据点。这表明,全球估计数可广泛代表近期全球大多数儿童的状况。该数据集包含点估计(及相关标准误差)、95%置信区间和未加权样本量。在可以获得微观数据的条件下,“营养不良联合估计”采用根据全球标准定义重新计算的估计数。如没有微观数据,则采用报告估计数,但以下三种情况下需作调整以符合规范:(1)采用2006年世卫组织儿童生长发育标准作为替代生长发育参照标准;(2)年龄段中不包含完整的0-59月龄年龄组;(3)仅代表农村人口的国家数据来源。数据来源汇总、微观数据重新分析和数据源审核详情参见报告其他部分。401
《营养不良联合估计》国家数据集中不同指标用途各异。就消瘦而言,“营养不良联合估计”国家数据集被用作国家估计数(也就是说,《营养不良联合估计》国家数据集中某年某国家庭调查得出的消瘦发生率就是该年该国报告的消瘦发生率)。就发育迟缓和超重而言,《营养不良联合估计》国家数据集被用于生成国家建模估计数,作为正式的《营养不良联合估计》数据(也就是说,某年某国家庭调查得出的发育迟缓发生率不作为该年该国报告的发育迟缓发生率,而是作为下文将要介绍的建模估计数的参考)。
国家层面发育迟缓和超重估计模型
统计模型技术细节参见报告其他部分。401简而言之,就发育迟缓和超重而言,采用加入一个异质性误差项的惩罚纵向混合模型,对发生率模型取对数,得到分对数(对数几率)。模型的质量根据平衡模型复杂性与观测数据拟合性的模型拟合标准进行量化。这一拟用方法具有一些重要特点,包括非线性时间趋势、区域趋势、国别趋势、协变量数据和异质性误差项。所有具备数据的国家均为估计总体时间趋势及协变量数据对发生率的影响提供了数据。就超重而言,协变量数据包含线性和社会人口指数的平方项(SDI)ap及数据来源类型。估计发育迟缓时采用的是同样的协变量,以及前五年卫生体系平均可及性作为额外的协变量。
2021年,对至少有1个数据点(例如家庭调查)纳入上述“营养不良联合估计”国家数据集的155个国家,《营养不良联合估计》发布了2000-2020年间aq各国发育迟缓和超重年度建模估计数。此外,还发布了另外49个国家的国家建模估计数,但仅用于计算区域和全球合计数。这49个国家的建模估计数不予列示,因为《营养不良联合估计》国家数据集不包括这些国家的家庭调查,或在发布之时,建模估计数仍未通过最终审核。这204个国家的结果可用于计算任何国家组别的合计估计数和不确定度区间。不确定度区间对监测趋势至关重要,而对于数据稀少以及一手数据来源出现较大抽样误差的国家来说,尤其如此。如某项调查仅获得少量近期数据,那么它被加入到估计中后,可能引起预期轨迹的大幅变化。为此,从慎重角度出发,要采用不确定度区间来加强趋势的可解读性。新的《营养不良联合估计》方法采用的不确定度区间已通过多种数据类型进行了测试和验证。
区域和全球估计数
区域和全球消瘦估计数仅列示了最近年份即2020年的数据,但发育迟缓和超重估计数则列示了2000-2020年时间序列数据。ar这是因为《营养不良联合估计》是基于国家层面的发生率数据,这些数据源自大多数国家很少收集(每三到五年收集一次)的横截面调查(即某个时间点概况)数据。一个历年内发育迟缓和超重发生率相对较稳定,因此可用这些数据跟踪这两种状况的长期变化,而消瘦则是一种可能经常和快速改变的急症。一个历年内,一名儿童可能出现不止一次消瘦状况(即康复后可能于同年内复发),而很多情况下,季节变化也可能增加消瘦风险,以致发生率出现季节性激升。例如,某些情况下,从收获后(往往粮食供应充足,天气条件不容易引发疾病)到收获前(通常缺粮,会出现可能影响营养状况的大雨和相关疾病),消瘦发生率可能升高一倍。鉴于任何季节都能开展国家调查,因此调查估计的发生率可能忽高忽低;如果数据收集工作持续多个季节,则有可能不高不低。因此,消瘦发生率反映的是特定时间点而不是一整年的消瘦状况。由于调查结果因季节而异,因此难以据此推导趋势。缺少能体现季节性和偶发消瘦状况的方法,正是《营养不良联合估计》无法呈现这种形式营养不良年度趋势的主要原因。
生成区域和全球估计数
区域和全球发育迟缓和超重估计方法与消瘦估计方法不同,详见下文。简而言之,新的国家层面模型得出的结果被用于生成发育迟缓和超重的区域和全球估计数,而“营养不良联合估计”的次区域多层次模型则用于生成区域和全球消瘦估计数。
发育迟缓和超重
计算2000-2020年as间各年份全球和区域估计数时,采用204个国家的建模估计数,取联合国《世界人口展望》2019年修订版398统计的各国五岁以下人口加权得出的各国平均数。其中155个国家的国家数据源(例如家庭调查)纳入了上述“营养不良联合估计”国家数据集。另外49个国家生成的建模估计数用于计算区域和全球合计数,但其国家建模估计数不予列示,因为“营养不良联合估计”国家数据集未包括这些国家的家庭调查,或在发布之时,建模估计数尚未通过最终审核。置信区间采用自举法生成。
消瘦
上文介绍“营养不良联合估计”国家数据集时提及的来自国家数据来源的消瘦发生率数据被用于编制2020年at区域和全球估计数,其中使用的是“营养不良联合估计”次区域多层次模型,并采用联合国《世界人口展望》2019年修订版统计的五岁以下儿童人口权重。398
挑战和局限:各国针对发育迟缓、超重和消瘦的推荐报告周期是每三到五年,但一些国家报告数据的频率较低。尽管已经尽力提高各国各时期统计数据之间的可比性,但国家数据在数据收集方法、人口覆盖率和所用估计方法方面仍可能存在差异。由于抽样误差和非抽样误差(技术测量误差、记录误差等),调查估计数也存在不同程度的不确定性。国家或区域和全球层面在得出估计数时,均未充分考虑到以上两类误差中的任何一类。
从消瘦发生率来看,由于调查通常在一年里的特定时段进行,因此估计数可能受季节性影响。与消瘦相关的季节性因素包括粮食可供量(如收获前时期)和疾病(雨季和腹泻、疟疾等),而自然灾害和冲突也会导致趋势出现实质性变化,应与季节性变化区分对待。长期来看,各国不同年份的消瘦估计数可能不一定具有可比性。因此,本报告仅提供最近年份(2020年)au的估计数。
参考文献:
de Onis, M., Blössner, M., Borghi, E., Morris, R. & Frongillo, E.A. 2004. Methodology for estimating regional and global trends of child malnutrition. International Journal of Epidemiology, 33(6): 1260–1270. https://doi.org/10.1093/ije/dyh202
GBD 2019 Risk Factors Collaborators. 2020. Global burden of 87 risk factors in 204 countries and territories, 1990–2019: a systematic analysis for the Global Burden of Disease Study 2019. The Lancet, 396(10258): 1223–1249. https://doi.org/10.1016/s0140-6736(20)30752-2
UNICEF, WHO & World Bank. 2021. UNICEF-WHO-World Bank: Joint child malnutrition estimates - Levels and trends (2021 edition). Cited 6 April 2022. https://data.unicef.org/resources/jme-report-2021, www.who.int/data/gho/data/themes/topics/joint-child-malnutrition-estimates-unicef-who-wb, https://datatopics.worldbank.org/child-malnutrition
UNICEF, WHO & World Bank. 2021. Technical notes from the background document for country consultations on the 2021 edition of the UNICEF-WHO-World Bank Joint Malnutrition Estimates. SDG Indicators 2.2.1 on stunting, 2.2.2a on wasting and 2.2.2b on overweight. New York, USA, UNICEF. data.unicef.org/resources/jme-2021-country-consultations
WHO. 2014. Comprehensive Implementation Plan on maternal, infant and young child nutrition. Geneva, Switzerland. www.who.int/nutrition/publications/CIP_document/en
WHO. 2019. Nutrition Landscape Information System (NLIS) country profile indicators: interpretation guide. Geneva, Switzerland. www.who.int/publications/i/item/9789241516952
纯母乳喂养
定义:六月龄以下婴儿纯母乳喂养的定义是婴儿只接受母乳喂养,不摄入其他食物或饮料,甚至水。纯母乳喂养是儿童生存的基石,也是新生儿的最佳喂养方式,因为母乳能为婴儿建立微生物菌群,增强免疫系统,降低慢性病风险。
母乳喂养还对母亲有利,可预防产后出血,促进子宫恢复,降低缺铁性贫血和各类癌症风险,促进心理健康。
报告方式:调查前24小时内纯母乳喂养,未喂食其他食物或饮料(甚至水)的0-5月龄婴儿比例。402
数据来源:联合国儿童基金会。2021。婴幼儿喂养。引自:联合国儿童基金会。美国纽约。[2022年4月6日引用]。data.unicef.org/topic/nutrition/infant-and-young-child-feeding
方法:

该指标包括由乳母喂养和泵吸母乳喂养。
该指标基于0-5月龄婴儿前一天喂养回忆情况的截面数据。
2012年,利用2005-2012年间每个国家的最新估计数生成了纯母乳喂养的区域和全球估计数。同样,利用2014-2020年间每个国家的最新估计数生成了2020年估计数。全球和区域估计数按每个国家纯母乳喂养率的加权平均数计算,采用了《世界人口展望》2019年修订版398(2012年为基线,2020年为当前)提供的新生儿总数作为权数。除非另有说明,否则仅在现有数据能够代表相应区域新生儿总数至少50%的情况下才提供估计数。
挑战和局限:虽然有很大比例的国家收集了纯母乳喂养数据,但高收入国家尤其缺乏数据。纯母乳喂养的推荐报告周期是每三到五年;但是,一些国家报告数据的频率较低,这意味着喂养方式的变化往往在几年之后仍未被察觉。
区域和全球平均数可能会受到影响,具体取决于哪些国家在本报告所涉时期有数据。
采用前一天的喂养情况作为计算基础可能会导致高估纯母乳喂养婴儿的比例,因为有些不定期被喂食其他液体或食物的婴儿可能在调查前一天未被喂食这些液体或食物。
参考文献:
UNICEF. 2021. Infant and young child feeding: exclusive breastfeeding. In: UNICEF. New York, USA. Cited 6 April 2022. data.unicef.org/topic/nutrition/infant-and-young-child-feeding
WHO. 2014. Comprehensive Implementation Plan on maternal, infant and young child nutrition. Geneva, Switzerland. www.who.int/nutrition/publications/CIP_document/en
WHO. 2019. Nutrition Landscape Information System (NLIS) country profile indicators: interpretation guide. Geneva, Switzerland. www.who.int/publications/i/item/9789241516952
WHO & UNICEF. 2021. Indicators for assessing infant and young child feeding practices: definitions and measurement methods. https://apps.who.int/iris/rest/bitstreams/1341846/retrieve
低出生体重
定义:低出生体重指无论胎龄大小,出生体重低于2500克(低于5.51磅)。新生儿出生时的体重是衡量孕妇及胎儿健康和营养的一项重要指标。403
报告方式:出生时体重低于2500克(低于5.51磅)的新生儿比例。
数据来源:联合国儿童基金会和世卫组织。2019。《联合国儿童基金会、世界卫生组织低出生体重联合估计》。引自:联合国儿童基金会。美国纽约和瑞士日内瓦。[2020年4月28日引用]。www.unicef.org/reports/UNICEF-WHO-low-birthweight-estimates-2019、www.who.int/nutrition/publications/UNICEF-WHO-lowbirthweight-estimates-2019
方法:具有全国代表性的低出生体重发生率估计数可从一系列来源获得,这些来源大致可定义为国家行政数据或具有代表性的家庭调查。国家行政数据来自国家系统,包括民事登记和生命统计(CRVS)系统、国家卫生管理信息系统(HMIS)和出生登记处。国家家庭调查包含出生体重信息以及关键的相关指标,包括产妇对婴儿出生时体型大小的看法(多指标类集调查、人口和健康调查)。这些信息也是低出生体重数据的重要来源,在许多出生未称重和/或数据堆积的情况下尤其如此。在录入国家数据集之前,要对数据的覆盖面和质量进行审核,如果数据来源是家庭调查,则要进行调整。行政数据归类如下:(1)若活产儿比例≥90%,则为高覆盖率;(2)若活产儿比例在80%-90%之间,则为中覆盖率;(3)若活产儿比例<80%,则不予纳入。调查数据若要纳入数据集,需要满足以下条件:
- 数据集中至少有30%的样本标明出生体重;
- 数据集中至少有200个出生体重数据;
- 没有严重的数据堆积现象,这意味着:a)≤55%的出生体重数据属于最常见的三类出生体重(即如果3000克、3500克、2500克是最常见的三类出生体重,那么它们在数据集中的合计占比不得超过所有出生体重数据的55%);b)出生体重≥4500克的婴儿数量占比≤10%;c)出生体重小于500克或大于5000克的婴儿数量占比≤5%;
- 对缺失的出生体重和数据堆积进行了调整。12
本研究采用建模方法处理那些已经过验收的(对家庭调查数据而言,已经过验收并调整)国家数据,生成了2000-2015年间国家年度估计数,相关方法因输入数据的齐备程度及类别而异,具体如下:
- b-spline曲线:利用b-spline曲线回归法对那些高覆盖率行政数据中具有8个或以上数据点(2005年之前有1个或以上、2010年后新增1个或以上)的国家数据进行平滑处理,生成低出生体重年度估计数。采用b-spline曲线回归模型来预测国家层面低出生体重估计数的标准误差,并计算其95%置信区间。这些低出生体重估计数与本国行政报告中的数据十分接近。
- 分层回归:对不符合采用b-spline曲线法条件,但具备任一来源1个或以上低出生体重数据点、符合纳入标准的国家数据,则采用协变量模型生成低体重年度估计数,同时采用自举法得出不确定度区间。该模型中包括新生儿死亡率自然对数;低体重儿童比例(年龄别体重的z分数比参考人群年龄别体重中位数低2个标准差);数据类型(高质量行政数据、低质量行政数据、家庭调查);联合国区域(如南亚、加勒比地区);国别随机效应。这些低出生体重估计数可能与国家行政和调查报告中的估计数相差甚远,尤其是因为家庭调查估计数已因出生体重数据缺失和堆积的问题经过调整,而调查报告往往只包含具有出生体重数据的儿童的低出生体重估计数,未针对数据堆积做任何调整。
- 无估计数:数据库中有些国家没有低出生体重输入数据和/或不符合录入标准,则标示为“无估计数”。在目前的国家数据库中共有54个国家被标示为“无估计数”。尽管没有提供这54个国家的估计数,但利用上文详述的分层回归方法得出了这些国家的年度低出生体重估计数,仅用于纳入区域和全球估计数。
建模后的国家年度估计数被用于生成2000-2015年间区域和全球估计数。全球估计数为在联合国每年区域分组中具备估计数的195个av国家中出生体重低于2500克的活产儿估计数的总和,除以这195个国家每年所有活产儿人数得到的结果。区域估计数则以每个区域分组中的国家为基础,通过类似的方法得出。为获取全球和区域层面不确定性估计数,我们采用b-spline曲线法(从采用计算标准误绘制的正态分布图中随机抽样)或者分层回归法(采用自举法)为每个国家估计出每年低出生体重1000份样本的点估计数。1000份样本中每份的国家低出生体重估计数在全球或区域层面相加,将分布结果的第2.5个和第97.5个百分位数作为置信区间。
挑战和局限:监测全球低出生体重状况时,一项主要局限就是很多儿童的出生体重数据缺失。未称重婴儿存在着极大偏差,那些较贫困、受教育水平较低、生活在农村的母亲所生的婴儿与较富裕、受教育水平较高、生活在城市的母亲所生的婴儿相比,更不可能具备出生体重数据。13由于未称重婴儿的各种特征都是造成低出生体重的风险因素,因此未充分代表这些婴儿的估计数可能低于真实数值。此外,大多数中等偏下收入国家13现有数据质量不高,在500克或100克倍数上存在过度堆积问题,也使低出生体重估计数存在更大偏差。当前数据库404中用于处理出生体重数据缺失和调查估计数堆积问题的方法,本意是解决问题;但实际上有54个国家根本无法生成可靠的出生体重估计数。此外,由于约半数建模国家每次进行自举法预测时都会随机产生国别效应,其中有正有负,区域和全球估计数的置信区间可能被人为设置得过小,导致区域和全球层面的相对不确定性往往低于单个国家层面的不确定性。
参考文献:
Blanc, A. & Wardlaw, T. 2005. Monitoring low birth weight: An evaluation of international estimates and an updated estimation procedure. Bulletin World Health Organization, 83(3): 178–185.
Blencowe, H., Krasevec, J., de Onis, M., Black, R.E., An, X., Stevens, G.A., Borghi, E., Hayashi, C., Estevez, D., Cegolon, L., Shiekh, S., Ponce Hardy, V., Lawn, J.E. & Cousens, S. 2019. National, regional, and worldwide estimates of low birthweight in 2015, with trends from 2000: a systematic analysis. The Lancet Global Health, 7(7): e849–e860.
成人肥胖
定义:体重指数(BMI)≥30.0kg/m2。体重指数指体重与身高之比,通常用于成人营养状况分类,由体重(公斤)除以身高(米)的平方(kg/m2)计算得出。体重指数大于或等于30 kg/m2的人即为肥胖。
报告方式:按年龄标准化并按性别加权,体重指数≥30.0kg/m2的18岁以上人口的比例406。
数据来源:世卫组织。2020。全球卫生观察站(GHO)数据库。引自:世卫组织。瑞士日内瓦。[2020年4月28日引用]。apps.who.int/gho/data/node.main.A900A?lang=en(在186个国家进行了1698项基于人口的研究,参与者年龄均在18岁或以上,总数超过1920万人)。407
方法:选定部分基于人口的研究应用贝叶斯分层模型;选定研究测量18岁及以上成人身高和体重,旨在估计1975-2014年间平均体重指数趋势和体重指数各类别(低体重、超重和肥胖)发生率的趋势。模型纳入了非线性时间趋势和年龄分布;全国与地方/社区代表性;并标明了数据仅涵盖农村/城市或是两者均涵盖。模型还纳入了有助于预测体重指数的协变量,包括国民收入、城市人口比例、平均受教育年限以及供人类食用的各类食物可供量综合性指标。
挑战和局限:一些国家的数据来源很少,只有42%的数据来源报告了70岁以上人群的数据。
参考文献:
NCD-RisC (NCD Risk Factor Collaboration). 2016. Trends in adult body-mass index in 200 countries from 1975 to 2014: a pooled analysis of 1698 population-based measurement studies with 19.2 million participants. The Lancet, 387(10026): 1377–1396.
WHO. 2019. Nutrition Landscape Information System (NLIS) country profile indicators: interpretation guide. Geneva, Switzerland. www.who.int/publications/i/item/9789241516952
15-49岁女性贫血
定义:考虑海拔和吸烟因素,血红蛋白浓度低于120g/L(非孕期和哺乳期妇女)和低于110g/L(孕妇)的15-49岁女性比例。
报告方式:15-49岁育龄妇女中血红蛋白浓度低于110g/L的孕妇和低于120g/L的非孕妇所占比例。
数据来源:
世卫组织。2021。维生素和矿物质营养信息系统(VMNIS)。引自:世卫组织。瑞士日内瓦。[2021年5月25日引用]。www.who.int/teams/nutrition-food-safety/databases/vitamin-and-mineral-nutrition-information-system
世卫组织。2021。《全球贫血估计》2021年版。引自:世卫组织和全球卫生观察站数据库。瑞士日内瓦。[2021年5月25日引用]。www.who.int/data/gho/data/indicators/indicator-details/GHO/prevalence-of-anaemia-in-women-of-reproductive-age-(-)
方法:数据来源首选人口调查。数据取自世卫组织“维生素和矿物质营养信息系统”的微量营养素数据库。该数据库汇总各种其他来源的人口微量营养素状况数据,包括从科学文献中收集的数据以及通过世卫组织各区域和国家办事处、各联合国组织、各国卫生部、各研究和学术机构、各非政府组织等合作方收集的数据。此外,匿名化个体数据取自多国调查,包括人口和健康调查、多指标类集调查、生殖健康调查和疟疾指标调查。
2021年版15-49岁女性贫血发生率估计数按妊娠状况分列,包含了1995-2020年间489个数据来源。血液中血红蛋白浓度数据尽可能根据海拔和吸烟情况进行了调整。已排除生物学上不合理的血红蛋白值(低于25g/L或高于200g/L)。采用贝叶斯分层混合模型估计血红蛋白分布,并系统解决数据缺失、非线性时间趋势和数据来源代表性的问题。简而言之,该模型计算每个国家每个年份的估计数,参考的是对应国家对应年份的数据,以及对应国家和其他具有相近时期数据的国家(尤其是同区域国家)其他年份的数据。数据不存在或不充分的情况下,该模型尽量借用数据,但对于数据丰富的国家和区域,则尽量不借用数据。如此得出的估计数还参考了有助于预测血液中血红蛋白浓度的协变量(例如社会人口指数、肉类供应量[人均千卡]、女性平均体重指数和五岁以下儿童死亡率对数)。408不确定度区间(可信度区间)反映不确定性的主要来源,包括抽样误差、抽样设计/测量问题造成的非抽样误差、无数据情况下对国家和年份估计所致不确定性。
挑战和局限:尽管较高比例的国家公布了关于贫血的全国代表性调查数据,但该指标的报告工作仍然欠缺,尤其是高收入国家。因此,估计数可能无法充分反映出各国和各区域间的差异,在数据稀缺的情况下,估计数可能会“缩小”到接近全球平均值。
参考文献:
Stevens, G.A., Finucane, M.M., De-Regil, L.M., Paciorek, C.J., Flaxman, S.R., Branca, F., Peña-Rosas, J.P., Bhutta, Z.A. & Ezzati, M. 2013. Global, regional, and national trends in haemoglobin concentration and prevalence of total and severe anaemia in children and pregnant and non-pregnant women for 1995–2011: a systematic analysis of population-representative data. The Lancet Global Health, 1(1): e16–e25.
WHO. 2014. Comprehensive Implementation Plan on maternal, infant and young child nutrition. Geneva, Switzerland.
WHO. 2021. Nutrition Landscape Information System (NliS) Country Profile. In: WHO. Geneva, Switzerland. Cited 10 May 2021. www.who.int/data/nutrition/nlis/country-profile
WHO. 2021. Vitamin and Mineral Nutrition Information System (VMNIS). In: WHO. Geneva, Switzerland. Cited 10 May 2021. www.who.int/teams/nutrition-food-safety/databases/vitamin-and-mineral-nutrition-information-system
WHO. 2021. WHO Global Anaemia estimates, 2021 Edition. In: WHO | Global Health Observatory (GHO) data repository. Geneva, Switzerland. Cited 10 May 2021. www.who.int/data/gho/data/themes/topics/anaemia_in_women_and_children

